1.Prosto简介
交互查询引擎:Presto是一款Facebook开源的MPP架构的OLAP查询引擎,可针对不同数据源执行大容量数据集的一款分布式SQL执行引擎,数据量支持GB到PB字节,主要用来处理秒级查询的场景。Presto 本身并不存储数据,,但是可以接入多种数据源,并且支持跨数据源的级联查询,而且基于内存运算,速度很快,实时性高。
Presto是一个开源的==分布式SQL查询引擎==,适用于==交互式查询==,数据量支持GB到PB字节。
Presto的设计和编写完全是为了解决==Facebook==这样规模的商业数据仓库交互式分析和处理速度的问题。
presto简介: 一条Presto查询可以将多个数据源进行合并,可以跨越整个组织进行分析;
presto特点: Presto以分析师的需求作为目标,他们期望响应速度小于1秒到几分钟;
注意:虽然 Presto 可以解析 SQL,但它不是一个标准的数据库。不是 MySQL、Oracle 的代替品,也不能用来处理在线事务(OLTP)
2.Presto的优缺点
# 优点
1)Presto与Hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。2)能够连接多个数据源,跨数据源连表查,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
3)部署也比Hive简单,因为Hive是基于HDFS的,需要先部署HDFS。
# 缺点
1)虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。2)为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
3.个人自用启动服务
个人自用启动服务
cd /export/server/datax–web-2.1.2
cd /export/server/dolphinscheduler/
#psql –h 服务器 –p 端口地址 –d 数据库 -U 用户名
psql –h 127.0.0.1 -p 5432 –d postgres -U postgres或者
psql –h hadoop01 –d postgres -U postgres
#密码:itcast123退出 q
3.Presto的架构
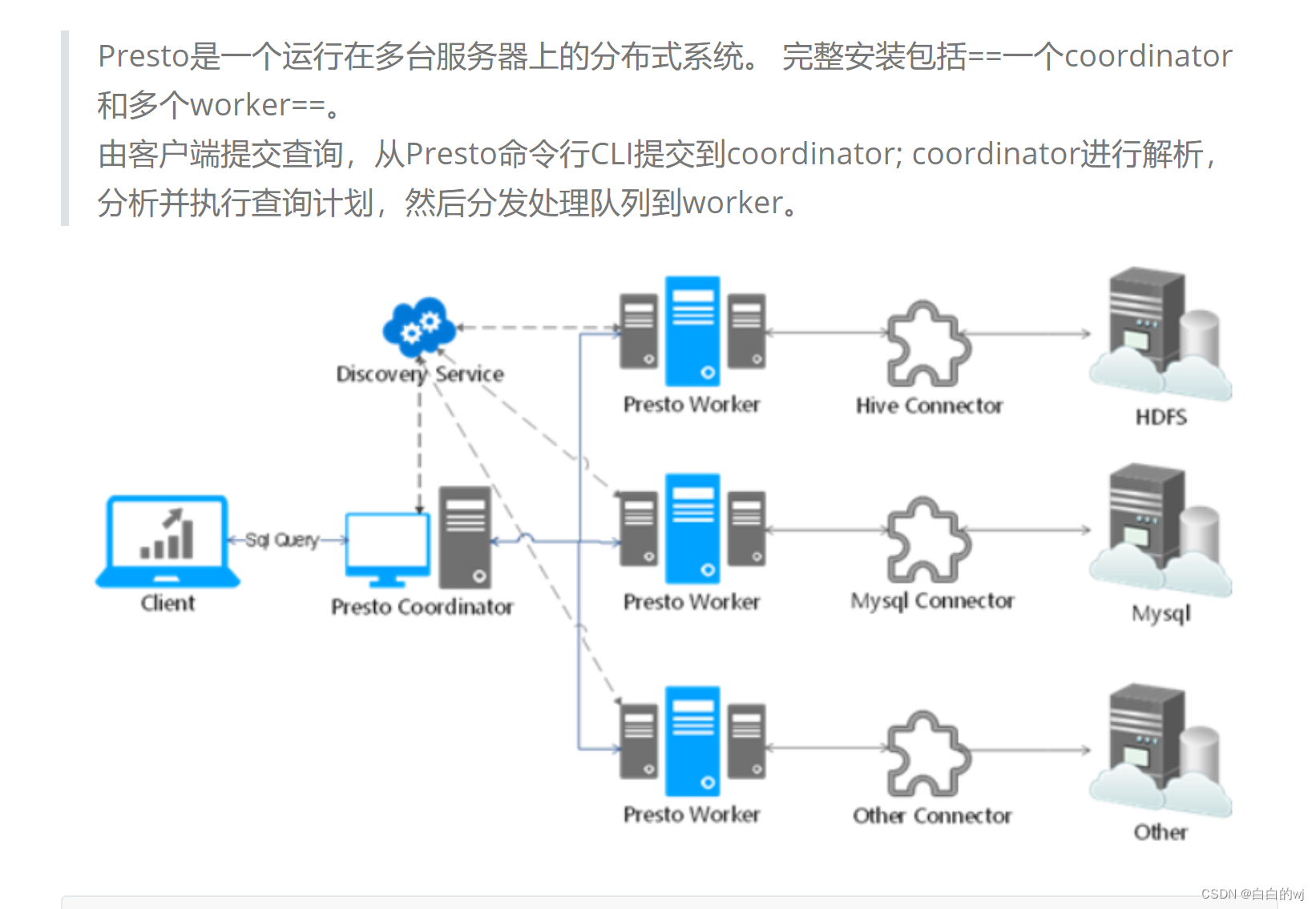
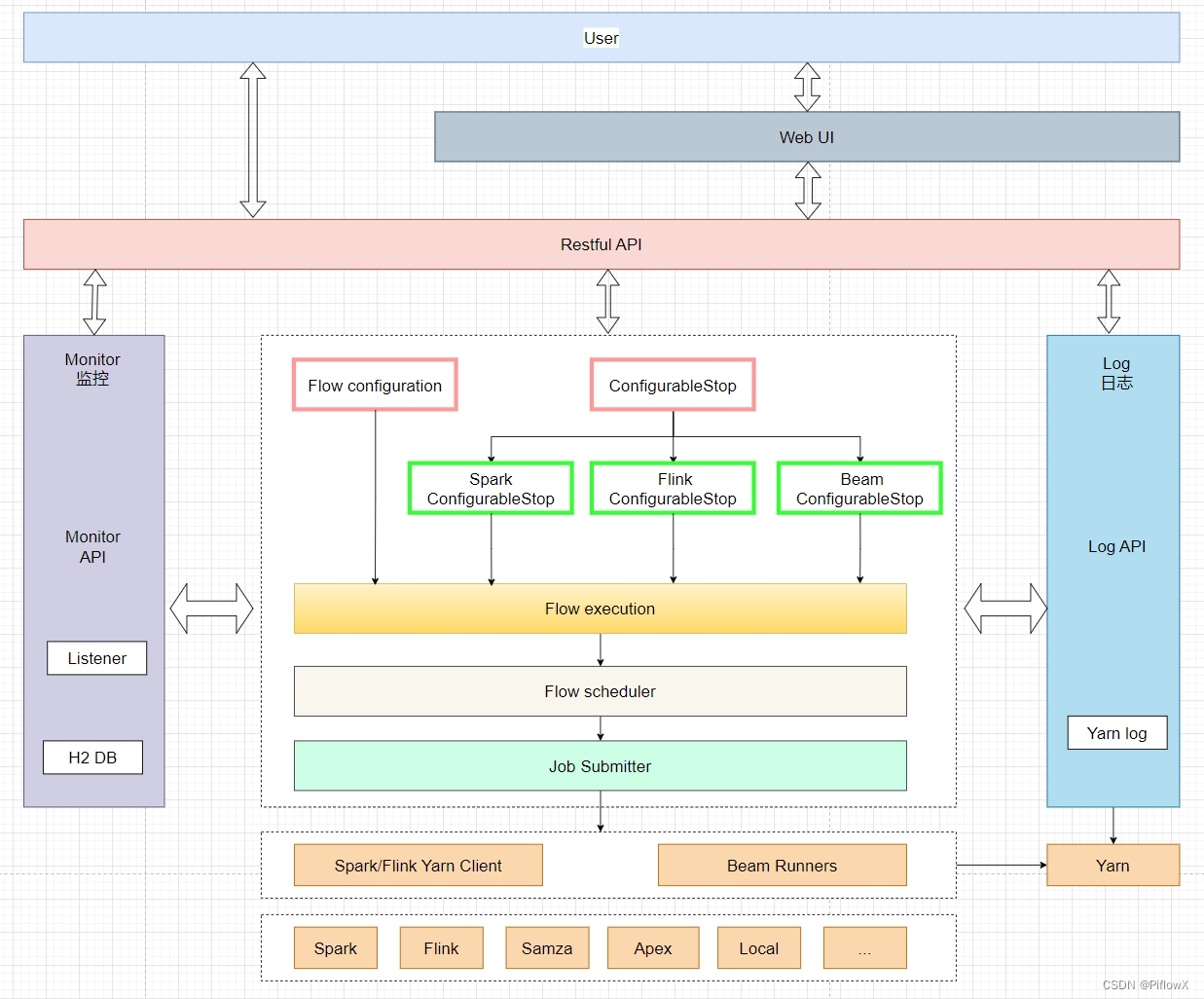
coordinator: 主节点
作用: 负责接收客户端发送的SQL, 对SQL进行编译, 形成执行计划, 根据执行计划, 分发给各个从节点进行执行操作
discovery service: 附属节点
作用: 一般内嵌在主节点中, 主要负责维护从节点列表, 当从节点启动后, 都需要到 discovery 节点进行注册操作
worker节点: 从节点
作用: 负责接收coordinator传递过来任务, 对任务进行具体处理工作(读取数据, 处理数据, 将处理后结果数据返回给coordinator)
1、Presto通过Connector连接器来连接访问不同数据源,例如Hive或mysql。连接器功能类似于数据库的驱动程序。允许Presto使用标准API与资源进行交互。
2、Presto包含几个内置连接器:JMX连接器,可访问内置系统表的System连接器,Hive连接器和旨在提供TPC-H基准数据的TPCH连接器。许多第三方开发人员都贡献了连接器,因此Presto可以访问各种数据源中的数据,比如:ES、Kafka、MongoDB、Redis、Postgre、Druid、Cassandra等。
1、Presto Catalog是数据源schema的上一级,并通过连接器访问数据源。
2、例如,可以配置Hive Catalog以通过Hive Connector连接器提供对Hive信息的访问。
3、在Presto中使用表时,标准表名始终是被支持的。
例如,hive.test_data.test的标准表名将引用hive catalog中test_data schema中的test table。
Catalog需要在Presto的配置文件中进行配置。
Schema是组织表的一种方式。Catalog和Schema共同定义了一组可以查询的表。
当使用Presto访问Hive或关系数据库(例如MySQL)时,Schema会转换为目标数据库中的对应Schema(database)。
= schema通俗理解就是我们所讲的database.
= 想一下在hive中,下面这两个sql是否相等。
show databases; — presto不支持
show schemas;
4.presto和hive的区别
1.一般用presto查询数据,因为快,一般用hive开发数据
2.presto调取表格的方式是
from
a.b.c
hive是from b.c 只需要库.表
3.current_date等日期相关的功能,presto可以用,但这类函数的写法hive往往不通用,hive用的是‘${yesterday}’等。
一些日期的不同,例如我们在presto可以使用
format_datetime(date_add(‘day’,-1,current_date),‘yyyyMMdd’)自动获取昨天的日期,hive是不能用的,hive中可以改为:
date_format(date_add(current_date,-1),‘yyyyMMdd’)
类似的,date_diff 不同版本的presto 和hive也是不同的,具体如下
presto:date_dff(‘day’,date1,date2)
hive : datediff(date1,date2)
5.presto 可以用double,不能用float,presto hive都可以用varchar,但presto不能用string
例如一个字段长度20,presto 用cast(a as varchar(3))能识别出来,但 hive不可以。为了兼容,可以都写为cast(a as varchar(30))
6.新版本的hive 为了安全性,必须要对数据进行分区,要选定etl_dt,presto暂无要求
7.hive 在使用order时候需要配合limit使用,presto无要求
8.presto可以使用group by 1,2,3等简写,hive 是不能识别出来123简写的。
特别要注意的是,在写一些复杂的查询语句时,“as”以前的部分都要group的,不要偷懒只group句子中的一部分
5.presto优化
–1)合理设置分区
与Hive类似,Presto会根据元信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
–2)使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好。
Parquet和ORC一样都支持列式存储,但是Presto对ORC支持更好,而Impala对Parquet支持更好。在数仓设计时,要根据后续可能的查询引擎合理设置数据存储格式。
–3)使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于需要快速解压的,建议采用Snappy压缩。
–4)预先排序
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
6.Presto-内存调优
-
-
==内存池中来实现分配user memory和system memory==。
内存池为常规内存池GENERAL_POOL、预留内存池RESERVED_POOL。

1、GENERAL_POOL:在一般情况下,一个查询执行所需要的user/system内存都是从general pool中分配的,reserved pool在一般情况下是空闲不用的。
2、RESERVED_POOL:大部分时间里是不参与计算的,但是当集群中某个Worker节点的general pool消耗殆尽之后,coordinator会选择集群中内存占用最多的查询,把这个查询分配到reserved pool,这样这个大查询自己可以继续执行,而腾出来的内存也使得其它的查询可以继续执行,从而避免整个系统阻塞。
注意:
reserved pool到底多大呢?这个是没有直接的配置可以设置的,他的大小上限就是集群允许的最大的查询的大小(query.total–max-memory-per–node)。
reserved pool也有缺点,一个是在普通模式下这块内存会被浪费掉了,二是大查询可以用Hive来替代。因此也可以禁用掉reserved pool(experimental.reserved-pool–enabled设置为false),那系统内存耗尽的时候没有reserved pool怎么办呢?它有一个OOM Killer的机制,对于超出内存限制的大查询SQL将会被系统Kill掉,从而避免影响整个presto。 -
内存相关参数
原文地址:https://blog.csdn.net/m0_49956154/article/details/134765789
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_37386.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!