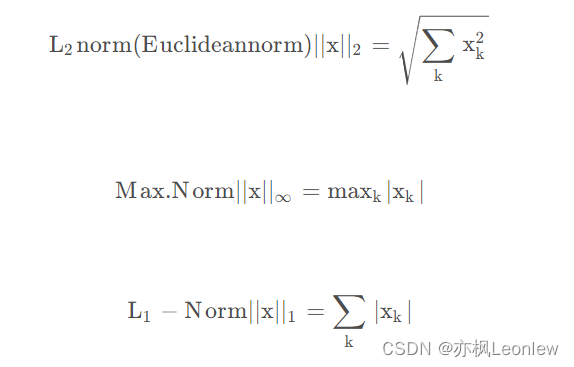张量
Pytorch 是一个深度学习框架,用于开发和训练神经网络模型。
而其核心数据结构,则是张量 Tensor,类似于 Numpy 数组,但是可以支持在 GPU 上加速运算,显著加速模型训练过程,更适用于深度学习和神经网络模型的构建和学习。
此外,后期读者会接触到梯度下降与反向传播,而张量非常重要一点,即可以自动求导,方便计算梯度并更新模型参数。
数据操作
导入
首先,导入 torch,需要注意的是,虽然称为 Pytorch,但是我们应该导入 torch 而不是 Pytorch;
创建张量
获取张量信息
改变张量
张量运算
张量与内存
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。