1、前言
- 编写一个可以分类蚂蚁和蜜蜂图片的模型,使用数据集对卷积神经网络进行训练。训练后的模型可以对蚂蚁或蜜蜂的图片进行检测。
- 使用anaconda新建一个虚拟环境,安装好pytorch。后续缺什么包就安装什么包即可。
- 使用pycharm新建一个项目,配置好环境。
2、数据集介绍

3、获取数据
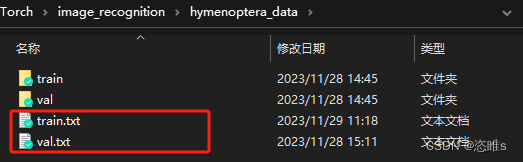
- 代码中获取数据集使用的是txt文件,所以首先需要提取全部图片的地址和标签放入txt文件中。
- 下述代码为python提取全部图片地址和标签导出为txt文件的脚本。(自行修改)
-
import os # 导入os模块,用于操作文件路径等操作系统相关功能。 def get_file_name(file_path, output_file, type): # 绝对路径 path_list = os.listdir(file_path) # 列出指定路径下的所有文件和文件夹,并将结果存储在path_list中 with open(output_file, 'a') as file: for filename in path_list: all_file_path = os.path.join(file_path, filename) # 拼接路径 file.write(all_file_path + ' ' + type + 'n') if __name__ == '__main__': ants_file_path = r"D:BaiduNetdiskWorkspacePyTorchimage_recognitionhymenoptera_datatrainants" bees_file_path = r"D:BaiduNetdiskWorkspacePyTorchimage_recognitionhymenoptera_datatrainbees" output_file = r"D:BaiduNetdiskWorkspacePyTorchimage_recognitionhymenoptera_datatrain.txt" get_file_name(ants_file_path, output_file, 'ants') get_file_name(bees_file_path, output_file, 'bees') -
-
- 将全部地址修改为相对地址。
- 最后txt文件的内容如下:
- 新建一个dataset.py文件。
-
# 读取数据 import torch import torchvision.transforms as transforms from PIL import Image # 读取数据类 class MyDataset(torch.utils.data.Dataset): # 继承构建自定义数据集的基类 def __init__(self, datatxt, datatransform): datas = open(datatxt, 'r').readlines() # 按行读取,每行包含图像路径和标签 self.images = [] self.labels = [] self.transform = datatransform for data in datas: item = data.strip().split(' ') # 去除首尾空格并按空格分割 # 分别将图像路径和标签添加到self.images和self.labels列表中 self.images.append(item[0]) # 路径 self.labels.append(item[1]) # 标签 return def __len__(self): return len(self.images) # 获取数据集中的一个样本。接收一个索引item,根据索引获取对应的图像路径和标签 def __getitem__(self, item): imagepath, label = self.images[item], self.labels[item] image = Image.open(imagepath) # 打开图片 return self.transform(image), label # 返回转换后的图像和对应的标签 # 用于测试 if __name__ == '__main__': # 利用txt文件读取图片信息,txt文件包括图片路径和标签 traintxt = './hymenoptera_data/train.txt' valtxt = './hymenoptera_data/val.txt' # 图片转换形式 traindata_transfomer = transforms.Compose([ transforms.ToTensor(), # 转为Tensor格式 transforms.Resize(60), # 调整图像大小,调整为高度或宽度为60像素,另一边按比例调整 transforms.RandomCrop(48), # 裁剪图片,随机裁剪成高度和宽度均为48像素的部分 transforms.RandomHorizontalFlip(), # 随机水平翻转 transforms.RandomRotation(10), # 随机旋转 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行归一化处理。对每个通道执行了均值为0.5、标准差为0.5的归一化操作 ]) valdata_transfomer = transforms.Compose([ transforms.ToTensor(), # 转为Tensor格 transforms.Resize(48), # 调整图像大小,调整为高度或宽度为48像素,另一边按比例调整 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) # 加载数据 traindataset = MyDataset(traintxt, traindata_transfomer) valdataset = MyDataset(valtxt, valdata_transfomer) print("测试集:" + str(traindataset.__len__())) print("训练集:" + str(valdataset.__len__()))
-
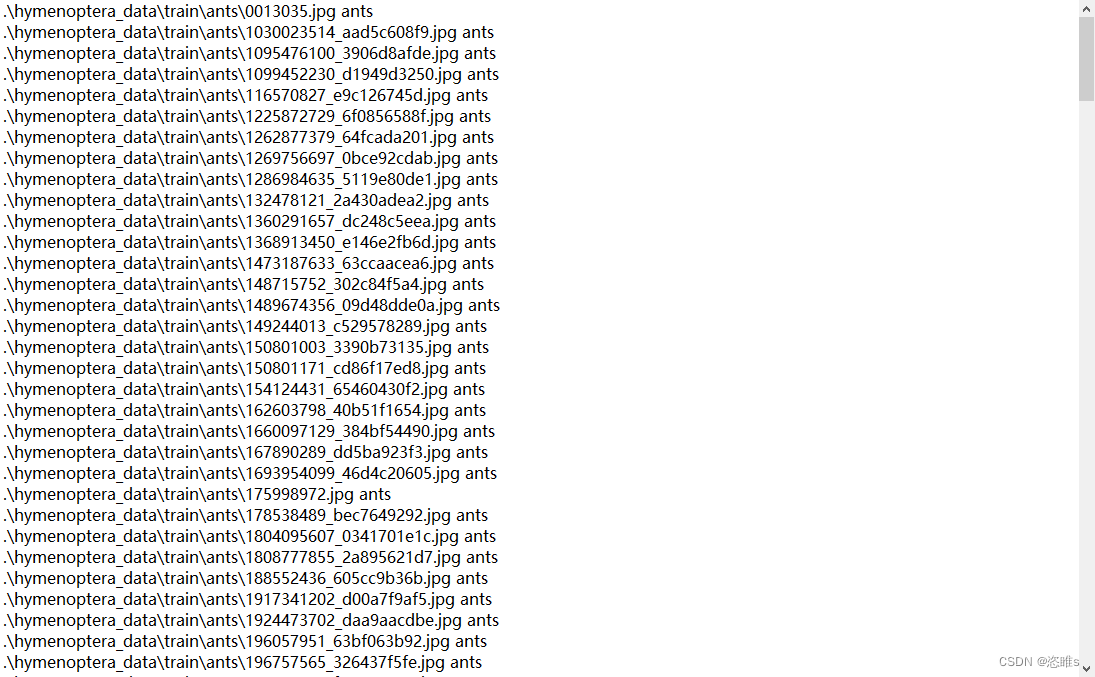
- 单独运行结果:(只用于测试)


4、创建网络
- 新建一个net.py文件。
- 其中创建了一个简单的三层卷积神经网络。
-
# 三层卷积神经网络 import torch # 卷积神经网络类 class SimpleConv3(torch.nn.Module): # 继承创建神经网络的基类 def __init__(self, classes): super(SimpleConv3, self).__init__() # 卷积层 self.conv1 = torch.nn.Conv2d(3, 16, 3, 2, 1) # 输入通道3,输出通道16,3*3的卷积核,步长2,边缘填充1 self.conv2 = torch.nn.Conv2d(16, 32, 3, 2, 1) # 输入通道16,输出通道32,3*3的卷积核,步长2,边缘填充1 self.conv3 = torch.nn.Conv2d(32, 64, 3, 2, 1) # 输入通道32,输出通道64,3*3的卷积核,步长2,边缘填充1 # 全连接层 self.fc1 = torch.nn.Linear(2304, 100) self.fc2 = torch.nn.Linear(100, classes) def forward(self, x): # 第一次卷积 x = torch.nn.functional.relu(self.conv1(x)) # relu为激活函数 # 第二次卷积 x = torch.nn.functional.relu(self.conv2(x)) # 第三次卷积 x = torch.nn.functional.relu(self.conv3(x)) # 展开成一维向量 x = x.view(x.size(0), -1) x = torch.nn.functional.relu(self.fc1(x)) x = self.fc2(x) return x # 用于测试 if __name__ == '__main__': inputs = torch.rand((1, 3, 48, 48)) # 生成一个随机的3通道、48x48大小的张量作为输入 net = SimpleConv3(2) # 二分类 output = net(inputs) print(output)
- 单独运行结果:(只用于测试)

5、训练模型
- 新建一个train.py文件。
- 其中可自行设置的参数都有标出。
-
# 训练模型 import matplotlib matplotlib.use('TkAgg') import matplotlib.pyplot as plt from dataset import MyDataset from net import SimpleConv3 import torch import torchvision.transforms as transforms from torch.optim import SGD # 优化相关 from torch.optim.lr_scheduler import StepLR # 优化相关 from sklearn import preprocessing # 处理label # 图片转换形式 traindata_transfomer = transforms.Compose([ transforms.ToTensor(), # 转为Tensor格式 transforms.Resize(60, antialias=True), # 调整图像大小,调整为高度或宽度为60像素,另一边按比例调整,antialias=True启用了抗锯齿功能 transforms.RandomCrop(48), # 裁剪图片,随机裁剪成高度和宽度均为48像素的部分 transforms.RandomHorizontalFlip(), # 随机水平翻转 transforms.RandomRotation(10), # 随机旋转 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行归一化处理。对每个通道执行了均值为0.5、标准差为0.5的归一化操作 ]) if __name__ == '__main__': traintxt = './hymenoptera_data/train.txt' valtxt = './hymenoptera_data/val.txt' # 加载数据 traindataset = MyDataset(traintxt, traindata_transfomer) # 创建卷积神经网络 net = SimpleConv3(2) # 二分类 # 使用GPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net.to(device) # 测试GPU是否能使用 # print("The device is gpu later?:", next(net.parameters()).is_cuda) # print("The device is gpu,", next(net.parameters()).device) # 将数据提供给模型使用 traindataloader = torch.utils.data.DataLoader(traindataset, batch_size=128, shuffle=True, num_workers=1) # batch_size可以自行调节 # 优化器 optim = SGD(net.parameters(), lr=0.1, momentum=0.9) # 使用随机梯度下降(SGD)作为优化器,学习率0.1,动量0.9,加速梯度下降过程,lr可自行调节 criterion = torch.nn.CrossEntropyLoss() # 使用交叉熵损失作为损失函数 lr_step = StepLR(optim, step_size=200, gamma=0.1) # 学习率调度器,动态调整学习率,每200个epoch调整一次,每次调整缩小为原来的0.1倍,step_size可自行调节 epochs = 5 # 训练次数 accs = [] losss = [] # 训练循环 for epoch in range(0, epochs): batch = 0 running_acc = 0.0 # 精度 running_loss = 0.0 # 损失 for data in traindataloader: batch += 1 imputs, labels = data # 将标签从元组转换为tensor类型 labels = preprocessing.LabelEncoder().fit_transform(labels) labels = torch.as_tensor(labels) # 利用GPU训练模型 imputs = imputs.to(device) labels = labels.to(device) # 将数据输入至网络 output = net(imputs) # 计算损失 loss = criterion(output, labels) # 平均准确率 acc = float(torch.sum(labels == torch.argmax(output, 1))) / len(imputs) # 累加损失和准确率,后面会除以batch running_acc += acc running_loss += loss.data.item() optim.zero_grad() # 清空梯度 loss.backward() # 反向传播 optim.step() # 更新参数 lr_step.step() # 更新优化器的学习率 # 一次训练的精度和损失 running_acc = running_acc / batch running_loss = running_loss / batch accs.append(running_acc) losss.append(running_loss) print('epoch=' + str(epoch) + ' loss=' + str(running_loss) + ' acc=' + str(running_acc)) # 保存模型 torch.save(net, 'model.pth') # 保存模型的权重和结构 x = torch.randn(1, 3, 48, 48).to(device) # # 生成一个随机的3通道、48x48大小的张量作为输入,新建的张量也要送到GPU中 net = torch.load('model.pth') # 从保存的.pth文件中加载模型 net.train(False) # 设置模型为推理模式,意味着不会进行梯度计算或反向传播 torch.onnx.export(net, x, 'model.onnx') # 使用ONNX格式导出模型 # 接受模型net、示例输入x和导出的文件名model.onnx作为参数 # 可视化结果 fig = plt.figure() plot1, = plt.plot(range(len(accs)), accs) # 创建一个图形对象plot1,绘制accs列表中的数据 plot2, = plt.plot(range(len(losss)), losss) # 创建另一个图形对象plot2,绘制losss列表中的数据 plt.ylabel('epoch') # 设置y轴的标签为epoch plt.legend(handles=[plot1, plot2], labels=['acc', 'loss']) # 创建图例,指定图表中不同曲线的标签 plt.show() # 展示所绘制的图表
- 【注】本项目使用的是GPU训练模型。如果GPU可以获得,但是无法使用,可能是pytorch的版本不对,需要重新安装。
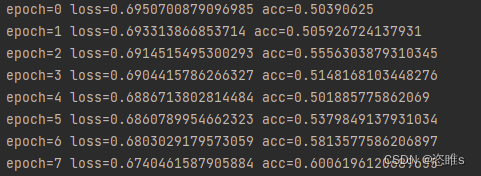
- 运行结果:
- 保存后的模型如下:


6、测试模型
6.1、测试整个模型准确率
- 利用测试集,测试整个模型的准确率。
- 新建一个test.py文件。
-
# 测试整个模型的准确率 import torch import torchvision.transforms as transforms from dataset import MyDataset # 您的数据集类 from sklearn import preprocessing # 处理label # 定义测试集的数据转换形式 valdata_transfomer = transforms.Compose([ transforms.ToTensor(), # 转为Tensor格式 transforms.Resize(60, antialias=True), # 调整图像大小,调整为高度或宽度为60像素,另一边按比例调整,antialias=True启用了抗锯齿功能 transforms.CenterCrop(48), # 中心裁剪图片,裁剪成高度和宽度均为48像素的部分 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像进行归一化处理。对每个通道执行了均值为0.5、标准差为0.5的归一化操作 ]) if __name__ == '__main__': valtxt = './hymenoptera_data/val.txt' # 测试集数据路径 # 加载测试集数据 valdataset = MyDataset(valtxt, valdata_transfomer) # 加载已训练好的模型,利用GPU进行测试 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net = torch.load('model.pth').to(device) net.eval() # 将模型设置为评估模式,意味着不会进行梯度计算或反向传播 # 使用 DataLoader 加载测试集数据 valdataloader = torch.utils.data.DataLoader(valdataset, batch_size=1, shuffle=False) correct = 0 # 被正确预测的样本数 total = 0 # 测试样本数 # 测试模型 with torch.no_grad(): for data in valdataloader: images, labels = data # 将标签从元组转换为tensor类型 labels = preprocessing.LabelEncoder().fit_transform(labels) labels = torch.as_tensor(labels) # 利用GPU训练模型 images, labels = images.to(device), labels.to(device) outputs = net(images) # 输入图像并获取模型预测结果 _, predicted = torch.max(outputs.data, 1) # 获取预测值中最大概率的索引 total += labels.size(0) # 累计测试样本数量 correct += (predicted == labels).sum().item() # 计算正确预测的样本数量 # 计算并输出模型在测试集上的准确率 accuracy = 100 * correct / total print('Test Accuracy: {:.2f}%'.format(accuracy))
-
- 运行结果:

6.2、测试单张图片
- 使用训练后的模型,对单张图片进行预测。
- 新建一个testone.py文件。
-
import torch from PIL import Image import torchvision.transforms as transforms # 定义图片预处理转换 image_transforms = transforms.Compose([ transforms.Resize(60, antialias=True), # 调整图像大小 transforms.CenterCrop(48), # 中心裁剪 transforms.ToTensor(), # 转为Tensor格式 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化处理 ]) # 定义类别映射字典 class_mapping = { 0: "ant", 1: "bee" } # 加载已训练好的模型,利用GPU测试 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") net = torch.load('model.pth').to(device) net.eval() # 将模型设置为评估模式,意味着不会进行梯度计算或反向传播 # 加载要测试的图片 image_path = './hymenoptera_data/val/bees/26589803_5ba7000313.jpg' # 图片路径 input_image = Image.open(image_path) # 加载图片 input_tensor = image_transforms(input_image).unsqueeze(0) # 对图片进行预处理转换,并增加 batch 维度 # 将输入数据移动到GPU上 input_tensor = input_tensor.to(device) # 使用模型进行预测 with torch.no_grad(): output = net(input_tensor) _, predicted = torch.max(output, 1) # 在张量中沿指定维度找到最大值及其对应的索引 # 输出预测结果 predicted_class = predicted.item() # 得到预测的标签 predicted_label = class_mapping[predicted_class] # 将标签转换为文字 print(f"The predicted class for the image is: {predicted_label}")
-
- 运行结果:


原文地址:https://blog.csdn.net/weixin_45100742/article/details/134705597
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_38112.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






