一、fork()是什么?
fork()是操作系统提供的一个函数,它可以从代码层面(已经存在的进程)上创建一个新的进程。
新的进程为子进程,原进程为父进程。

二、fork返回值问题
1、fork()的两个返回值是什么?
1 #include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 pid_t id=fork();
7 if(id<0)
8 {
9 printf("子进程创建失败n");
10 return 1;
11 }
12 else if( id==0 )
13 {
14 //子进程
15 while(1)
16 {
17 printf("我是子进程:pid: %d,ppid: %dn",getpid(),getppid());
18 sleep(1);
19 }
20 }
21 else
22 {
23 //父进程
24 while(1)
25 {
26 printf("我是父进程:pid: %d,ppid: %dn",getpid(),getppid());
27 sleep(1);
28 }
29 }
30 } 2、fork()为什么有两个返回值?
因为fork()函数内部,return会被执行两次,return的本质就是对id进行写入

3、一个变量为什么会保存两个不同的值?
父子进程各自都有地址空间,页表,用的虚拟地址一样,物理内存是被映射到不同区域的,当任何一方尝试修改数据时,发生了写时拷贝,如果子进程修改数据时,同一个变量经过虚拟地址空间映射,页表写时拷贝,会重新给子进程开辟空间,所以父子进程各自其实在物理内存中,有属于自己的变量空间,只不过在用户层用同一个变量(虚拟地址)来标识。
三、写时拷贝
1、写时拷贝是什么
写时拷贝时多进程创建时,保证父子进程独立性,尤其是数据层面上保证独立性的非常关键的策略,采用写时拷贝技术实现独立性,通过写时拷贝让父子进程数据不在相互干扰,也是一种延迟写入的过程,宏观上提高了整个内存的使用率。
2、为什么要写时拷贝
因为有写时拷贝技术的存在,所以父子进程得以彻底分开,完成了进程独立性的技术保证,
对于数据而言
创建进程的时候,直接拷贝分离,可能拷贝到子进程根本就不会用到的数据空间,即便用到了,也可能只是读取,会造成空间浪费,因此创建子进程时,不需要将不会被访问的,或者只会读取的数据拷贝一份。
什么样的数据值得拷贝?
将来被父或者子进程写入的数据,但是即使是OS,无法知道哪些空间会被写入,即便提前拷贝了,可能并不会立即使用
3、写时拷贝保证了进程的独立性
3、写时拷贝的示意图
fork()之后,子进程构建出来后数据结构以父进程为模板,把父进程相关字段拷贝起来,默认情况下指向的内容是完全一样的,对页表的读写权限为只读权限,如果子进程尝试修改物理内存中的内容,把内存中曾经被大家所共享的内存区域拷贝一份给子进程,修改页表当中的页表项,让子进程的页表指向新空间的地址,数据层面上两个进程实现了分离。任何一个进程尝试修改,都会发生写时拷贝,只读权限去掉了,两个进程已经分开,实现进程独立性。

四、fork()创建子进程时系统做了什么?
fork()创建子进程,本质是系统里多了一个进程,该进程有对应的PCB,对应的地址空间,对应的页表,并将自己进程对应的代码和数据加载到内存,构建映射关系,将该进程PCB放入到运行队列里,等待OS或调度器调度,一旦CPU调度该进程,此时可以通过虚拟地址空间和页表找到该进程的相关代码,然后从上往下执行顺序语句,循环判断,函数跳转,进而在进程内部执行进程内的代码,完成某件事情。
因此fork()执行后,OS会分配新的内存块和内核数据结构给子进程(创建对象),将父进程部分数据结构内容拷贝给子进程(赋值和初始化,子进程的相关数据是以父进程为模板的,包括优先级信息,状态信息),添加子进程到系统进程列表当中(如果无法直接运行,就列入到等待队列,阻塞或者挂起)fork返回,开始调度器调度(fork函数最后return时,子进程已经创建)
五、fork()常规用法
1、一个父进程希望复制自己,使父子进程同时指向不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求
六、fork()函数相关补充
1、创建子进程时,会给子进程分配对于的内核数据结构,这些都是子进程私有的,因为进程具有独立性!理论上,子进程也要有自己的代码和数据,可是一般而言,我们没有加载的过程,也就是说,子进程没有自己的代码和数据。我们知道代码时不可以被写入的,只能读取,数据可能会被修改,必须分离,因此创建子进程时,父子进程代码共享,数据以写时拷贝的方式各自持有一份
2、fork之后,父子进程代码共享是after之后还是所有代码共享?

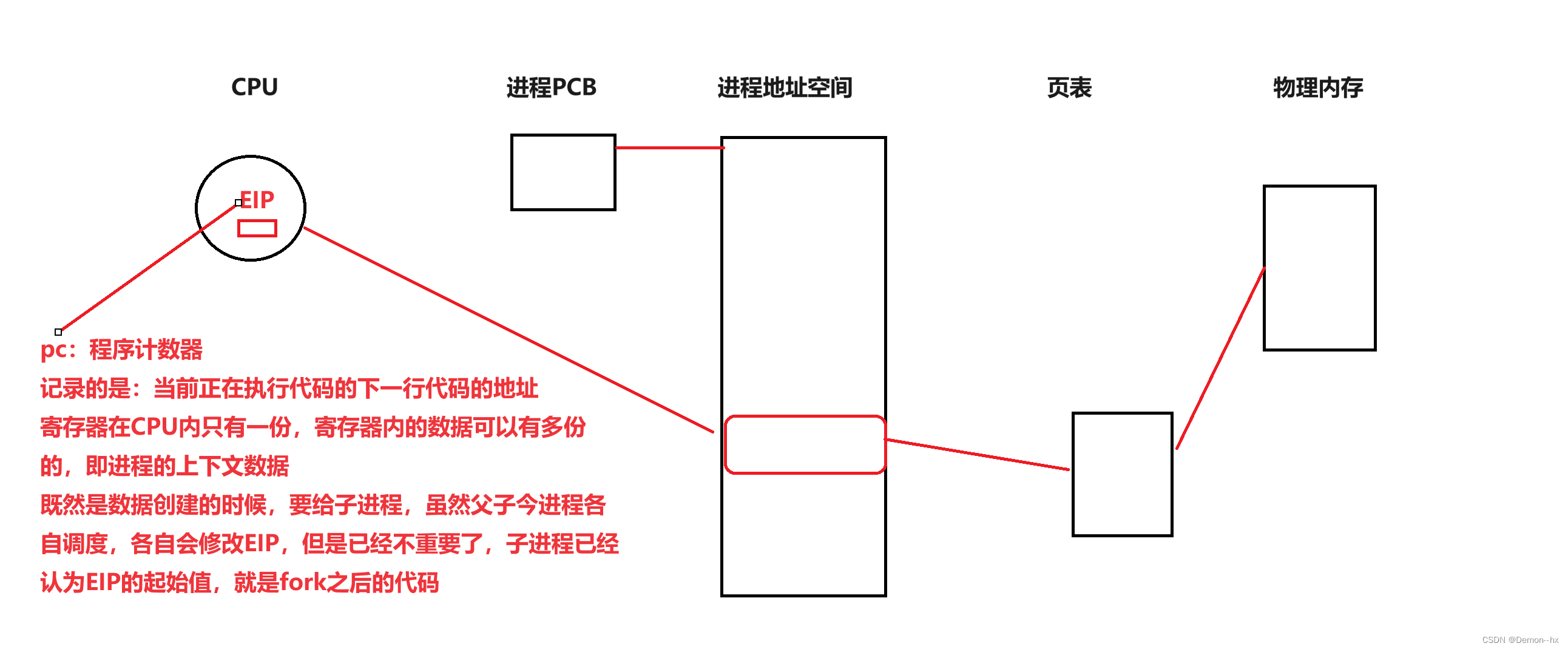
1、我们的代码汇编后,会有很多行代码,每行代码加载到内存之后,都有对应的地址
2、因为进程随时可能被中断(还没执行完)下次回来还必须从之前的位置继续运行,就要求CPU必须记录下来当前进程执行的位置,所有CPU内有对应的寄存器数据,用来记录当前进程的执行位置!
3、寄存器在CPU内只有一份,寄存器内的数据可以有多份的,即进程的上下文数据,既然是数据创建的时候,要给子进程,虽然父子今进程各自调度,各自会修改EIP,但是已经不重要了,子进程已经认为EIP的起始值,就是fork之后的代码,子进程从after之后开始执行,并不代表之前的代码看不到。
七、fork失败的原因?
1、系统中有太多进程
OS系统创建一个进程要做什么?
要创建进程对应的内核数据结构task_struct,还要为该进程创建对应的地址空间mm_struct,还要为该进程创建页表,构建映射关系,并且还要将该进程对应的代码和数据加载到内存。
因此,进程创建本质要消耗内存资源,进程太多,导致系统内存资源不足,不让创建进程。
2、实际用户的进程数超过了限制
1 //fork失败原因
2 //系统内存不足
3 //系统给该用户创建的进程数是有上限的
4
5 //测试系统创建多少个进程数会失败
6 #include<stdio.h>
7 #include<unistd.h>
8 #include<stdlib.h>
9
10 int main()
11 {
12 int max_cnt=0;
13 pid_t id=fork();
14 while(1)
15 {
16
17 if(id<0)
18 {
19 //这个代码是父进程在执行 因为fork创建失败没有子进程执行
20 printf("fork error:man_cnt=%dn",max_cnt);
21 break;
22 }
23 else if(id==0)
24 {
25 //child
26 while(1)
27 {
28 sleep(1);
29 }
30 }
31 else
32 {
33 //father
34 printf("max_cnt:%dn",max_cnt);
35 }
36 max_cnt++;
37 }
38 }
39
40 //max_cnt是父子共享的
41 //但是写时拷贝对父进程是不影响的
42 //写时拷贝改的一直是父进程的
43
44 //子进程一直不退出 fork失败后父进程退出
45 //子进程变成孤儿进程 原文地址:https://blog.csdn.net/weixin_62529445/article/details/134739676
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_38174.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!