本文介绍: 预测推理性能很困难,需要进行直接测量实验,才能找到最佳执行参数。我们在此次大赛的硬件支持下和开发范围内进行了多次的性能测试,来确保验证应用的整体(端到端)性能。针对于不同的参数和优化逻辑,设备的表现根据批次大小而异。总结任务最佳批次大小取决于模型、推理精度等因素。同样 在某些情况下,可能需要将流和批处理结合起来才能尽力提高吞吐量。还有一种可能的吞吐量优化策略是设置延迟上限,然后增加批次大小和/或流数,直到出现长尾延迟问题(即吞吐量不再增加)为止。这个我们会在之后对模型的推理优化继续深究。
Stable Diffusion 推理优化

背景
2022年,Stable Diffusion模型横空出世,其成为AI行业从传统深度学习时代走向AIGC时代的标志性模型之一,并为工业界,投资界,学术界以及竞赛界都注入了新的AI想象空间,让AI再次性感。
Stable Diffusion是计算机视觉领域的一个生成式大模型,能够进行文生图(txt2img)和图生图(img2img)等图像生成任务。与Midjourney不同的是,Stable Diffusion是一个完全开源的项目(模型,代码,训练数据,论文等),这使得其快速构建了强大繁荣的上下游生态(AI绘画社区,基于SD的自训练模型,丰富的辅助AI绘画工具与插件等),并且吸引了越来越多的AI绘画爱好者也加入其中,与AI行业从业者一起不断推动AIGC行业的发展与普惠。
也正是Stable Diffusion的开源属性,繁荣的上下游生态以及各行各业AI绘画爱好者的参与,使得AI绘画火爆出圈,让大部分人都能非常容易地进行AI绘画。可以说,本次AI科技浪潮的ToC普惠在AIGC时代的早期就已经显现,这是之前的传统深度学习时代从未有过的。而这也是最让Rocky振奋的AIGC属性,让Rocky相信未来的十年会是像移动互联网时代那样,充满科技变革与机会的时代。
Stable Diffusion 本质是基于扩散模型的高质量图像生成技术,可根据文本输入生成图像,广泛应用于CG、插画和高分辨率壁纸等领域。然而,由于其计算过程较为复杂,Stable Diffusion 的图像生成速度常常成为遏制其发展的限制因素。
技术讲解:




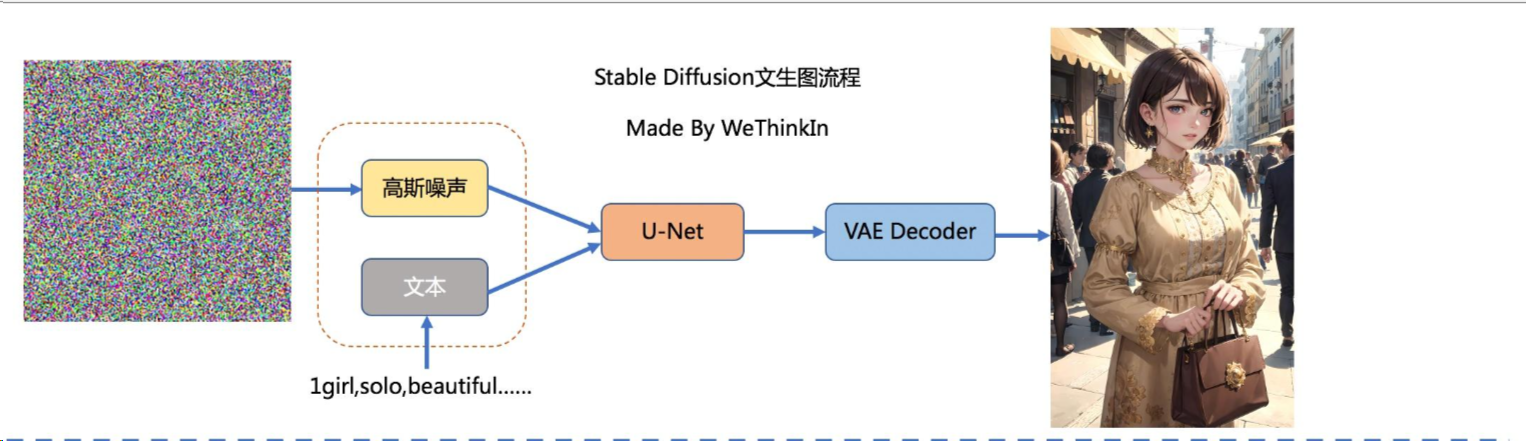
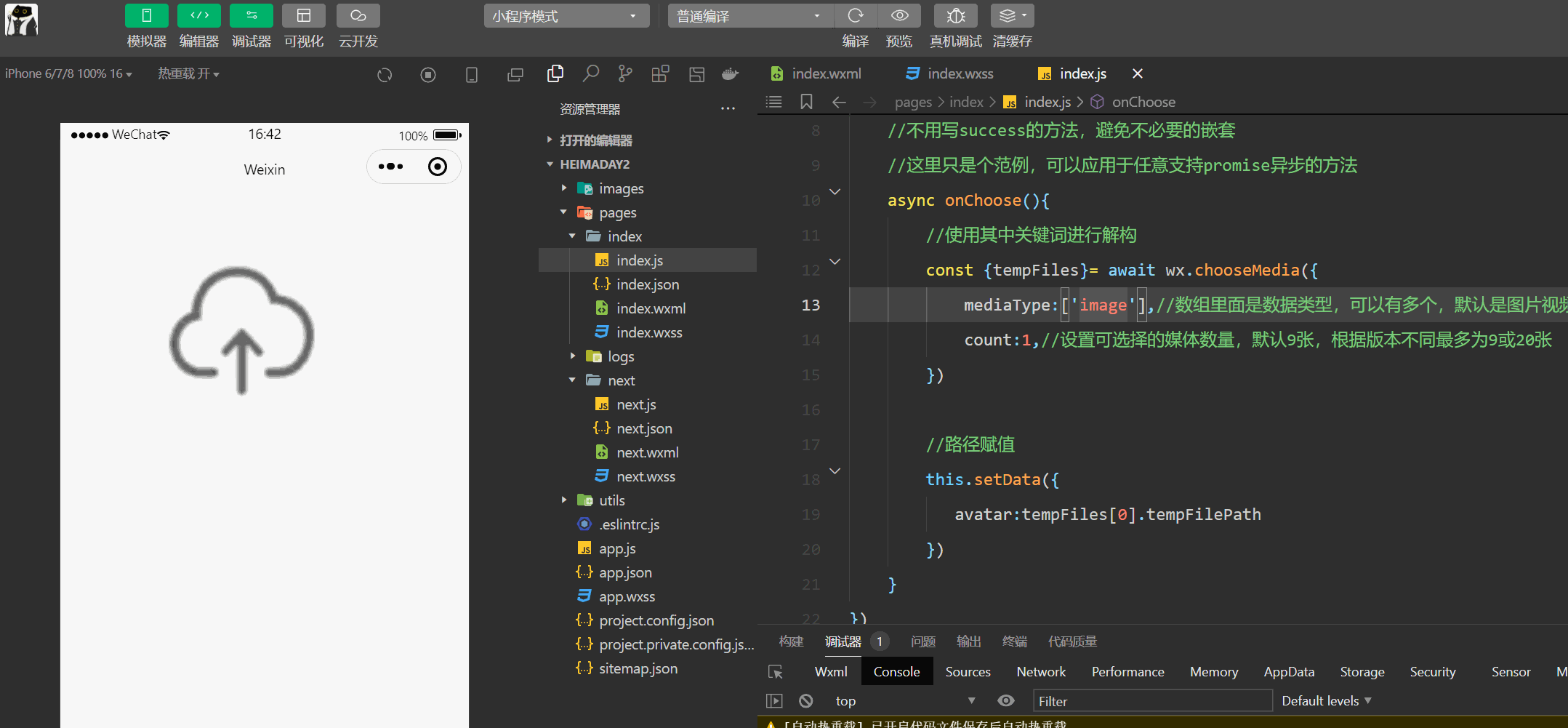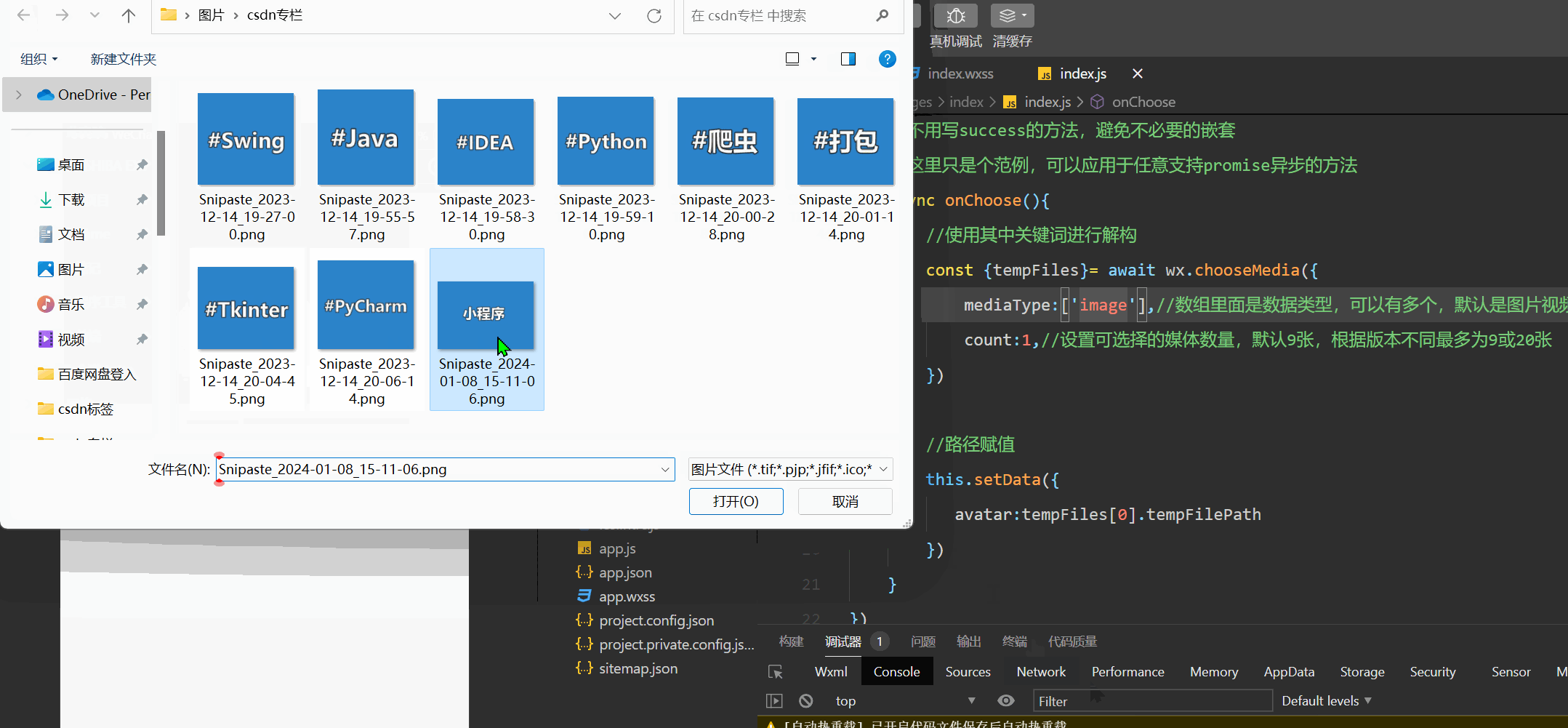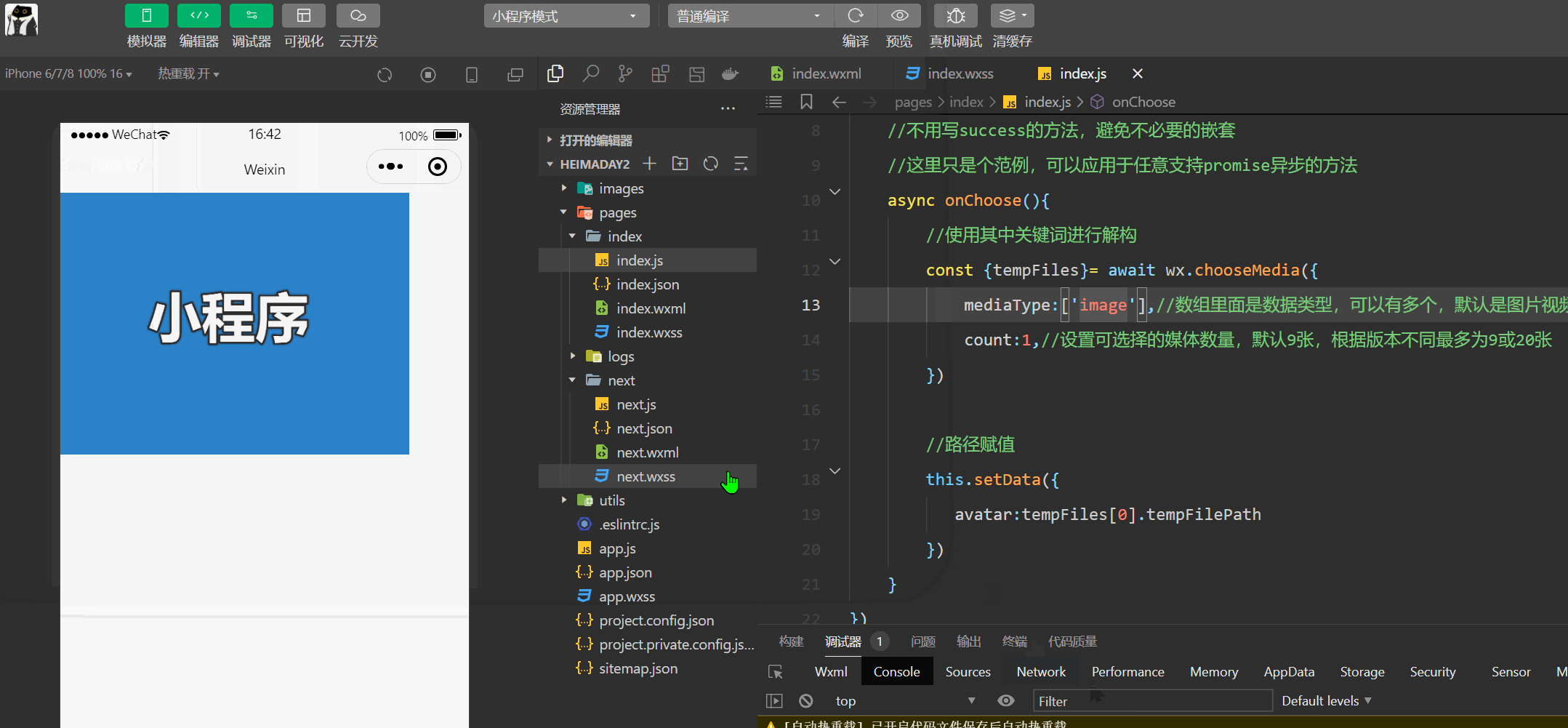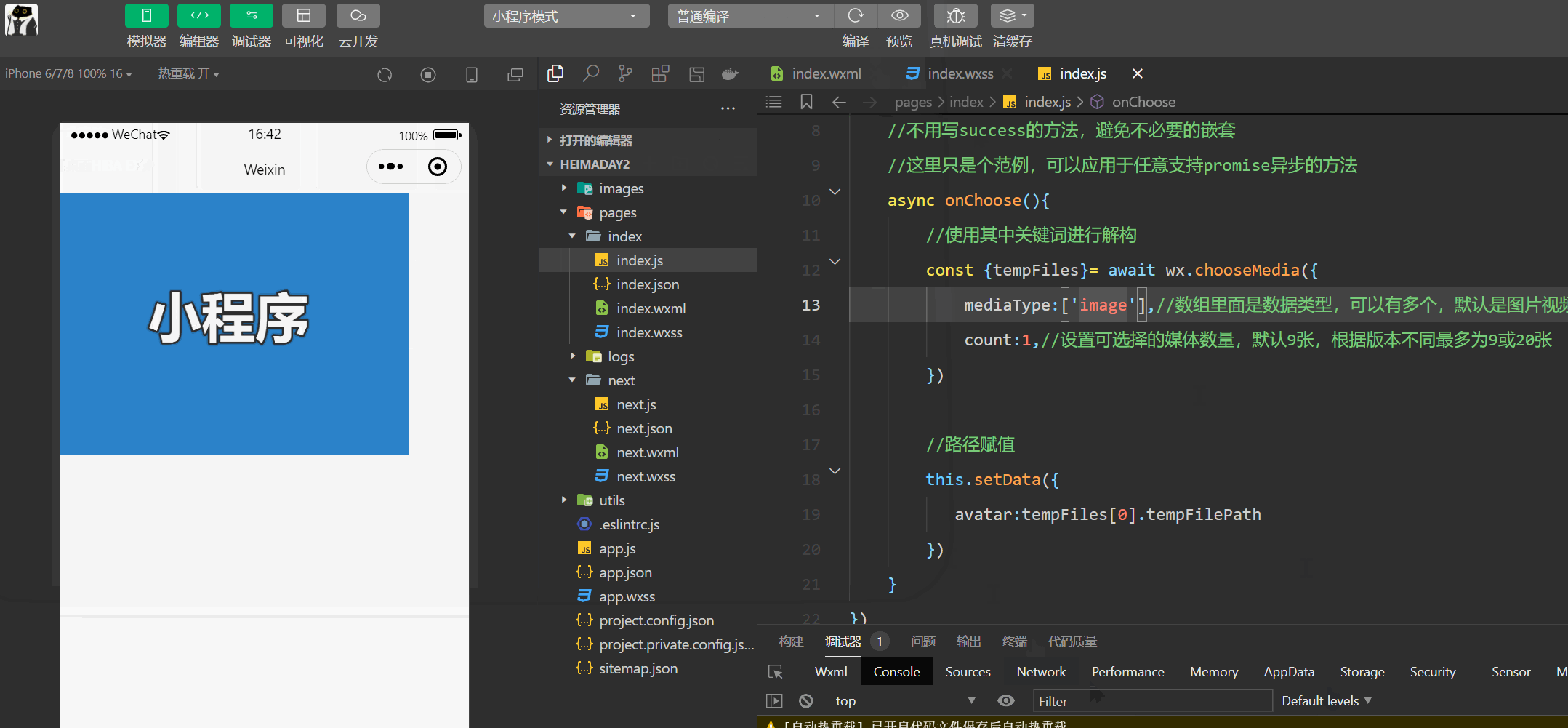
异步优化方案思路:
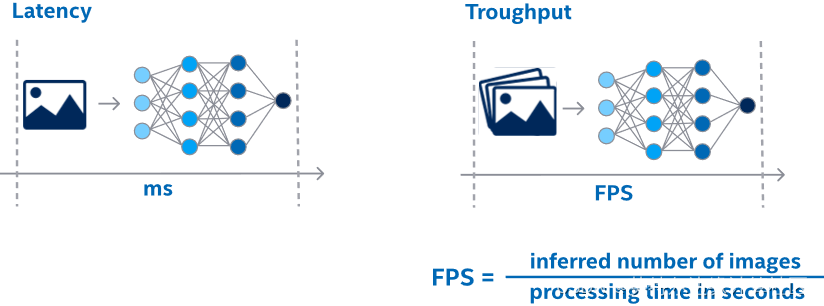
异步推理优化原理
OpenVINO异步推理Python API
同步和异步实现方式对比
oneflow分布式调度优化
优势:
实现思路
总结:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。