本文介绍: 索引是帮助MySQL高效获取数据的数据结构,主要是用来提高数据检索的效率,降低数据库的IO成本,同时通过索引列对数据进行排序,降低数据排序的成本,也能降低了CPU的消耗。通俗来说, 索引就相当于一本书的目录, 可以根据页码快速查找到指定的内容, 目的就是加快数据库的查询速度,但这也就意味着书中如果要增加一个章节,修改目录是比较麻烦的,使用索引适用于经常查询很少修改的业务1) 顺序访问顺序访问是在表中实行全表扫描,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。
基本介绍
索引是帮助MySQL高效获取数据的数据结构,主要是用来提高数据检索的效率,降低数据库的IO成本,同时通过索引列对数据进行排序,降低数据排序的成本,也能降低了CPU的消耗。
在 MySQL 中,通常有以下两种方式访问数据库表的行数据:
2) 索引访问
优缺点
优点:
缺点:
索引的底层数据结构
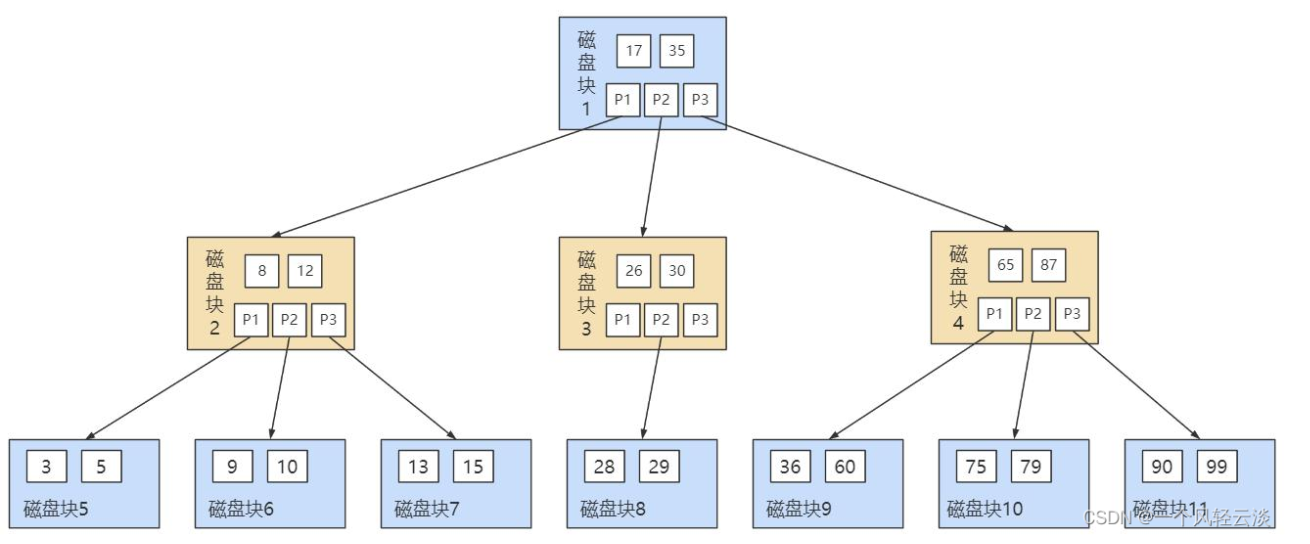
B树
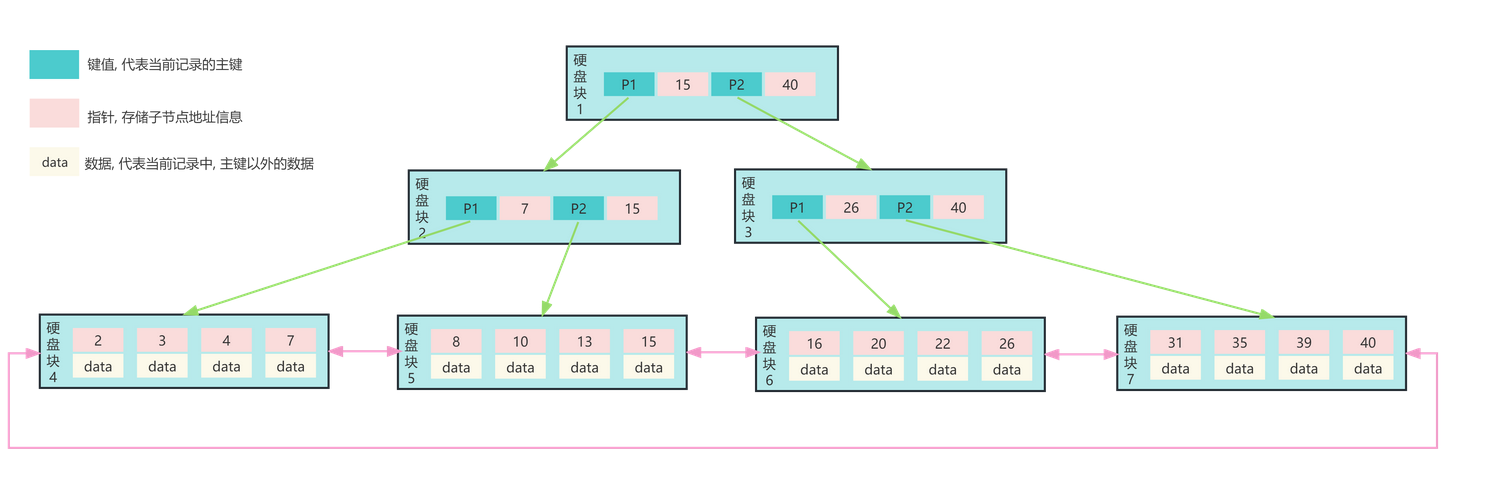
B+树
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。