本文介绍: 例如:要找出网站活跃的前10名用户,活跃用户的评测标准就是用户在当前季度中登录网站的天数最多,如果某些用户在当前季度登录网站的天数相同,那么再比较这些用户的当前登录网站的时长进行排序,找出活跃用户。1、默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。2、在workr上启动多个Executor,设置—executor–cores参数指定每个executor使用的core数量。3、内存不足的情况下启动core的情况。
一、Spark资源调度源码
1、Spark资源调度源码过程
Spark资源调度源码是在Driver启动之后注册Application完成后开始的。Spark资源调度主要就是Spark集群如何给当前提交的Spark application在Worker资源节点上划分资源。Spark资源调度源码在Master.scala类中的schedule()中进行的。
2、Spark资源调度源码结论
3、资源调度源码结论验证
使用Spark-submit提交任务演示。也可以使用spark–shell来验证。
1、默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
2、在workr上启动多个Executor,设置–executor-cores参数指定每个executor使用的core数量。
3、内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
–total-executor-cores集群中共使用多少cores
二、Spark任务调度源码
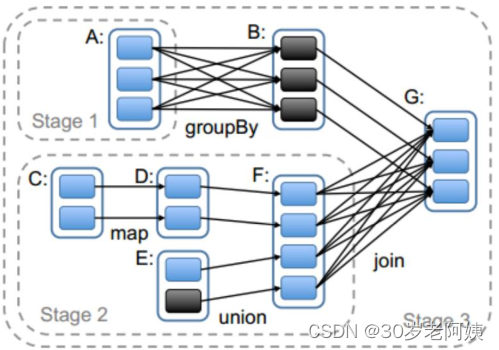
三、Spark二次排序和分组取topN
1、二次排序
2、分组取topN
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。