本文介绍: PySpark系列的专栏文章目前的话应该只会比Pandas更多不会更少,可以用PySpark实现的功能太多了,基本上Spark能实现的PySpark都能实现,而且能够实现兼容python其他库,这就给了PySpark极大的使用空间,能够结合大数据集群实现更高效更精确的大数据处理或者预测。如果能够将这些工具都使用的相当熟练的话,那必定是一名优秀的大数据工程师。故2023年这一年的整体学习重心都会集中在这门技术上,当然Pandas以及Numpy的专栏都会更新。
前言
1.cartesian(笛卡尔积计算)
2.coalesce(缩减分区数)
3.cogroup(对Key聚合计算)
4.collect(结果返回列表List)
5.collectAsMap(作为字典返回)
6.combineByKey(Key聚合计算算子)
7.count(统计元素)
8.countApprox(统计计数)
9.countApproxDistinct(返回RDD中不同元素的近似数量)
10.countByKey(计算每个键的元素数)
11.countByValue(将此RDD中每个唯一值的计数作为(value,count)对的字典返回)

12.distinct(返回包含此RDD中不同元素的新RDD)

13.filter( 返回仅包含满足条件的元素的新RDD)

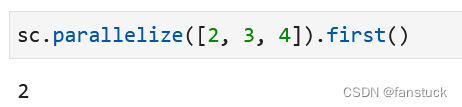
14.first(返回此RDD中的第一个元素)
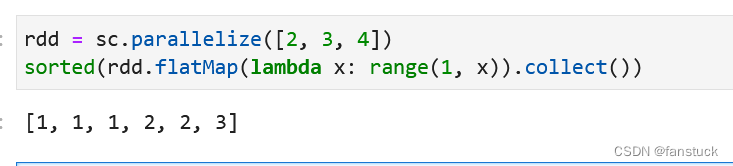
15.flatMap(逐个Map展开返回)
16.flatMapValues(逐个Key Map展开)

17.fold(折叠函数)

18.foldByKey(通过Key折叠)
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




