# 浅析Hotspot的经典7种垃圾收集器原理特点与组合搭配
HotSpot共有7种垃圾收集器,3个新生代垃圾收集器,3个老年代垃圾收集器,以及G1,一共构成7种可供选择的垃圾收集器组合。
新生代与老年代垃圾收集器之间形成6种组合,每个新生代垃圾收集器都对应2种组合。
新生代垃圾收集器
所有新生代垃圾收集器,都使用复制算法,都会发生stop–the–world。由于绝大多数对象的生命周期通常比较短,在新生代被回收的可能性很大,新生代的垃圾回收通常可以回收大部分对象,因此采用复制算法效率更高。
Serial
采用复制算法,GC时发生stop–the–world,使用单个GC线程。
“Serial” is a stop-the–world, copying collector which uses a single GC thread.
特点:
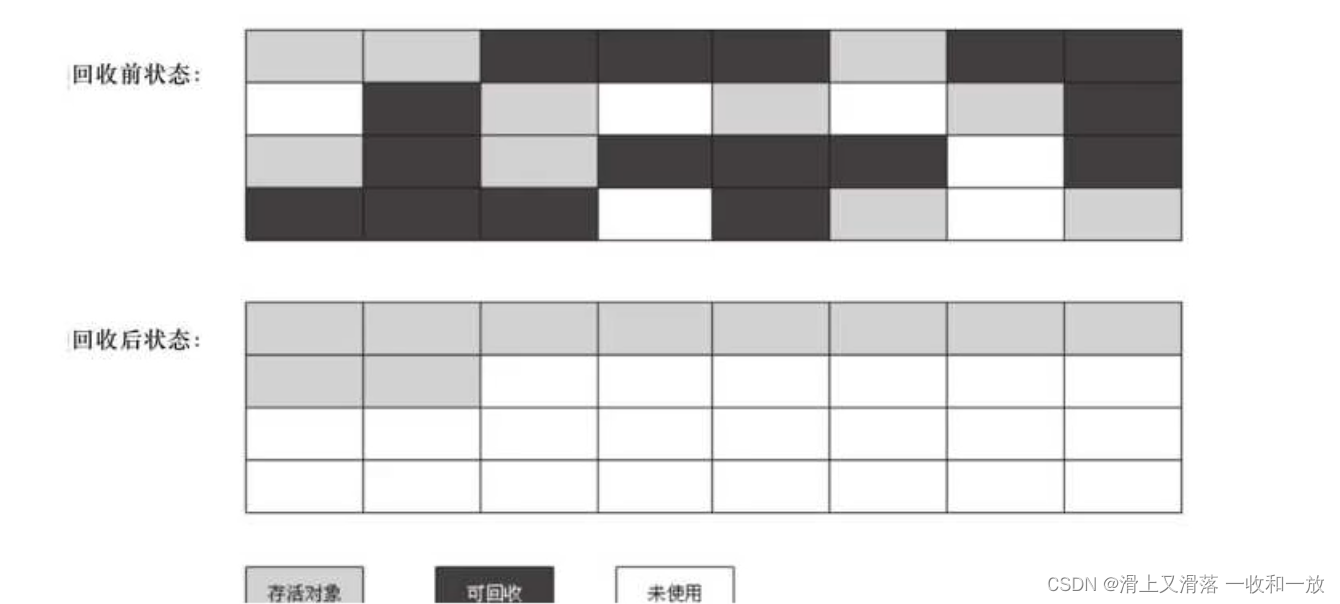
⠀Serial/Serial Old收集器协同工作运行示意图如下:

ParNew
采用复制算法,GC时发生stop-the-world,使用多个GC线程。
ParNew 与 Parallel Scavenge的一个主要区别是,ParNew可以与CMS进行搭配使用。
“ParNew” is a stop–the-world, copying collector which uses multiple GC threads. It differs from “Parallel Scavenge” in that it has enhancements that make it usable with CMS. For example, “ParNew” does the synchronization needed so that it can run during the concurrent phases of CMS.
特点:

Parallel Scavenge
老年代垃圾收集器
Serial Old

Parallel Old

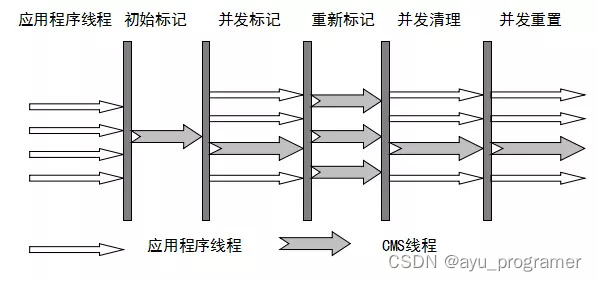
CMS

G1


G1 收集器与 CMS 收集器的异同
垃圾回收器器组合搭配
Serial Old(MSC)可以与所有新生代收集器进行组合,共3种组合
-XX:+UseSerialGC
-XX:+UseParNewGC
-XX:+UseParallelGC
Parallel Old(带压缩)只能与Parallel Scavenge进行组合
-XX:+UseParallelOldGC
CMS(不带压缩)可以与Serial和ParNew进行组合,共2种组合
-XX:-UseParNewGC -XX:+UseConcMarkSweepGC
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
G1(Garbage First),不需要搭配其他垃圾收集器
6种垃圾收集组合关系图


推荐使用的2种GC组合
1.基于低停顿时间的垃圾收集器
2.基于吞吐量优先的垃圾收集器

总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。