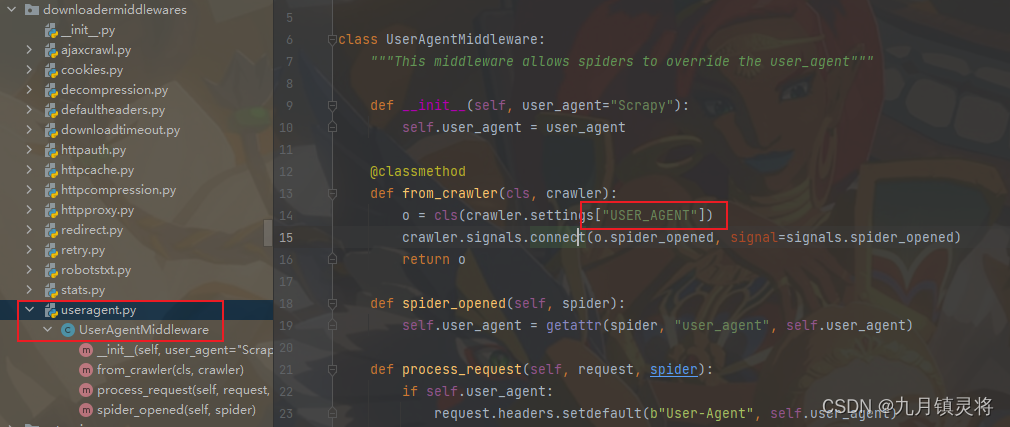
本文介绍: Scrapy的中间件有两个:爬虫中间件(一般不会去用,就不多赘述了下载中间件中间件在五大核心组件的什么位置:下载中间件位于引擎和下载器之间。引擎会给下载器传递请求对象,下载器会给引擎返回响应对象。根据位置了解中间件的作用:可以拦截到scrapy框架中所有的请求和响应。拦截请求干什么?修改请求的ip,修改请求的头信息,设置请求的cookie。拦截响应干什么?可以修改响应数据。这就是2个中间件,其中爬虫中间件很少用到,为了简介明了,我们给他删除或者注释掉就行了。

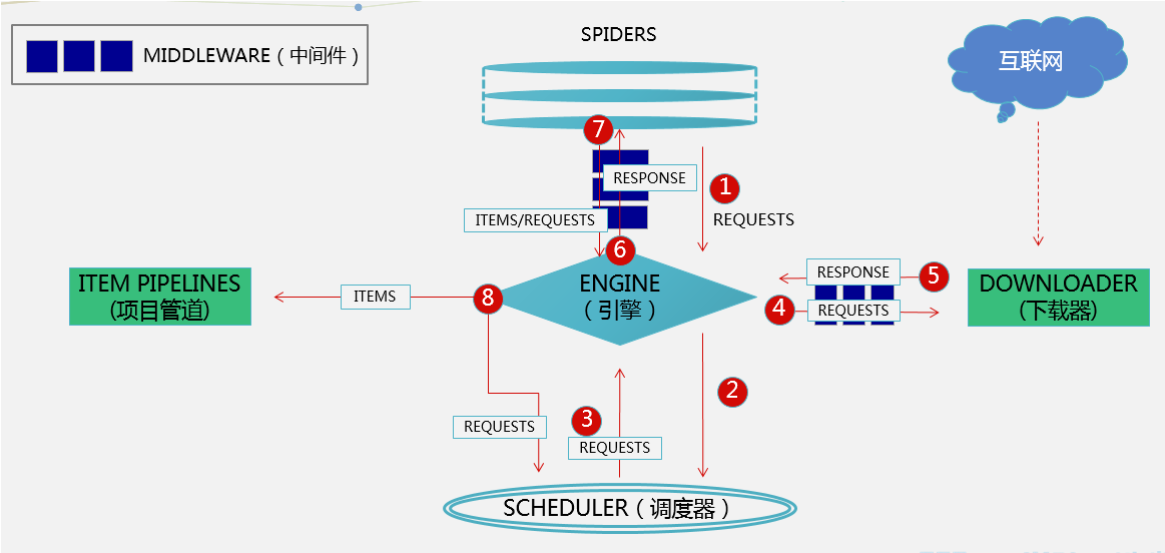
什么是中间件?
一、中间件的应用
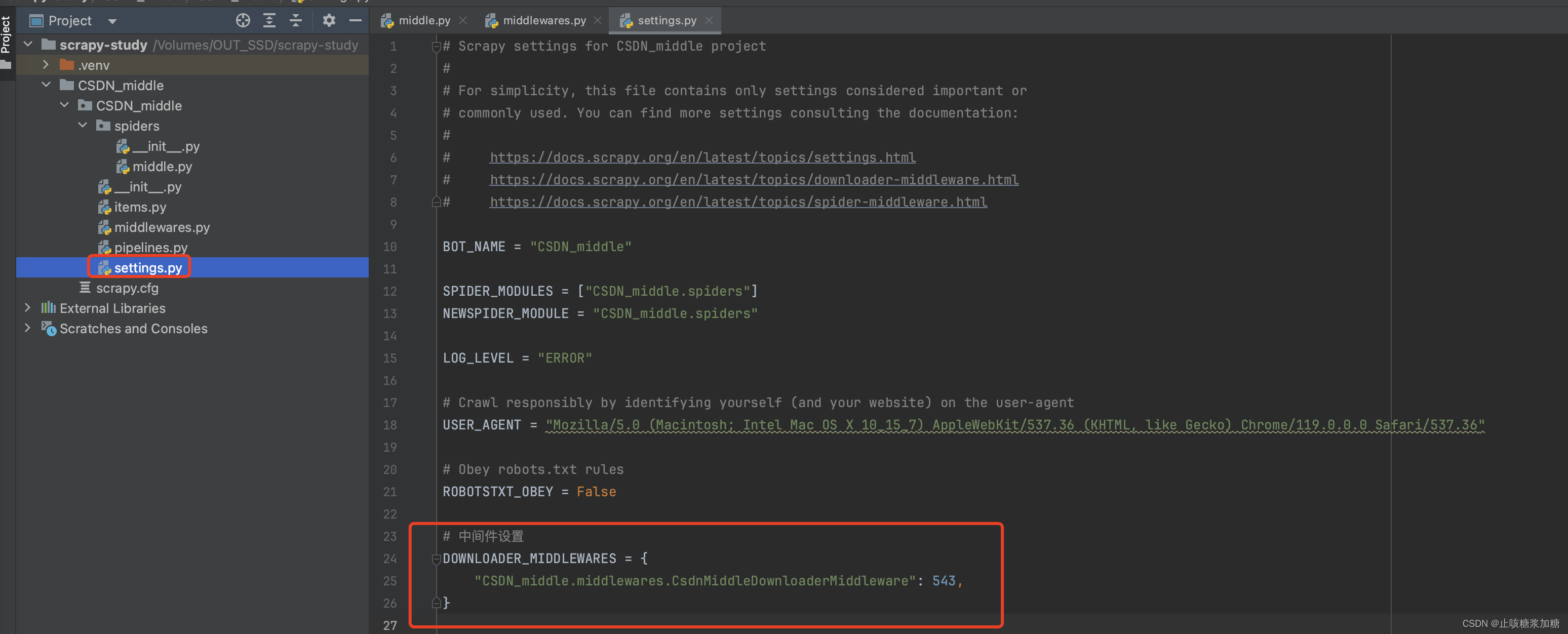
1:中间件的介绍
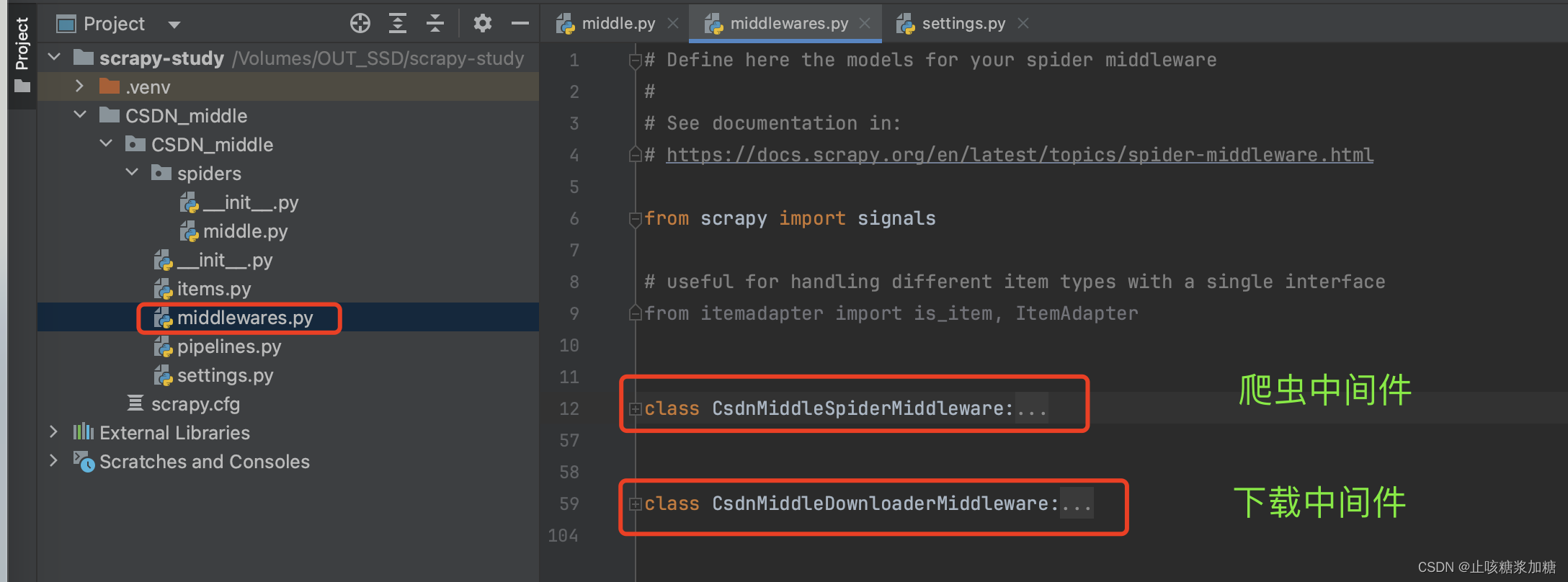

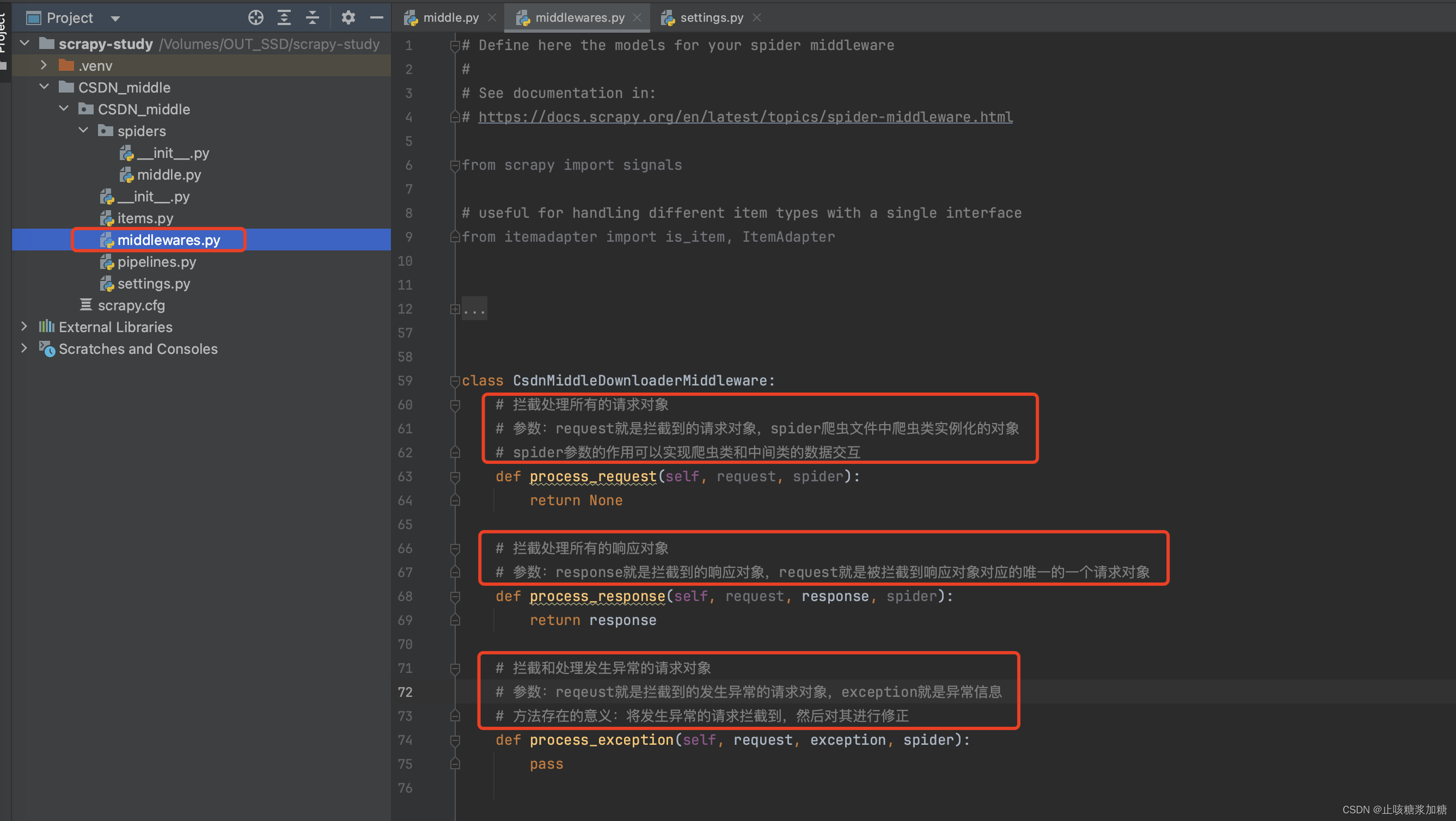
1.1:中间件的运行顺序

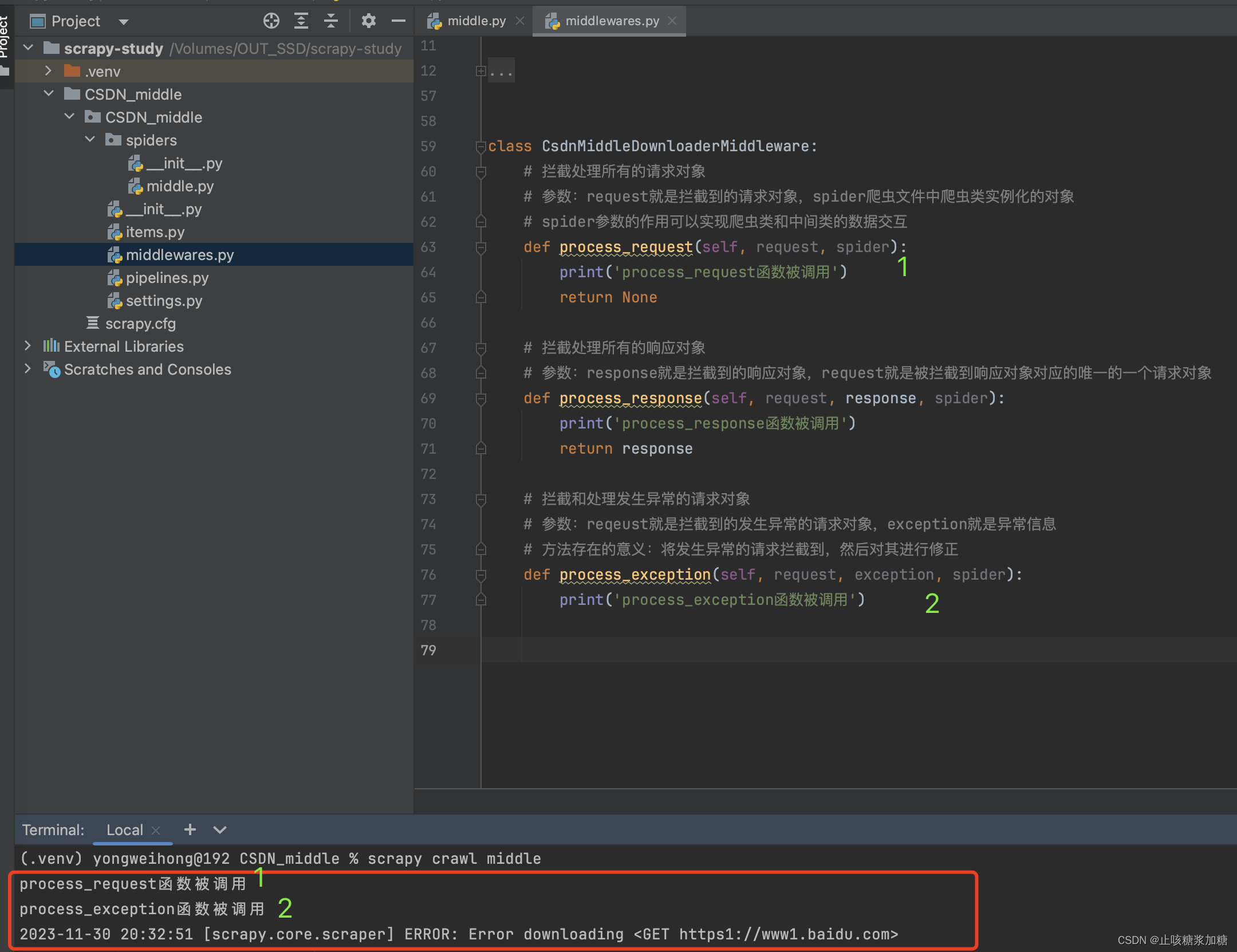
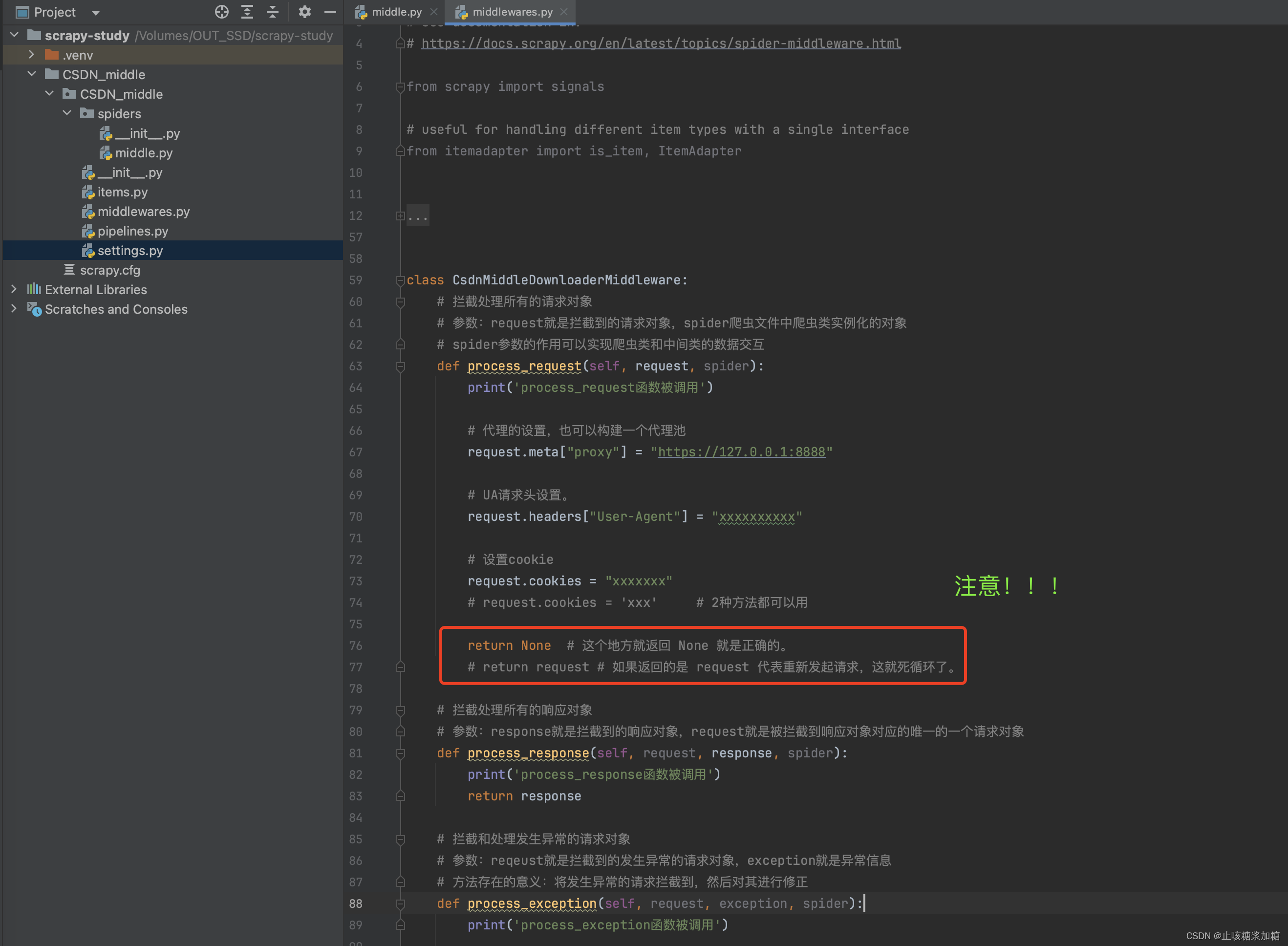
2:process_request 拦截修改请求
1:开发代理中间件

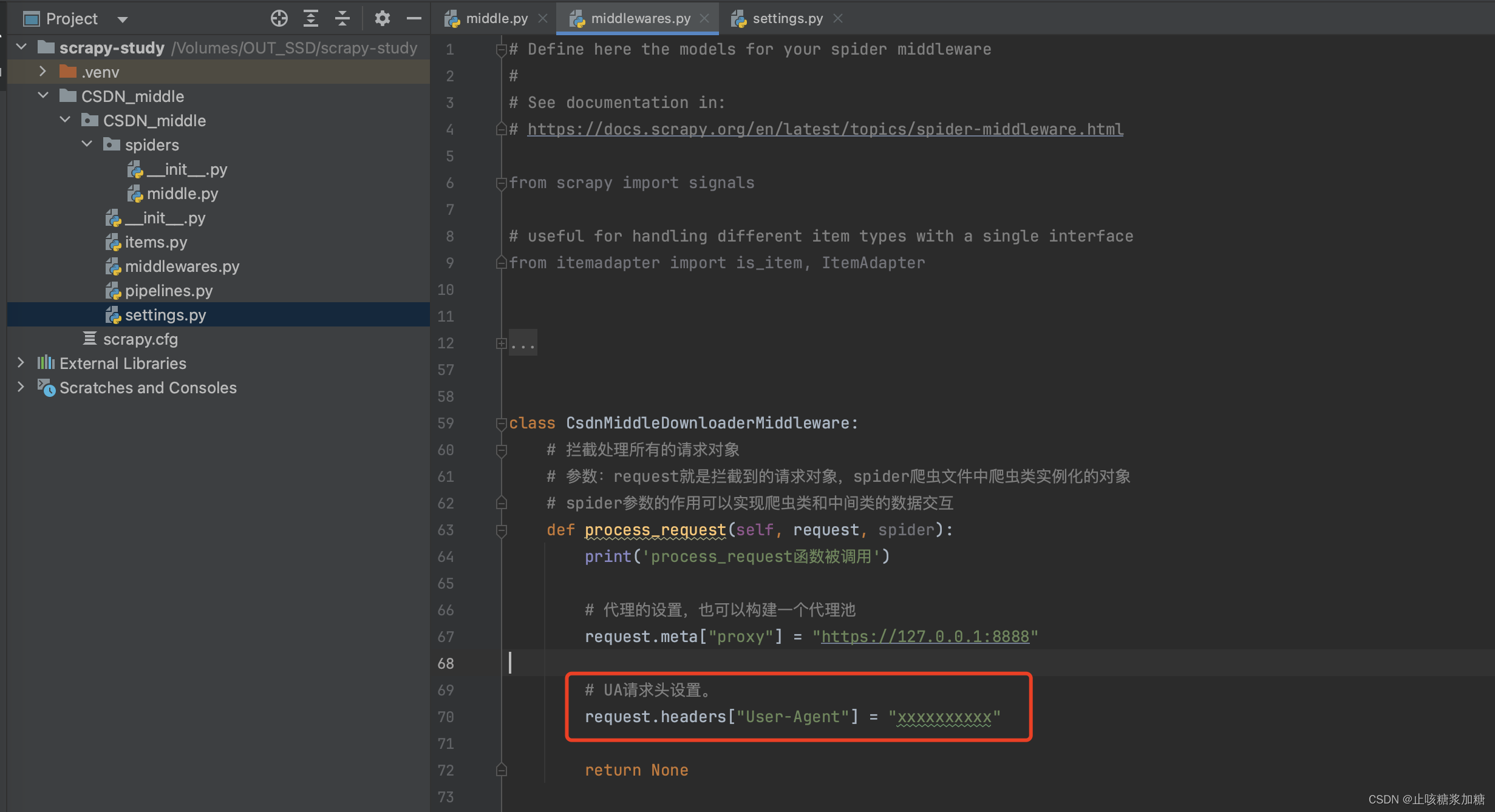
2:开发UA中间件
3:开发Cookie中间件

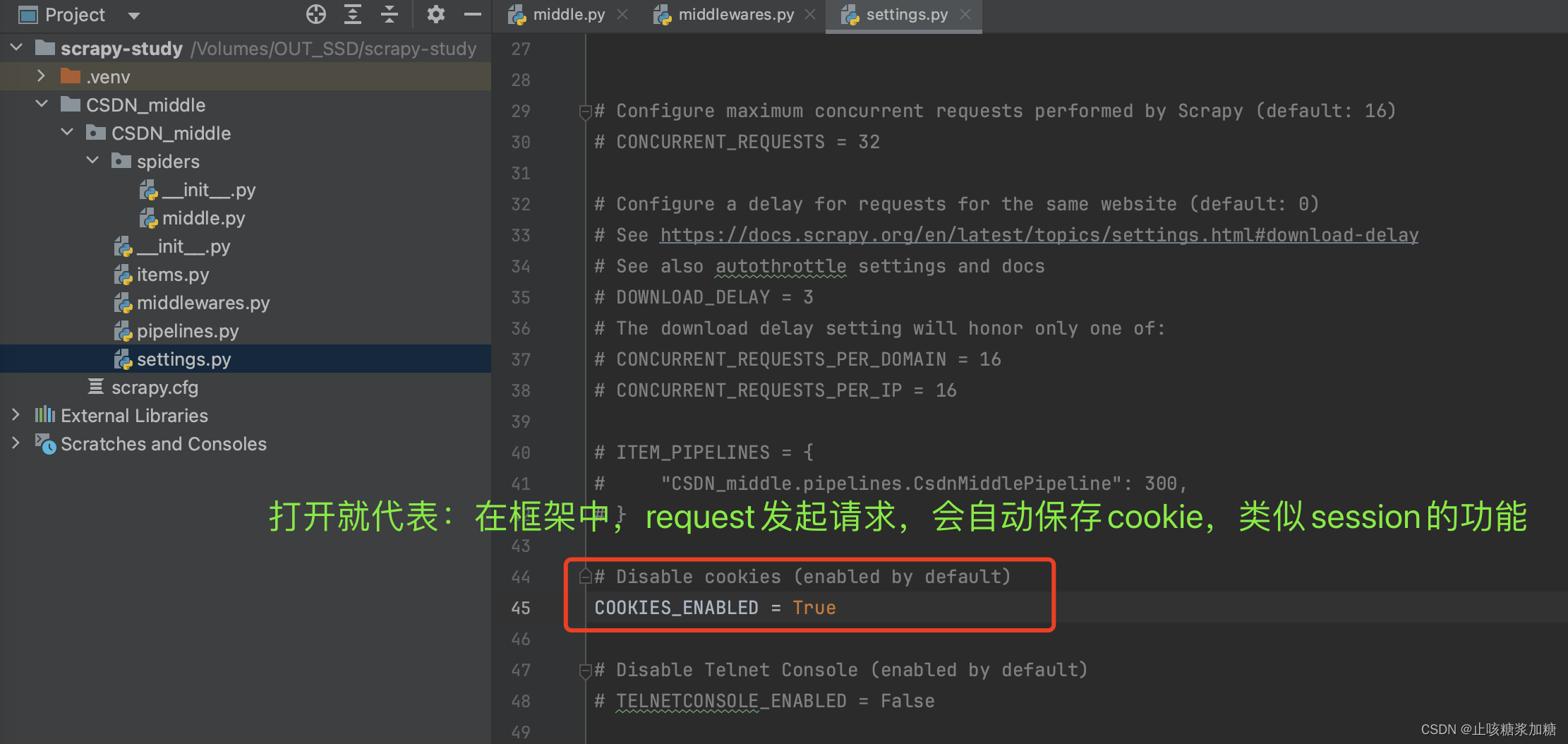
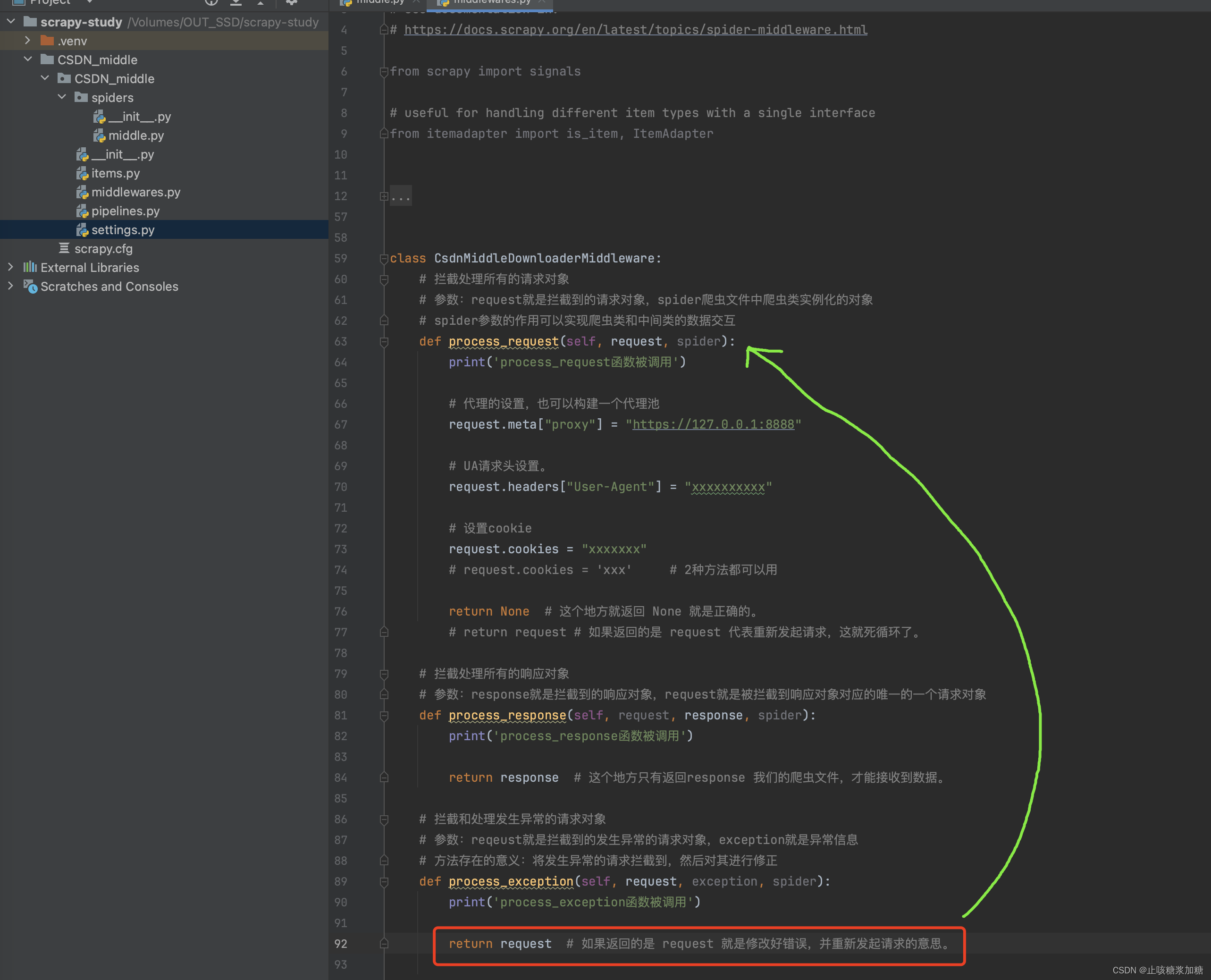
补充:return返回值
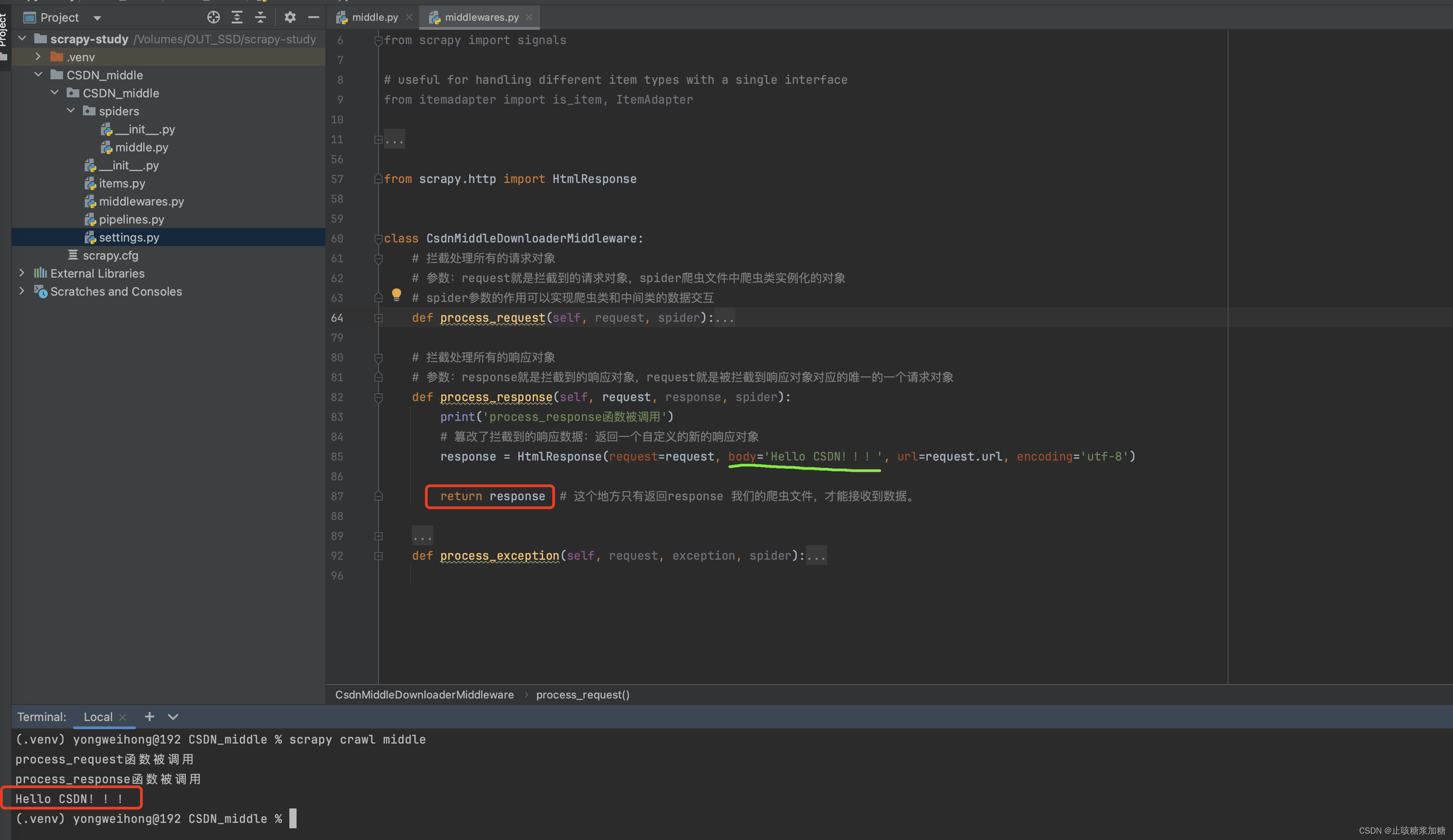
3:process_response 拦截修改响应
1:修改响应数据
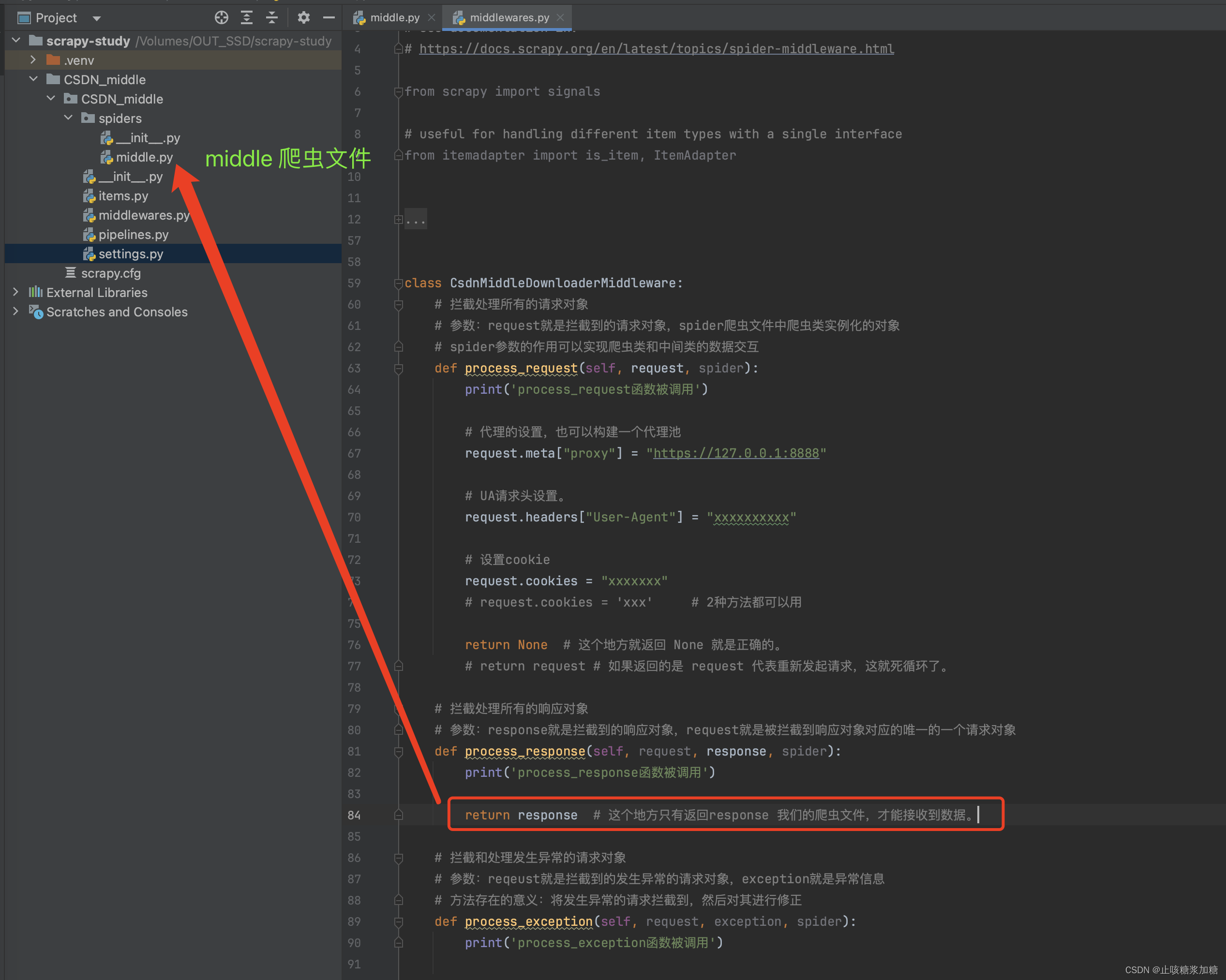
补充:return返回值
4、process_exception 拦截错误
5、spider的作用 (数据交互)

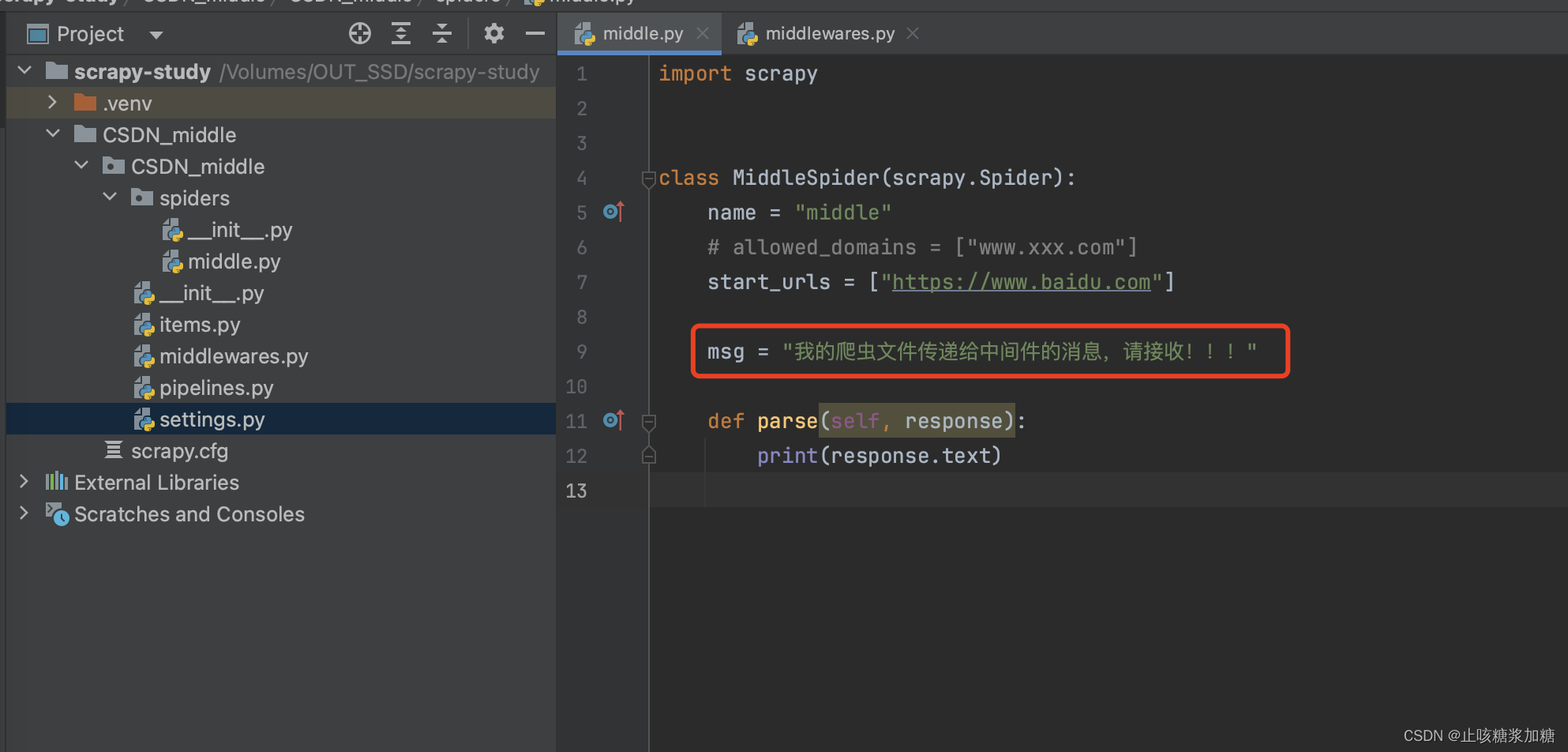
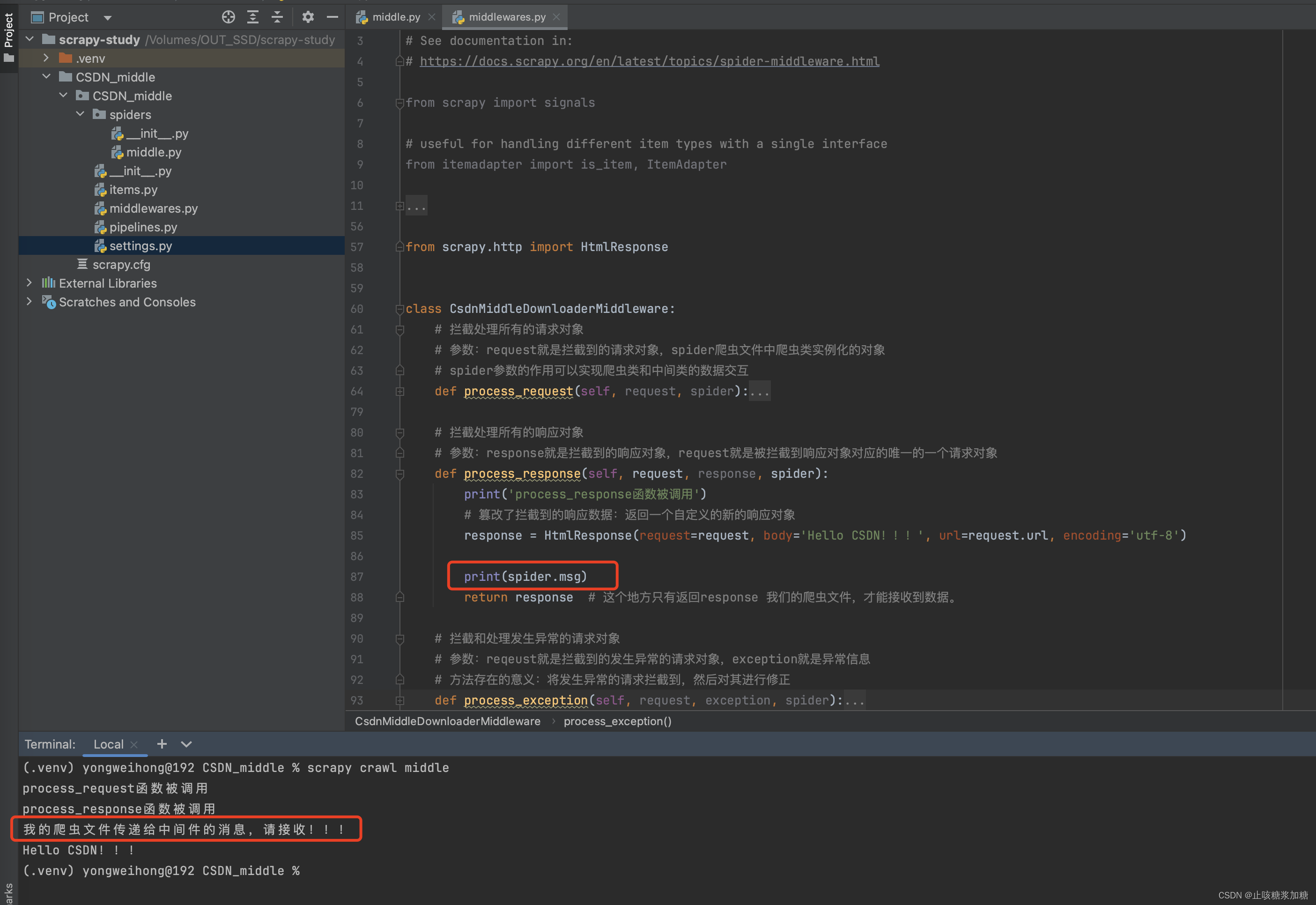
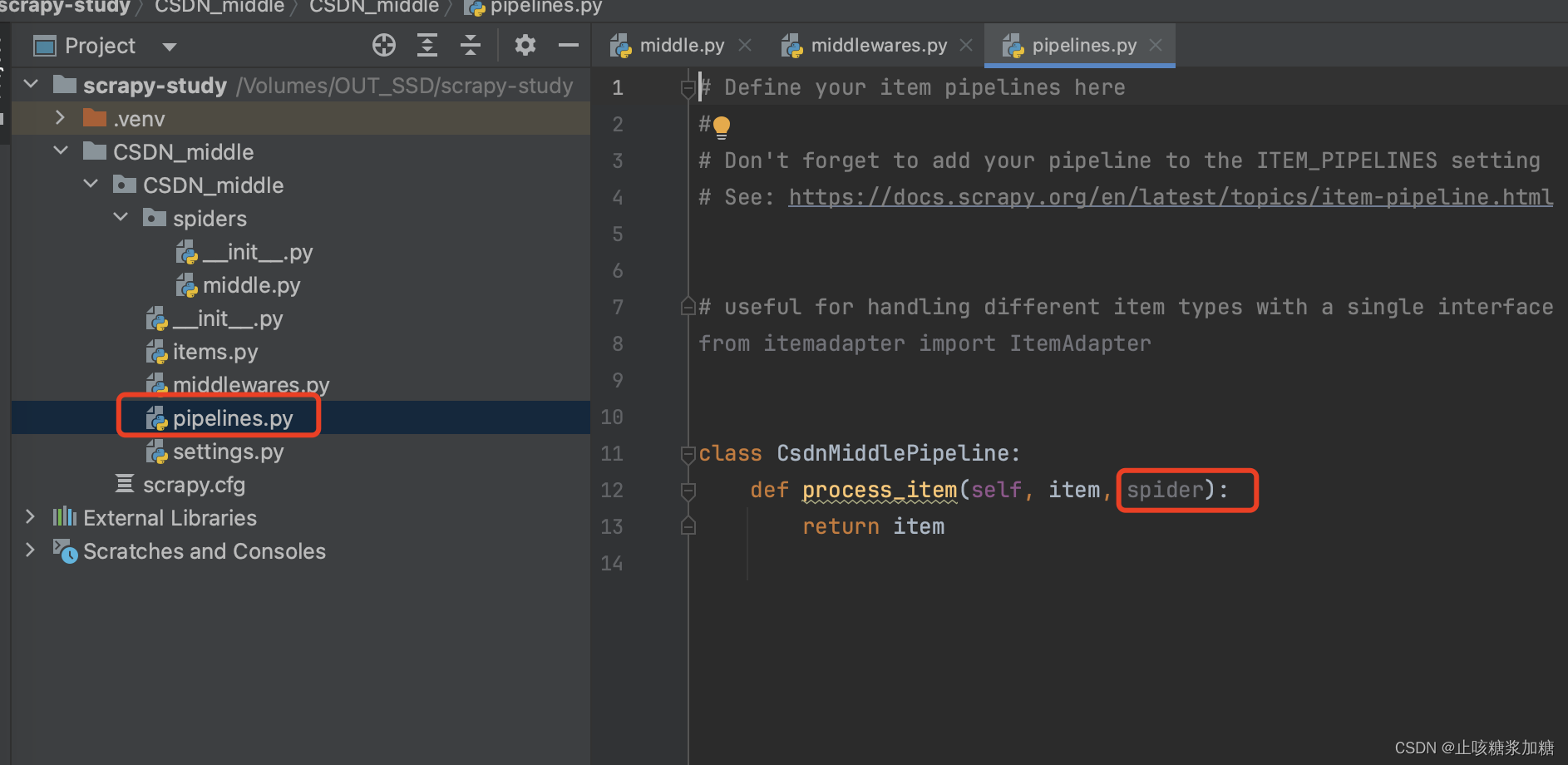
补充:管道中 spider 作用
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。