本文介绍: 知识蒸馏是深度学习领域的一项重要技术,它通过将大型模型的知识迁移到小型模型来实现模型压缩和性能优化。这一技术在模型部署、效率提升和隐私保护等方面展现出巨大的潜力。随着深度学习技术的不断发展,知识蒸馏在未来将在更多领域发挥重要作用。
1 概况
1.1 定义
知识蒸馏(Knowledge Distillation)是一种深度学习技术,旨在将一个复杂模型(通常称为“教师模型”)的知识转移到一个更简单、更小的模型(称为“学生模型”)中。这一技术由Hinton等人在2015年提出,主要用于提高模型的效率和可部署性,同时保持或接近教师模型的性能。
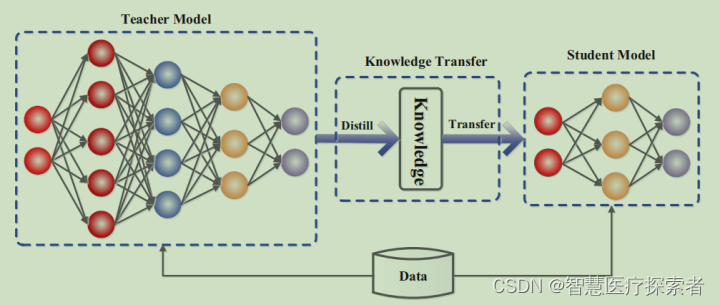
1.2 理论基础
1.3 技术实现
1.4 实施步骤
知识蒸馏是一种将大型、复杂模型(教师模型)的知识迁移到小型、更高效模型(学生模型)的技术。这一过程主要涉及训练两个模型,并通过特定的方式传递知识。以下是实施知识蒸馏的主要步骤:
预训练大型模型: 选择或训练一个大型的、性能良好的模型作为教师模型。这个模型通常是深度网络,拥有较高的准确率。
构建小型模型: 设计一个结构更简单、参数更少的学生模型。学生模型的目标是在保持较小规模的同时,尽可能模仿教师模型的输出。
使用相同的数据集: 通常使用与训练教师模型相同的数据集来训练学生模型。
2 应用场景
2.1 模型压缩和加速
2.2 实时应用
2.3 资源节约
2.4 教育和研究
2.5 医疗影像处理
2.6 自然语言处理
2.7 自动驾驶和机器人技术
2.8 边缘计算
3 优势与挑战
3.1 优势
3.2 挑战
4 总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






