本文介绍: 一个健壮的、安全的开放平台的架构设计,必然会针对对外开放的API接口进行速率限制,来保证整体系统的可用性,OpenAI对外的API也不例外,我们可以简单的从官方发现API使用量的限制。【API Doc上的限制】【个人账户里的速率限定以及当前所处的等级】限定方式速率限制有五种衡量方式:每分钟请求数(RPM,requests per minute)每天请求数(RPD,requests per day)…
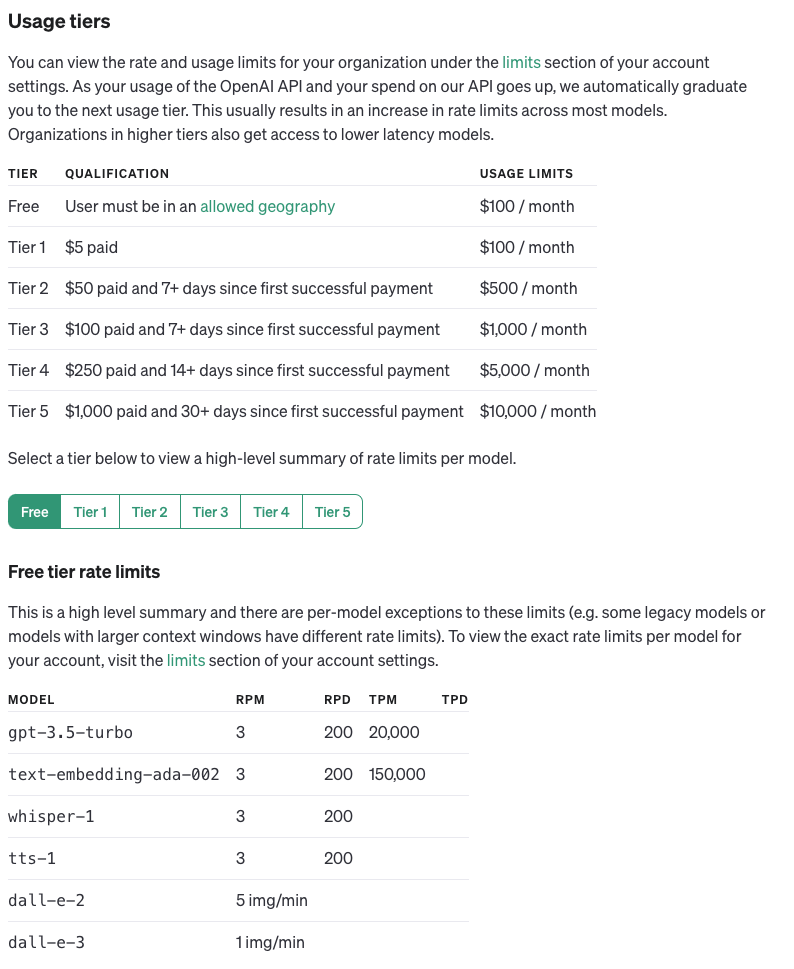 【API D
【API D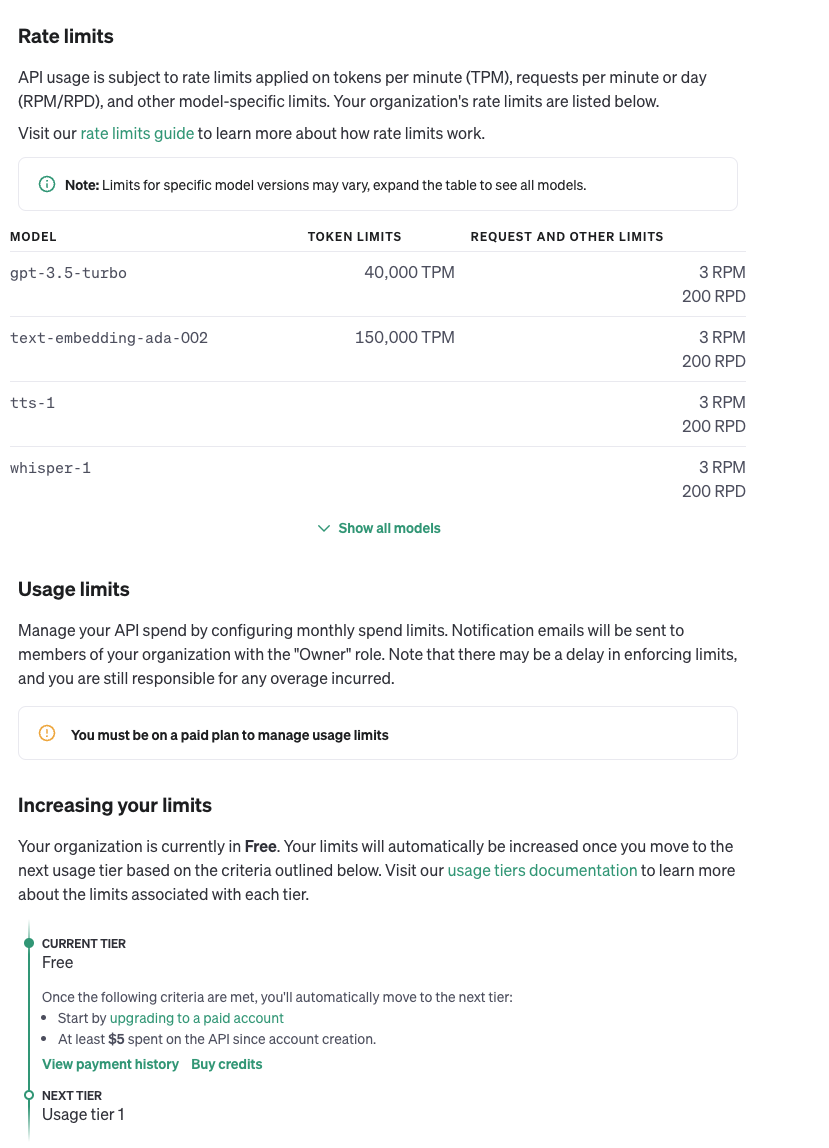 【个人账户里的
【个人账户里的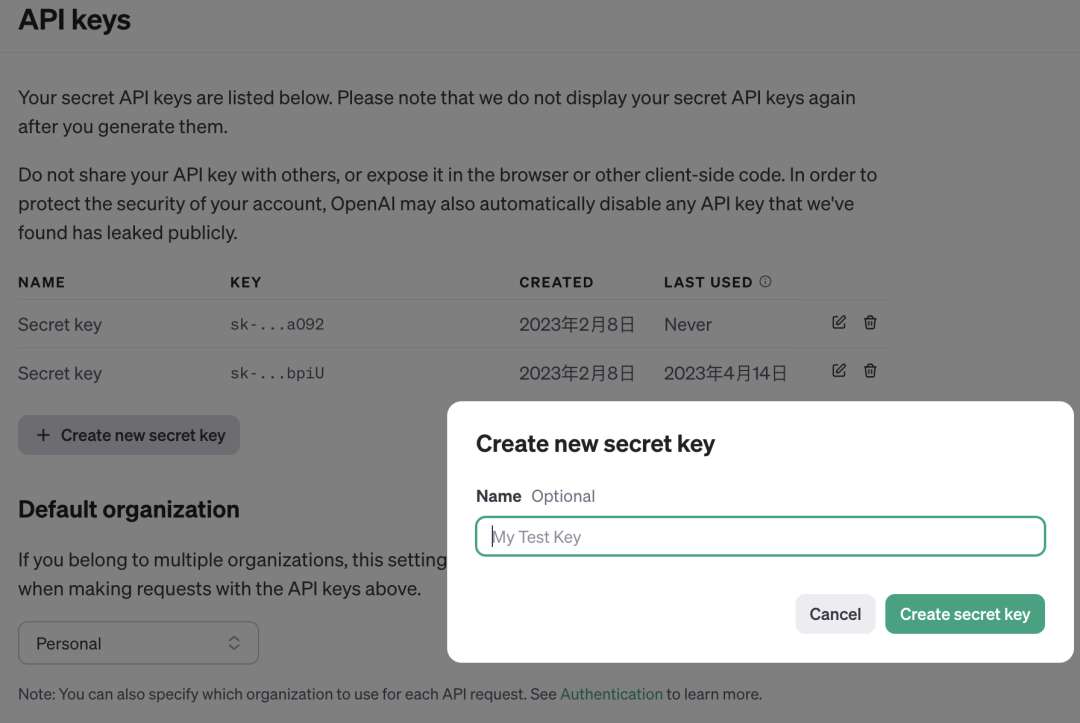 在使用 O
在使用 O声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。