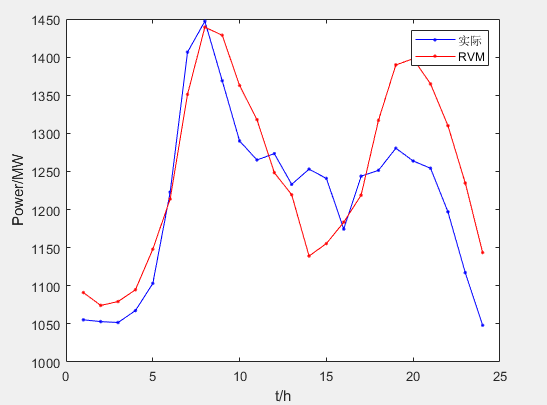
本文介绍: 传统的制造业或者实际厂家都是结合经验和数据进行,可能一个工艺表一直在沿用,但是随着设备和不同情况的更新迭代与出现,这种只依靠经验的规则无法适用于大规模的数据,一个工序只能一个人来调节,多个工序可能需要多个工艺师来互相配合,无法达到最优的结果。通过拿到问题我们都是采取机器学习的一些相关的回归算法进行,不管是神经网络模型还是各种基于概率还是树的模型,多个特征去预测一个特征是符合也是比较常见的一种建模思想,但是随着机器学习和深度学习的不断衍生,我们的需求也在越来越明确。实际上,数据的真实分布可能会有所偏差。
贝叶斯优化是一个全局优化方法,用于优化具有噪声的黑盒函数。这一方法在许多现实世界的问题中都有应用,特别是在那些评估目标函数的代价很高的场合,例如超参数调优。
背景:
在数据挖掘、机器学习和深度学习中,通常需要调整模型的参数(例如,学习率、树的深度等)来获得最佳性能。传统的方法,如网格搜索和随机搜索,不仅效率低下,而且很可能会错过最佳参数组合。而贝叶斯优化提供了一种更加高效的方法,它能够在较少的迭代中找到较好的参数值。
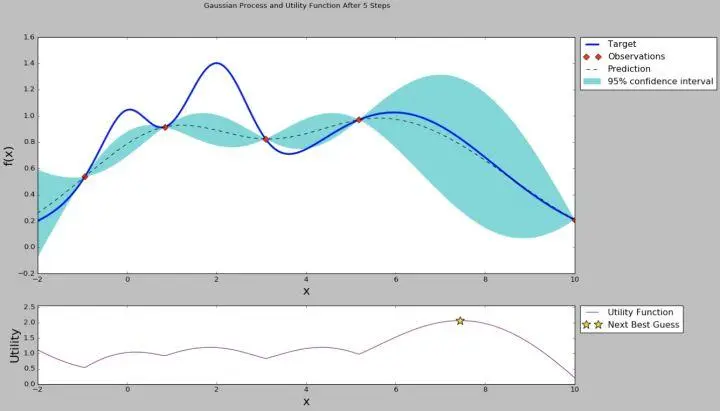
贝叶斯优化背后的核心思想是利用贝叶斯推断来构建目标函数的概率模型,通常使用高斯过程。这种概率模型能够为我们提供目标函数值的预测以及这些预测的不确定性(即预测的方差)。
基于这种预测和不确定性,贝叶斯优化定义了一个所谓的采集函数(例如预期提升),它告诉我们下一步应该在哪里评估目标函数。这样,贝叶斯优化就能够在每一步都做出明智的决策,选择合适的参数来评估,从而高效地找到最优解。
虽然贝叶斯优化最常用于超参数调优,但它同样可以应用于特征工程中,帮助确定最佳的特征表示或特征组合。
此外,贝叶斯优化也可以用于确定特定特征的最佳值,这在某些应用场景中可能非常有价值,例如化学、制药或其他领域,其中某些特征的精确值可能会导致最佳的实验结果。
实际案例
每文一语
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。