在Linux中,一切皆文件,对Linux的操作就是对文件的处理。对文件操作处理最重要的三个命令是grep、sed、awk,它们在业界被称为“三剑客”。
grep擅长对文件或字符串进行取行筛选,可以配合其他命令进行多次筛选
sed擅长取行和修改,可以对指定文件或字符串中的内容进行替换
awk擅长取列(也即字符field),通常用于文件操作
Linux三剑客——awk命令
awk命令来自它的三位创始人Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。awk命令具有读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等功能。
基本用法
awk语言的最基本功能是在文件或者字符串中基于指定规则提取相关信息,awk抽取信息后,才能进行其他文本操作。
awk [options] 'action' filename
其中options是可用选项参数,而 action 是在找到匹配内容时所执行的一系列命令,通常使用花括号{}括起来,而{}并不是必需,但它们用于根据特定的模式对一系列指令进行分组。
在 awk 中,花括号{}用于将几块代码组合到一起,这一点类似于 C 语言中用花括号{}表示代码块。在 awk 中,如果只出现 print 命令,那么将打印当前行的全部内容。
命令选项
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
常用的参数选项有:
用法:awk [POSIX 或 GNU 风格选项options] -f 脚本文件 [--] 文件 ...
用法:awk [POSIX 或 GNU 风格选项options] [--] '程序' 文件 ...
POSIX 选项: GNU 长选项:(标准)
-f 脚本文件 --file=脚本文件
-F fs --field-separator=fs
-v var=val --assign=var=val
-F : 指定文本分割符 默认空格或tab
–v : 定义变量,即设置变量,以方便在之后的代码块中使用改变量
-f : 指定awk的脚本文件或命令文本,当awk的匹配规则比较复杂时,可将其写入到文件,通过-f参数引用改文件。
用法:awk [POSIX 或 GNU 风格选项options] -f 脚本文件 [--] 文件 ...
用法:awk [POSIX 或 GNU 风格选项options] [--] '程序' 文件 ...
POSIX 选项: GNU 长选项:(标准)
-f 脚本文件 --file=脚本文件
-F fs --field-separator=fs
-v var=val --assign=var=val
短选项: GNU 长选项:(扩展)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[文件] --dump-variables[=文件]
-D[文件] --debug[=文件]
-e '程序文本' --source='程序文本'
-E 文件 --exec=文件
-g --gen-pot
-h --help
-i 包含文件 --include=包含文件
-l 库 --load=库
-L[fatal|invalid] --lint[=fatal|invalid]
-M --bignum
-N --use-lc-numeric
-n --non-decimal-data
-o[文件] --pretty-print[=文件]
-O --optimize
-p[文件] --profile[=文件]
-P --posix
-r --re-interval
-s --no-optimize
-S --sandbox
-t --lint-old
-V --version
gawk 是一个模式扫描及处理语言。缺省情况下它从标准输入中读入并写至标准输出。
范例:
gawk '{ sum += $1 }; END { print sum }' file
gawk -F: '{ print $1 }' /etc/passwd
内置变量
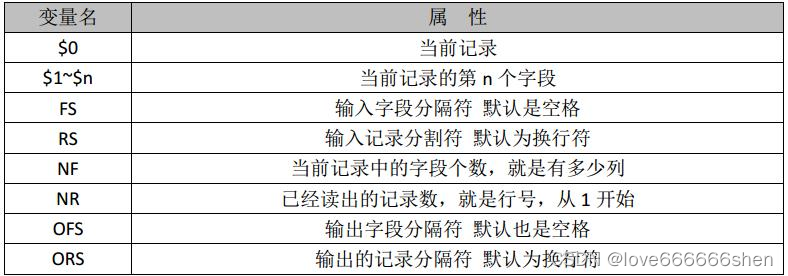
- NF:Number Field,记录中的字段个数,即列数,从1开始计算,$NF表示最后一列
- OFS:Output Field Separator输出字段分隔符
- ORS:Output Record Separator输出记录分隔符
使用示例
# 1、指定分隔符,简单输出指定列
$ awk '{print $0}' a.txt #打印文件所有内容($0代表整行)
$ awk '{print $1,$2}' a.txt #打印第1列和第2列的内容
$ awk -F":" '{print $1,$2}' OFS="," a.txt #以:为输入分隔符并且以,为输出分隔符打印第1列和第2列的内容
$ awk -F"," '{print NR,$NF}' a.txt #以,为输入分隔符并打印行号和最后一列
$ awk -F"[ .]" '{print $(NF-1)}' OFS="t" a.txt #以空格或.为输入分隔符并以制表符为输出分隔符打印倒数第二列
# 2、正则表达式
/正则/ 匹配正则(行)
~/正则/ 匹配正则(列)
!~/正则/ 不匹配
# 以:为输入分隔符,正则匹配第1列中的root,并输出当前行的内容
$ awk -F":" '$1~/root/ {print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
$ awk -F":" '$1~/root/ {print $0, $NR}' /etc/passwd
root:x:0:0:root:/root:/bin/bash root
$ awk -F":" '/root/ {print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
nm-openvpn:x:115:123:NetworkManager OpenVPN,,,:/var/lib/openvpn/chroot:/usr/sbin/nologin
$ awk -F":" '/root/ {print $0, $NR, $NF}' /etc/passwd
root:x:0:0:root:/root:/bin/bash root /bin/bash
nm-openvpn:x:115:123:NetworkManager OpenVPN,,,:/var/lib/openvpn/chroot:/usr/sbin/nologin /usr/sbin/nologin
$ awk -F":" '$1!~/root/ {print $0}' /etc/passwd
$ awk -F":" '$1~/^ro/ {print $3}' /etc/passwd
$ awk -F":" '$1~/[0-9]/ {print $1,$6}' /etc/passwd
xiaoshou1 /home/xiaoshou1
# 3、数值比较
# 以:为输入分隔符,如果第3列为0,则打印当前行的完整内容
$ awk -F":" '$3==0{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
$ awk -F":" '$3==0{print $0, $NF}' /etc/passwd
root:x:0:0:root:/root:/bin/bash /bin/bash
$ awk -F":" '$3!=0{print $0}' /etc/passwd
# 以:为分隔符,如果第1列为root,则打印当前行及最后一列的值
$ awk -F":" '$1=="root"{print $0, $NF}' /etc/passwd
root:x:0:0:root:/root:/bin/bash /bin/bash
# 4、逻辑比较(多个条件)
逻辑与 && 多个条件同时成立
逻辑或 || 多个条件有一个成立
逻辑非 ! 取反
awk -F":" '$7=="/bin/bash" && $3<500{print $0}' /etc/passwd
awk -F":" '$7=="/bin/bash" || $3<500{print $0}' /etc/passwd
Linux三剑客——sed命令
sed全称为Stream EDitor,是一种流编辑器,作用是实现对文件的增删改查,它一次处理一行内容。
使用sed进行文件处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。
使用sed进行字符串替换处理时,文件内容并没有改变,除非你使用重定向存储输出。
调用sed命令有两种形式:
sed [options] 'command' file(s)
sed [options] -f scriptfile file(s)
常用参数选项:
-n 屏蔽默认输出
-i 直接修改源文件
-e 可指定多个处理动作
-r 支持扩展表达式
{} 可组合多个命令,以;分隔
-f 使用sed脚本
定址符:
p 打印行
d 删除行
s 字符串替换
1 对第1行处理
1,3 对第1到3行处理
1,+3 对第1行后面3行处理
1~2 对1,3,5,7……行处理
1,$ 对1行到最后1行处理
/aa/,/bb/ 对a行到b行处理
/aaa/,9 对a行到第9行,若前9行没有,会显示后9行匹配的行
参数选项
用法: sed [选项]... {脚本(如果没有其他脚本)} [输入文件]...
-n, --quiet, --silent
取消自动打印模式空间,屏蔽默认输出
--debug
annotate program execution
-e 脚本, --expression=脚本
添加“脚本”到程序的运行列表
-f 脚本文件, --file=脚本文件
添加“脚本文件”到程序的运行列表
--follow-symlinks
直接修改文件时跟随软链接
-i[扩展名], --in-place[=扩展名]
直接修改文件(如果指定扩展名则备份文件)
-l N, --line-length=N
指定“l”命令的换行期望长度
--posix
关闭所有 GNU 扩展
-E, -r, --regexp-extended
在脚本中使用扩展正则表达式
(为保证可移植性使用 POSIX -E)。
-s, --separate
将输入文件视为各个独立的文件而不是单个长的连续输入流。
--sandbox
在沙盒模式中进行操作(禁用 e/r/w 命令)。
-u, --unbuffered
从输入文件读取最少的数据,更频繁的刷新输出
-z, --null-data
使用 NUL 字符分隔各行
--help 打印帮助并退出
--version 输出版本信息并退出
如果没有 -e, --expression, -f 或 --file 选项,那么第一个非选项参数被视为
sed脚本。其他非选项参数被视为输入文件,如果没有输入文件,那么程序将从标准
输入读取数据。
使用示例
举例子:(注意:sed增删改如果不加 -i 选项的话只是预览模式,并没有真的增删改)
插入
# 增(插入i前插、a后插)
sed -i '2ixx' m.txt 在第2行前插入行xx
sed -i '3,6ixx' m.txt 在第3-6行每行前插入xx
sed -i '2axx' m.txt 在第2行后插入xx
sed -i '/^yy/axx' m.txt 在yy开头的行后插入xx
删除
# 删(d表示delete删除)
sed -i '3,5d' a.txt 删除第3到5行
sed -i '/xml/d' a.txt 删除所有包含xml的行
sed -i '/xml/!d' a.txt 删除不包含xml的行
sed -i '/^xml/d' a.txt 删除以xml开头的行
sed -i '$d' a.txt 删除最后1行
sed -i '/^$/d' a.txt 删除所有空行
sed -i '/^$/{n;/^$/d}' a.txt 删除重复空行,连续两个空行只保留一个
sed -i -r'/a|b/d' a.txt 删除a或b的行
sed -i '2,~2d' a.txt 删除2行到2的倍数行
修改
在sed命令中,使用c表示进行指定行的替换;s表示指定字符串的替换;g表示全局替换global。
# 改(加-i选项才会真的修改源文件)
sed -i '2cxx' m.txt 第2行替换成xx
sed -i '3,6cxx' m.txt 第3到6行替换成1行xx
sed -i -e '3cxx' -e '6cxx' m.txt 第3行和第6行替换成xx
sed -i '2cxxnyy' m.txt 第2行替换成xx并换行写上yy(n代表换行)
# 使用g进行全局替换
sed -i 's/test/demo/g' a.txt 将所有的test换成demo(常用)
sed -i 's/#ipv6=no/ipv6=yes/g' test.txt 将test.txt文件里`#ipv6=no`改成`ipv6=yes`(sed的这种用法经常用来更改配置文件里的内容,如去除注释、开启配置开关等)
sed -i 's/a//g' a.txt 删除所有行的a
sed -i '4,7s/^/#/' a.txt 4到7行加#号
sed -i '4,7s/^#//' a.txt 4到7行去掉#号
sed -i 's/a/B/ig' a.txt 所有行的a替换成B(不区分大小写ig)
查找
查:
sed –n ’20,30p’ b.txt 打印20到30行
sed -n '3p;6p' a.txt 打印第3和6行
sed -n '3,+6p' a.txt 打印第3行及其后6行
sed -n '/^bin/p' a.txt 打印以bin开头的行
sed -n 'p;n' a.txt 打印奇数行,n表示读下一行(隔行)
sed -n 'n;p' a.txt 打印偶数行,n表示读下一行(隔行)
sed -n '8,${n;p}' a.txt 打印8行到末尾所有的偶数行
sed -n '$=' a.txt 打印文件的行数
sed -n '/a/{=;p} ' b.txt 显示行号
sed -n l aaa.jpg 打印不可见字符
使用sed 命令实现 cut 命令的效果
假如想实现类似于 cut -d: -f 1 /etc/passwd 的效果,也就是以冒号为分割符提取第1个字段的内容,用 sed 命令应该怎么操作呢?
# 查看/etc/passwd文件前5行的内容
$ head -n 5 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
# 使用sed命令来提取文件中每行的第一个域, 间隔符是冒号,从冒号到`.`最后一个字符`*`之间的字符都清空(`//`表示/新的字符为控制方程,去替换原字符串)
$ head -n 5 /etc/passwd|sed 's/:.*$//'
root
daemon
bin
sys
sync
# 使用cut实现将/etc/passwd中以:分割,输出前5行第一列的值
$ cut -d: -f 1 /etc/passwd | head -n 5
root
daemon
bin
sys
sync
sed 's/:.*$//'中的参数,表示把每一行的第一个冒号到结尾的部分都清空,这样留下的便是第一个冒号前的内容。
Linux三剑客——grep命令
grep是文本过滤工具,常用于查找、过滤文件里符合条件的字符串。
语法:
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
常用的参数选项有:
-c:只输出匹配行的计数
-i:不区分大小写
-n:显示匹配行及行号
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
–color=auto :可以将找到的关键词部分加上颜色的显示
参数选项
-a 或 --text : 不要忽略二进制的数据。
-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 --count : 计算符合样式的列数。
-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F 或 --fixed-regexp : 将样式视为固定字符串的列表。
-G 或 --basic-regexp : 将样式视为普通的表示法来使用。
-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-i 或 --ignore-case : 忽略字符大小写的差别。
-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 --only-matching : 只显示匹配PATTERN 部分。
-q 或 --quiet或--silent : 不显示任何信息。
-r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
-s 或 --no-messages : 不显示错误信息。
-v 或 --invert-match : 显示不包含匹配文本的所有行。
-V 或 --version : 显示版本信息。
-w 或 --word-regexp : 只显示全字符合的列。
-x --line-regexp : 只显示全列符合的列。
-y : 此参数的效果和指定"-i"参数相同。
-color=auto :可以将找到的关键词部分加上颜色的显示
使用示例
grep -i root passwd.txt # 查找文件passwd.txt中,内容包含root(忽略大小写)的行
grep -v root passwd.txt # 查找文件内容不包含root的行
grep -w "root" passwd.txt # 查找文件内容包含整个单词"root"的行
grep ^s passwd.txt # 查找以s开头的行
grep n$ passwd.txt # 查找以n结尾的行
egrep "^([0-9]{1,3}.){3}[0-9]{1,3}$" log.txt | sort | uniq -c # 查找log.txt文件中,所有ip地址并统计每个ip出现的次数
cat -b passwd.txt | grep mail # 过滤并显示passwd.txt文件中mail所在行
cat -b passwd.txt | grep mail -2 # 查看mail及其上下两行
cat -b passwd.txt | grep mail -A2 # 查看mail及下面的两行
cat -b passwd.txt | grep mail -B2 # 查看mail及上面的两行
cut命令
cut命令,正如其名字的含义,其主要工作就是“剪”,具体的说就是在文件中负责剪切数据用的。
cut命令可以从一个文本文件或者文本流中提取文本列。
cut的基本用法
语法:
cut [options] filename
比如:
cut -d'分隔字符' -f fields (用于有特定分隔字符)
cut -c 字符区间 (用于排列整齐的信息)
options选项:
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志
-c :以字符为单位进行分割
-d :自定义分隔符,默认为制表符
-f :与-d一起使用,指定显示哪个字段field
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的<br />范围之内,该字符将被写出;否则,该字符将被排除。
使用实例
# 将 PATH 变量以:为分隔符取出,找出第五个路径(-d :后面接分隔字符。与 -f 一起使用;)
sky@sky: echo $PATH | cut -d ':' -f 5
# 只显示/etc/passwd的用户和shell
sky@sky: cat /etc/passwd | cut -d ':' -f 1,7
# 查看/opt目录下的文件和子目录
sky@sky:~$ ls -al /opt
总用量 28
drwxr-xr-x 7 root root 4096 11月 21 13:56 .
drwxrwxrwx 20 root root 4096 11月 21 19:48 ..
drwxr-xr-x 4 root root 4096 11月 11 13:52 apps
drwx--x--x 4 root root 4096 11月 17 16:22 containerd
drwxr-xr-x 5 root root 4096 11月 14 11:17 electerm
drwxr-xr-x 3 root root 4096 11月 11 13:52 sogoupinyin
drwxr-xr-x 27 root root 4096 11月 21 14:09 playgame
# 查看/opt目录下文件/子目录名为playgame的信息
sky@sky: ls -al /opt | grep playgame
drwxr-xr-x 27 root root 4096 11月 21 14:09 playgame
# 以""为分隔符,相当于打印/opt目录下名称为playgame的行信息
sky@sky:~$ ls -al /opt | grep playgame | cut -d "" -f9
drwxr-xr-x 27 root root 4096 11月 21 14:09 playgame
# grep配合cut获取结果中的第9个字段/列的值
sky@sky:~$ ls -al /opt | grep playgame | cut -d " " -f9
playgame
正则表达式
Linux三剑客也是命令,可以把它们看做处理文本的工具,而正则表达式就好比一个模版。这个模版由一些普通字符和元字符组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义。Linux中的awk、sed、cut三剑客,能读懂这个模版,因此它们之间的搭档会让处理文本事半功倍。
字符类
- 点
.可以匹配任意的单个字符 - 中括号
[]填充的字符串,表示可以匹配中括号内的任意一个字符;中括号内可以使用-表示字符(包括数字)范围,表示可以匹配该范围内的任意一个字符;在[]中以^开头的字符串,表示匹配排查这些字符后的任意字符 - 问号
?表示匹配其前面的字符0次或1次 - 加号
+表示匹配其前面的字符至少1次 - 星号
*表示匹配其前面的字符任意多次
数量限定符
?:匹配其前面的字符0次或1次
+:匹配其前面的字符至少1次
*: 匹配其前面的字符任意多次
{N}:匹配其前面的字符N次
{N,}:匹配其前面的字符至少N次
{,M}:匹配其前面的字符最多M次
{N,M}:匹配其前面的字符N到M次
位置限定符
^:匹配行首的位置
$:匹配行尾的位置
<:匹配单词开头的位置(比如<ro匹配root或robot)
>:匹配单词结尾的位置(比如ot>匹配root或robot)
<word>:精准匹配单词word
参考
Linux三剑客(grep、awk、sed)超详细版
Linux三剑客 grep sed awk 详细使用方法
Linux三剑客
sed命令:替换、删除、更新文件中的内容
Linux三剑客之awk命令
cut命令详解
原文地址:https://blog.csdn.net/love666666shen/article/details/128038844
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_39024.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




