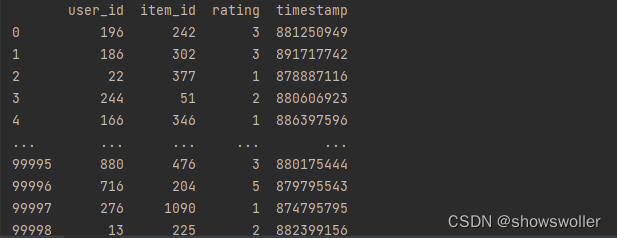
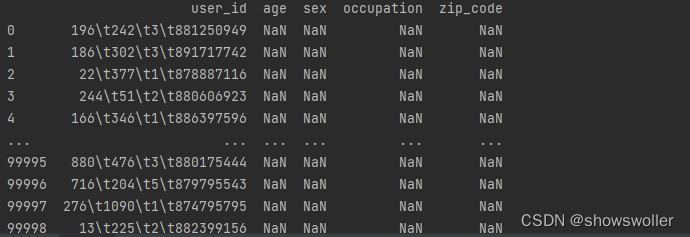
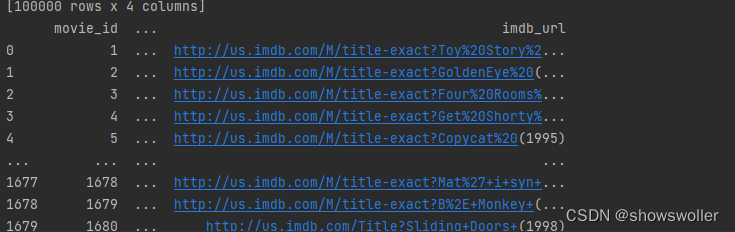
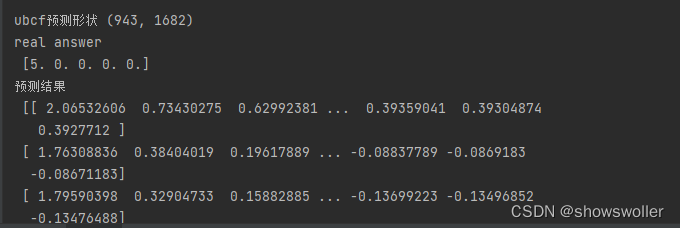
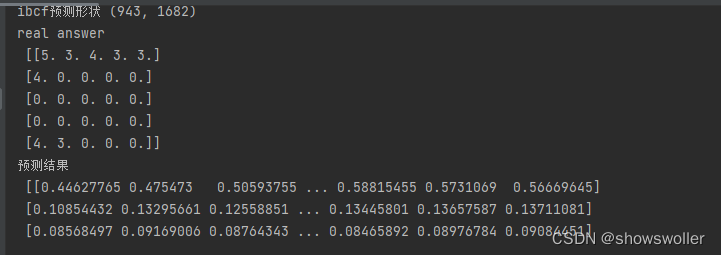
当前位置: 首页python正文 本文介绍: python协同过滤算法实现电影推荐(附源码)包括基于用户的协同过滤和基于物品的协同过滤 数据集请点赞收藏关注后评论区留言并且私信博主要 本例中使用得是著名得电影数据集MovieLens-100数据集 MoviesLens数据集是实现和测试电影推荐最常用得数据集之一,包含943个用户为精选得1682部电影给出得100000个电影评分 主要文件如下1:u.data 2:u.item 3:u.user 1:查看用户/电影排名信息得代码如下 import pandas as pd heads=['user_id','item_id','rating','timestamp'] ratings=pd.read_csv(r'u.data',sep='t',names=heads) print(ratings) print("用户数量",len(ratings)) 2:查看导入的电影数据表 代码如下 import pandas as pd u_cols=['user_id','age','sex','occupation','zip_code'] users=pd.read_csv(r'u.data',sep='|',names=u_cols,encoding='latin-1') print(users) r_cols=['user_id','movie_id','rating','unix_timestamp'] ratings=pd.read_csv(r'u.data',sep='t',names=r_cols,encoding='latin-1') print(ratings) m_cols=['movie_id','title','release_data','video_release_data','imdb_url'] movies=pd.read_csv(r'u.item',sep='|',names=m_cols,usecols=range(5),encoding='latin-1') print(movies) 3:用协同过滤推荐算法进行电影推荐 误差评估如下 全部代码如下 import pandas as pd import numpy as np from sklearn.metrics.pairwise import pairwise_distances np.set_printoptions(suppress=True) # 取消科学计数法输出 pd.set_option('display.max_rows', None) # 展示所有行 pd.set_option('display.max_columns', None) # 展示所有列 def predict(scoredata,similarity,type='user'): #基于物品得推荐 if type=='item': predt_mat=scoredata.dot(similarity)/np.array([np.abs(similarity).sum(axis=1)]) elif type=='user': #计算用户评分值 减少用户评分高低习惯影响 user_meanscorse=scoredata.mean(axis=1) score_diff=(scoredata-user_meanscorse.reshape(-1,1)) predt_mat=user_meanscorse.reshape(-1,1)+similarity.dot(score_diff)/np.array([np.abs(similarity).sum(axis=1)]).T return predt_mat #读取数据 print('step 1 读取数据') r_cols=['user_id','movie_id','rating','unix_timestamp'] scoredata=pd.read_csv(r'u.data',sep='t',names=r_cols,encoding='latin-1') print('数据形状',scoredata.shape) #生成用户-物品评分矩阵 print('step2 生成 用户物品评分矩阵') n_users=943 n_items=1682 data_matrix=np.zeros((n_users,n_items)) for line in range(np.shape(scoredata)[0]): row=scoredata['user_id'][line]-1 col=scoredata['movie_id'][line]-1 score=scoredata['rating'][line] data_matrix[row,col]=score print('用户物品矩阵形状',data_matrix.shape) #计算相似度 print('step3 计算相似度') user_similaritry=pairwise_distances(data_matrix,metric='cosine') item_similarity=pairwise_distances(data_matrix.T,metric='cosine') print('user similarity',user_similaritry.shape) print('item similartity',item_similarity.shape) #进行相似度进行预测 print('step4 预测') user_prediction=predict(data_matrix,user_similaritry,type='user') item_perdiction=predict(data_matrix,item_similarity,type='item') #显示推荐结果 print('step 5 显示推荐结果') print('----------------') print('ubcf预测形状',user_prediction.shape) print('real answern',data_matrix[:5,5]) print('预测结果n',user_prediction) print('ibcf预测形状',item_perdiction.shape) print('real answern',data_matrix[:5,:5]) print('预测结果n',item_perdiction) #性能评估 print('step 6 性能评估') from sklearn.metrics import mean_squared_error from math import sqrt def rmse(predct,realNum): predct=predct[realNum.nonzero()].flatten() realNum=realNum[realNum.nonzero()].flatten() return sqrt(mean_squared_error(predct,realNum)) print('u-base mse=',str(rmse(user_prediction,data_matrix))) print('m-based mse=',str(rmse(item_perdiction,data_matrix))) 数据集请点赞收藏关注后私信博主要 原文地址:https://blog.csdn.net/jiebaoshayebuhui/article/details/126966927 本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若转载,请注明出处:http://www.7code.cn/show_37426.html 如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除! 主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网显示所有内容声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。协同电影过滤 代码007普通 打赏 收藏 海报 链接