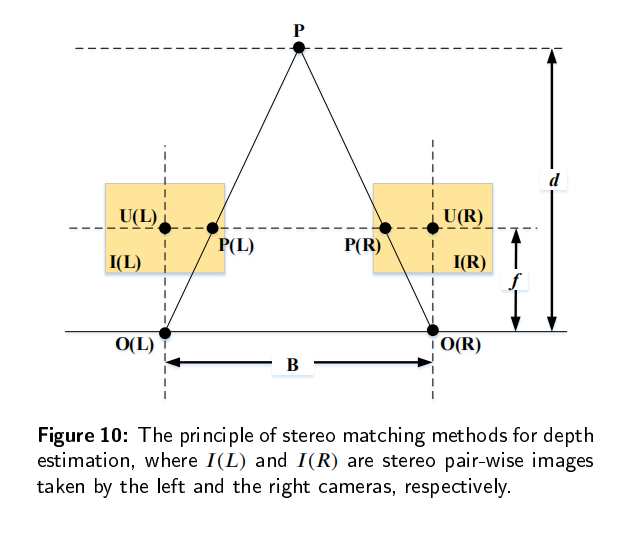
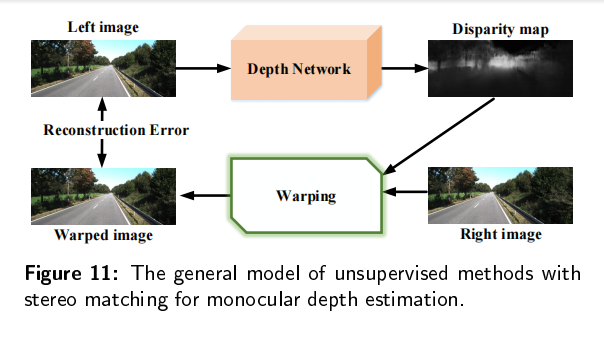
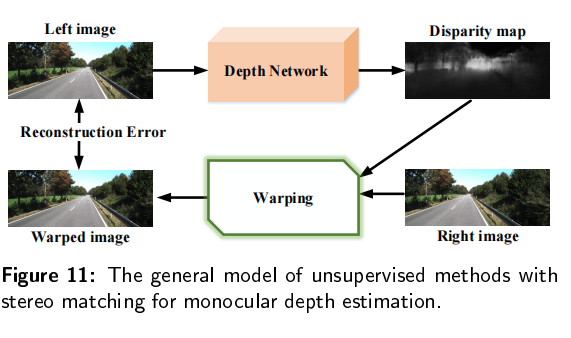
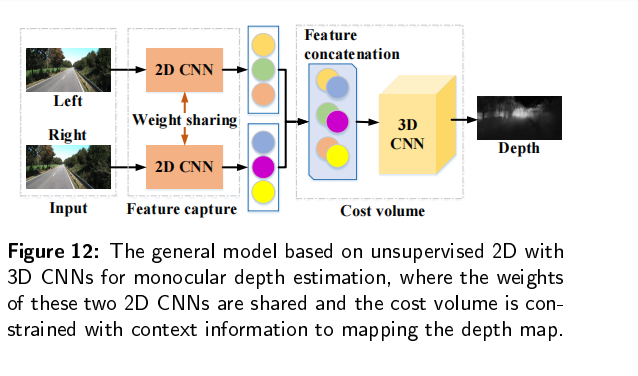
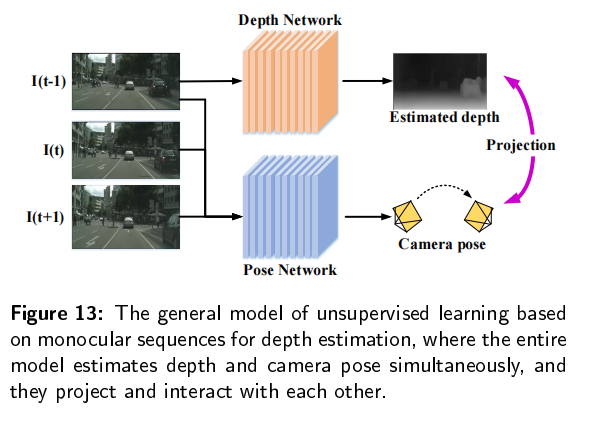
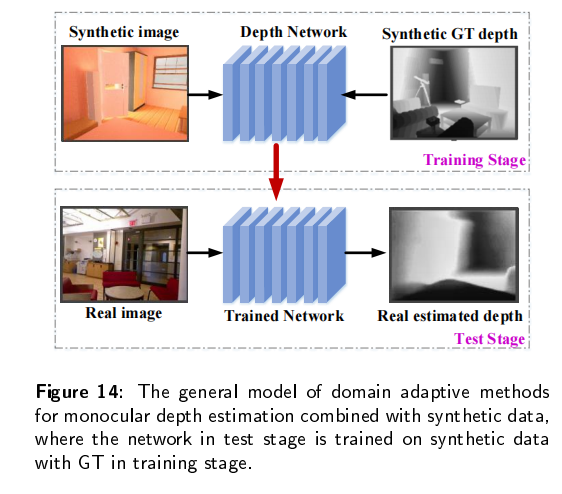
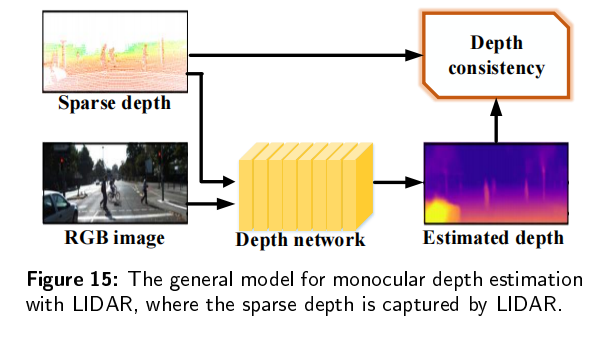
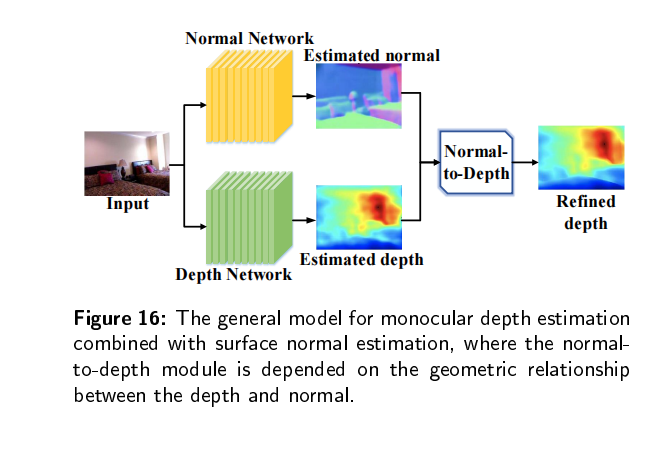
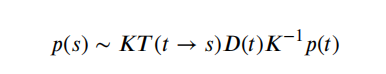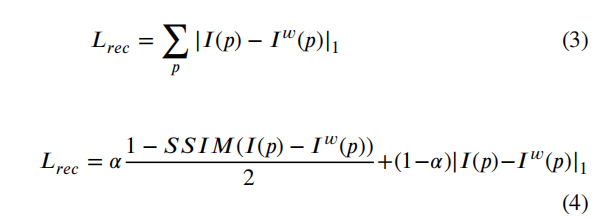传统的深度估计方法通常是使用双目相机,计算两个2D图像的视差,然后通过立体匹配和三角剖分得到深度图。然而,双目深度估计方法至少需要两个固定的摄像机,当场景的纹理较少或者没有纹理的时候,很难从图像中捕捉足够的特征来匹配。所以最近单目深度估计发展的越来越快,但是由于单目图像缺乏可靠的立体视觉关系,因此在三维空间中回归深度本质上是一种不适定问题。
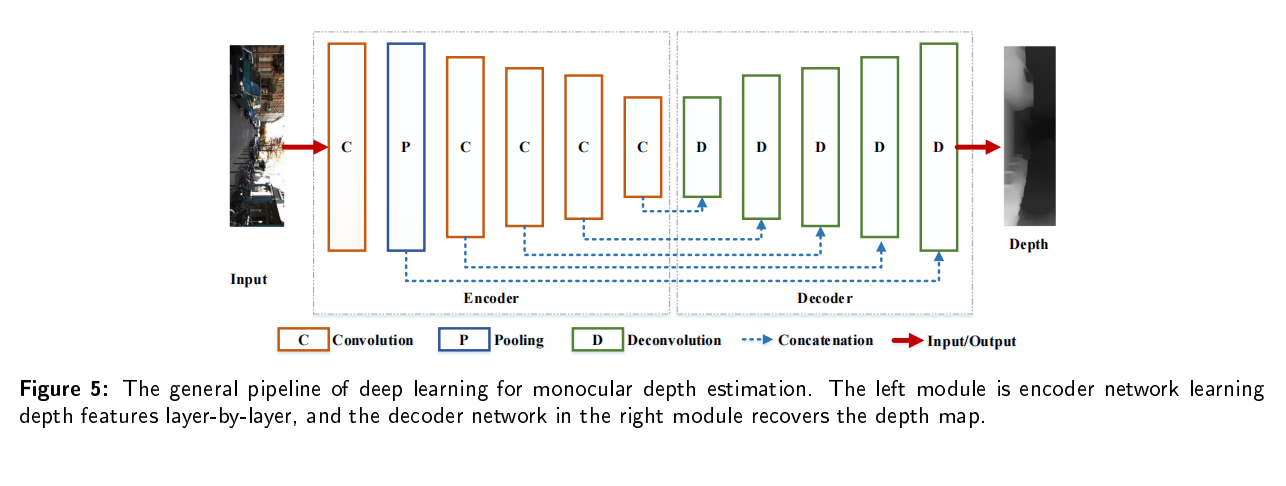
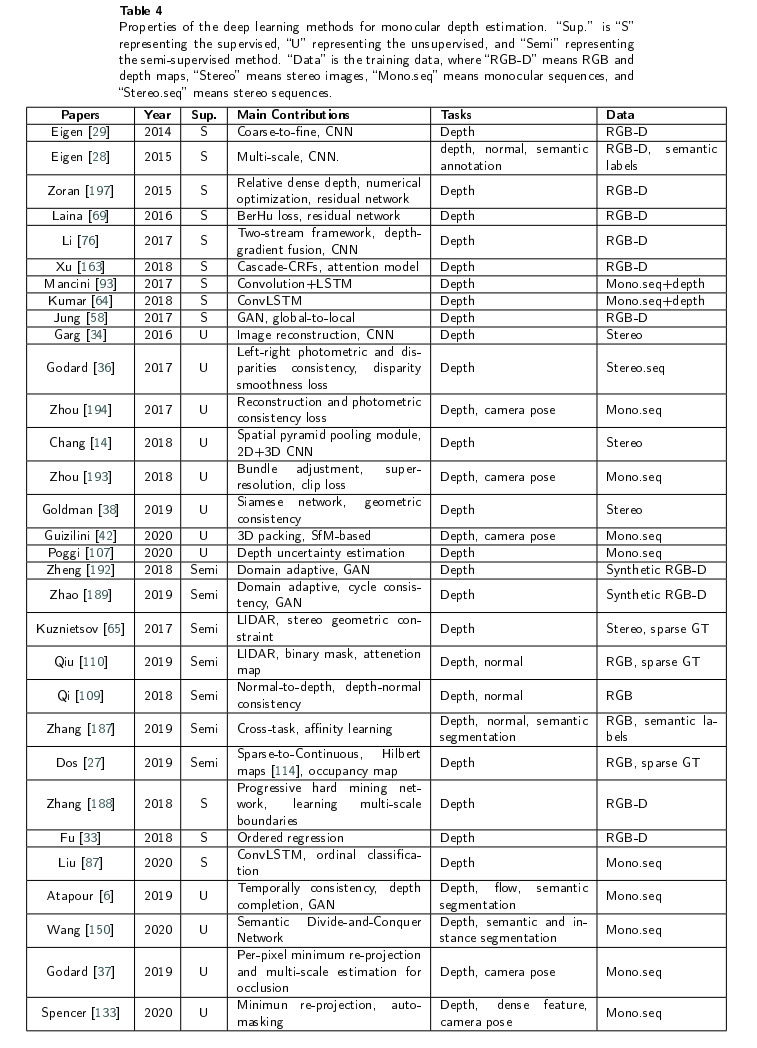
单目图像采用二维形式来重新反射三维世界,然而,有一维场景叫做深度丢失了,导致无法判断物体的大小和距离,也不能判断物体是否被其它物体遮挡,所以,我们需要恢复单目图像的深度。基于深度图,我们可以判断物体大小和距离,以满足场景理解的需要。当估计的深度图能够反应场景的三维结构的时候,我们认为深度估计是有效的。
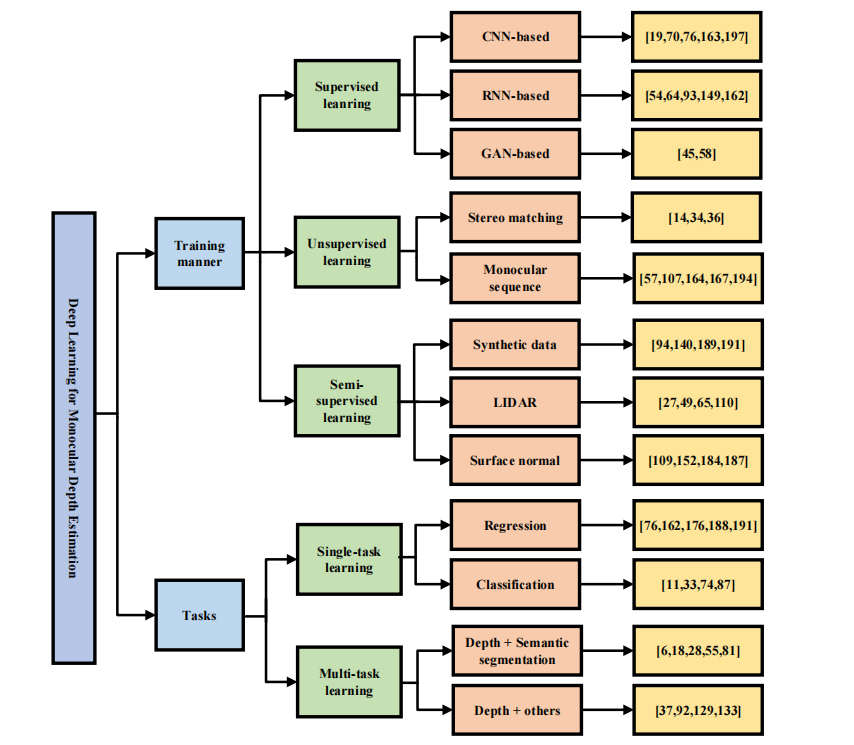
深度估计的一些深度模型
CNN
可以自动提取场景中表示深度的空间特征。他是一种前馈神经网络,与传统方法相比,它以更少的参数同时提取深度并且重建深度图。CNN主要有一个卷积层、池化层、全连接层和激活函数(通常是一个连续可微的非线性函数,以避免纯线性组合),用来使CNN可以学习输入图像的两维空间特征。CNN比较有代表性的网络有AlexNet, VGG, GoogLeNet,ResNet, DenseNet , and some lightweight network,such as MobileNet ,ShuffleNet ,and GhostNet通常用作CNN的骨干网络。
RNN
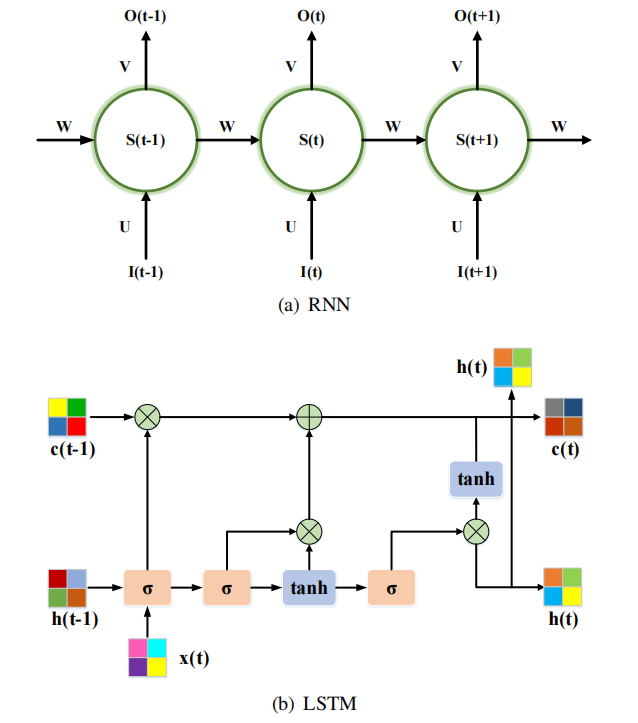
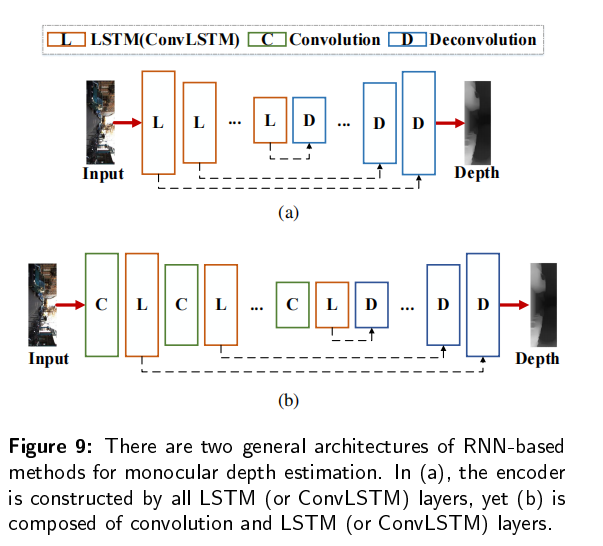
RNN是一个具有记忆能力的序列到序列模型,并将其引入单目深度估计中,从视频序列中学习时间特征。RNN是由三个单元组成的:输入层、隐藏层、输出层。隐藏层的输入是由当前输入单元和之前隐藏单元的输出组成。此外,有一个长短期记忆LSTM单元,可以通过三门结构学习长期依赖关系:输入门层、遗忘门层和输出门层。代表的RNN网络有BIRNN,GRU,ConvLSTM,ON-LSTM,Mogrifier LSTM 。通常与CNN结合来提取时空特征恢复深度。
GAN
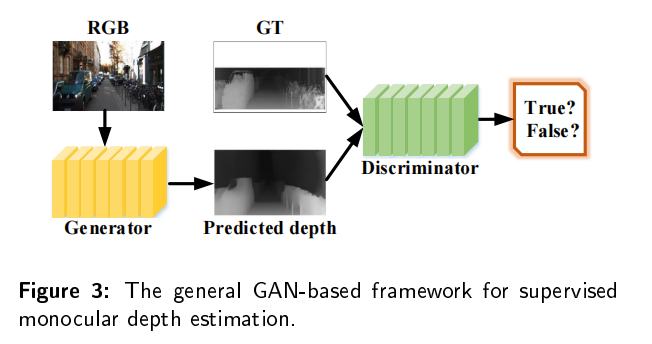
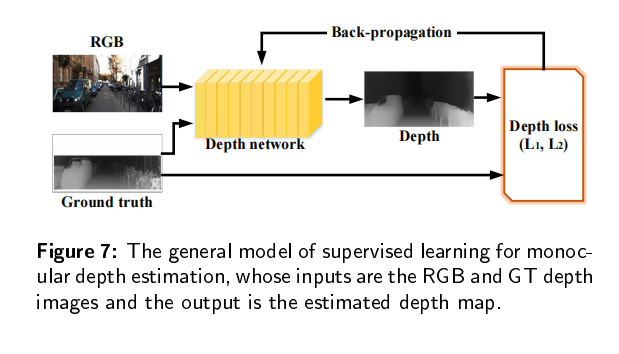
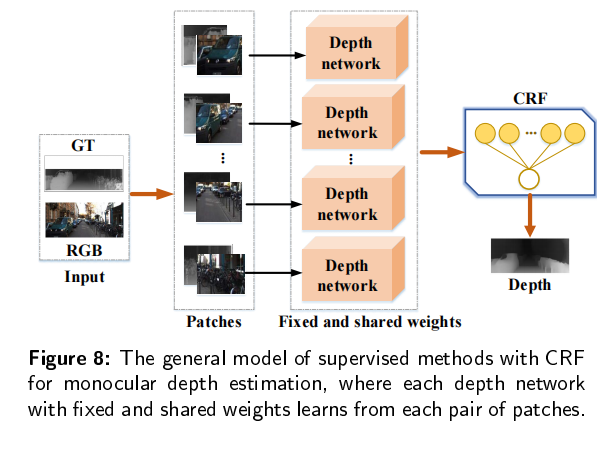
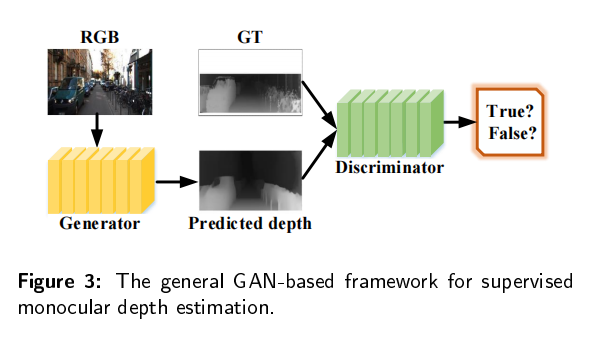
有监督的深度估计需要从地面真实值深度图中学习三维映射和尺度信息。但是要在真实场景中或者groundtruth图比较困难,所以研究人员引入了GAN来生成更加清晰、更加真实的深度图。GAN包括两个模块:生成器将深度图预测为一个深度估计网络;鉴别器确定输入的深度图是真的还是假的。比较有名的模型包括:conditional GAN,DCGAN,WGAN,stacked GAN,SimGAN,Cycle GAN。GAN可以为估计的深度图和真实深度图提供生成对抗性约束。