什么是缓存
缓存就是数据交换的缓冲区,是存储数据的临时地方,一般读写性能较高。
缓存的成本:
Redis特点
- 键值型数据库,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性(在Redis6.0版本之后,采用多线程处理网络请求,核心部分仍是单线程)
- 低延迟,速度快(基于内存,IO多路复用,采用C语言编写)
- 支持数据持久化(定期将内存中的数据持久化到磁盘中)
- 支持主从集群,分片集群
- 支持多语言客户端
与MySQL的对比
|
MySQL |
||
|
非结构化 |
||
|
关联的 |
无关联的 |
|
|
SQL查询 |
非SQL |
|
|
ACID |
BASE |
|
|
水平 |
||
Redis实现缓存
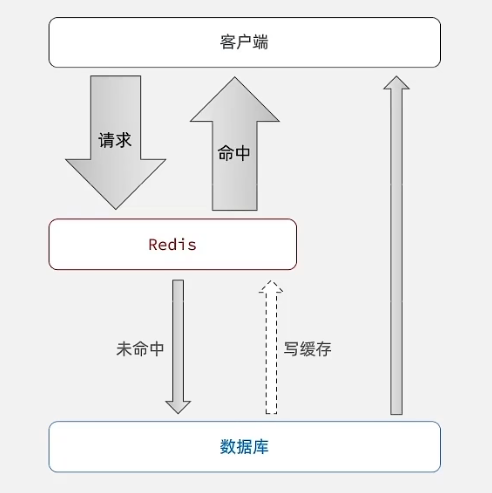
缓存更新策略
|
内存淘汰 |
超时提出 |
主动更新 |
|
|
一致性 |
差 |
好 |
|
|
维护成本 |
无 |
低 |
高 |
主动更新策略
直接更新缓存:每次更新数据库时都会进行修改,当写多读少时,无效写操作过多。
这涉及到多线程并发问题,接下来查看先删除缓存再操作数据库可能会出现的情况。正常情况下如下所示

但是如果在线程1更新数据时有其他线程开始执行查询操作,就会变成如下情况,这样会导致Redis中保存的数据仍然是旧数据,从而产生数据不一致问题。

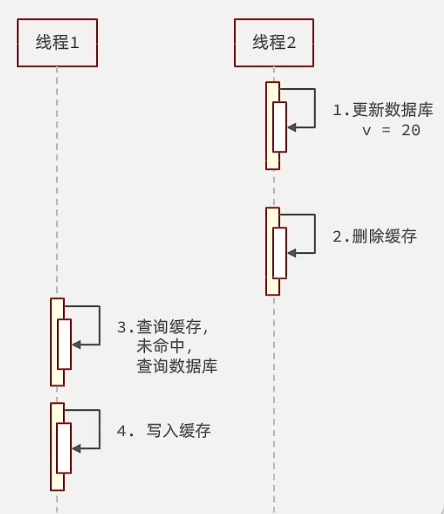
但也可能存在如下一种情况,假设线程1先查询缓存,但是由于缓存已经失效,比如说过期或是Redis中不存在,但是就在从数据库写入缓存前线程2开始执行,从而导致写入缓存的仍然是旧数据。

即使这两种情况都会产生数据不一致的问题,但是总体来说先操作数据库后删除缓存出现数据不一致的概率要低于先删除缓存再更新数据库。因为如果先删除缓存的话,是一个微秒级别的操作,而更新数据库相对来说耗时比较久。在此之间可能会存在其他线程开始查询缓存并查询数据库写入缓存的问题。
但如果先更新数据库,期间即使有其他线程查询数据库并更新缓存执行,最后也会被更新数据库后的删除缓存操作将旧数据删除。其次,查询数据库操作耗时短,其他线程恰好开始更新数据库的概率低。
读操作:
写操作:
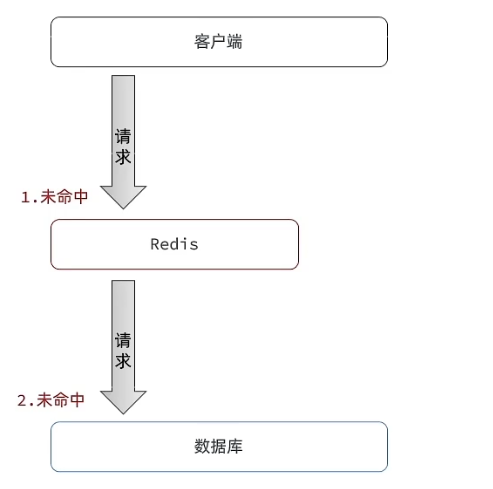
缓存穿透
指查询一个数据库一定不存在的数据,最终导致所有请求打在数据库上,导致数据库压力变大。模型图如下
缓存空对象
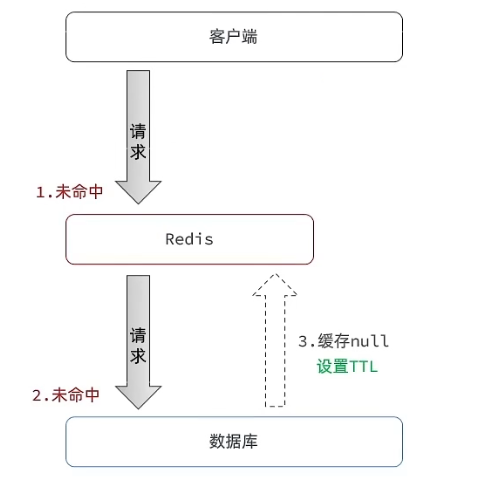
即使查不到数据,也返回一个key为提交的数据,value为null的数据给缓存,并设置一个存活时间。
缺点是额外的内存消耗,可能造成短期的不一致,如果无法忍受数据不一致情况,可以在更新数据库时主动将数据更新到缓存当中。
布隆过滤器
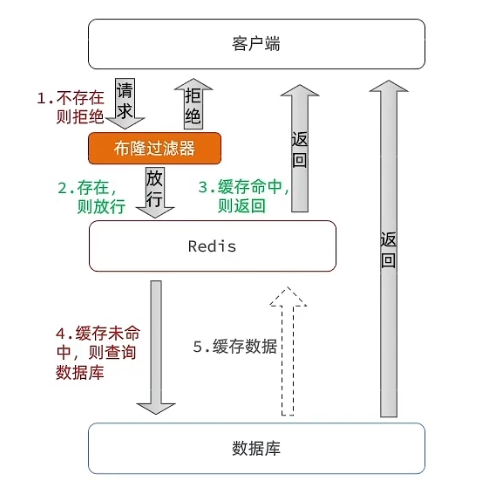
查询时先通过布隆过滤器判断数据是否存在,如果不存在直接拒接,存在的话才会访问Redis或数据库,布隆过滤器实际上是一个算法,将数据库中存在的数据通过哈希算法得到哈希值然后转化为二进制位保存在布隆过滤器当作,当客户端请求发起时,通过判断请求的数据在布隆过滤器对应的位置是0还是1。
缺点是实现复杂,存在误判。判断没有的数据一定没有,判断存在但不一定真的存在,还是存在一定穿透的问题。
设置id格式,然后进行基础格式校验,格式不对不进行查询。给用户进行权限设置。
缓存雪崩
指在一个时间段,缓存集中过期失效,在失效的时间段中,所有的访问查询都由数据库来操作,产生周期性的压力波峰。模型图如下

设置不同TTL:将缓存的数据设置不同的失效时间,避免在同一时间集中失效,对于热门的数据,存活时间长一点甚至可以设置永不过期。
设置Redis集群:为了防止Redis宕机造成的雪崩,要建立Redis集群,从而提高Redis的高可用性。
添加降级处理:当发现Redis出现故障时,应该进行快速失败,而不应该交给服务器处理。
添加多级缓存:在浏览器、Nginx或是JVM内部进行缓存,而不是单单只在Redis中进行缓存
缓存击穿
也叫热点key问题。是指一个key非常热点,在不停扛着大并发,大并发集中对于一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求到数据库上。模型图如下
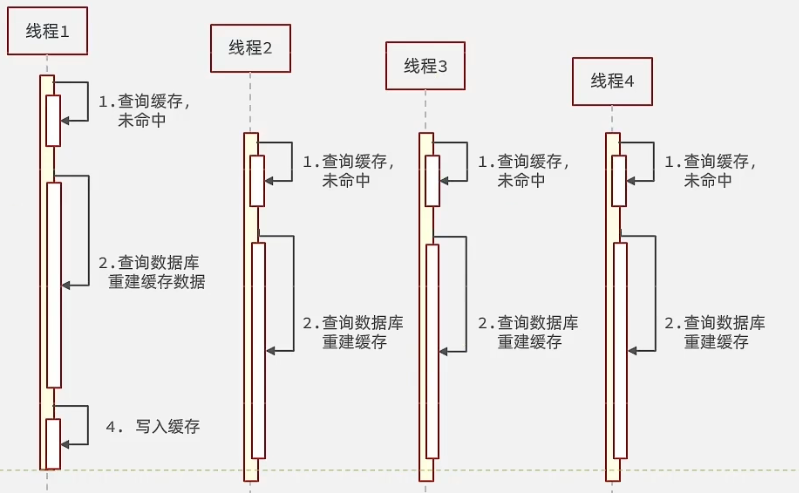
互斥锁
模型图如下

同一时刻只需要一个线程对数据库访问就可以了,其他线程获取不到锁就休眠一会再去Redis进行查询。
缺点:线程需要等待,会影响性能。当一个线程需要获取多个锁时可能存在死锁风险。
逻辑过期
模型图如下
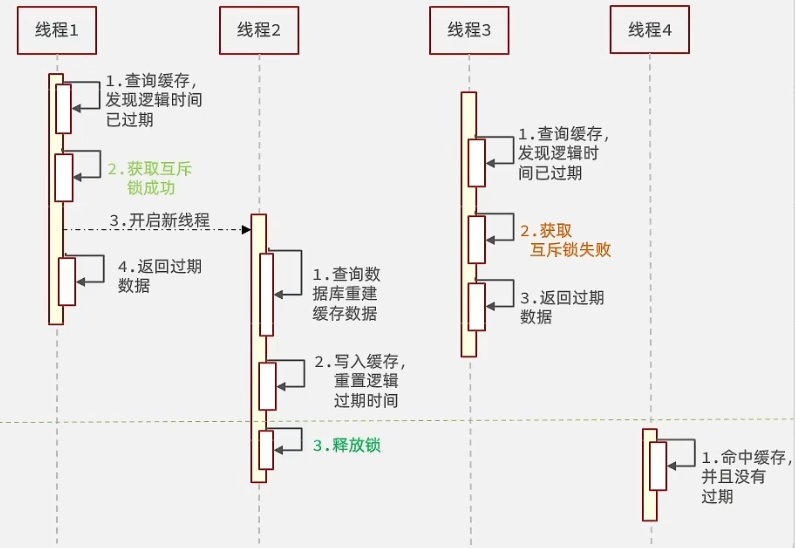
不设置TTL的过期时间,而是存储再Value中,如果逻辑时间过期了,那么由一个线程拿到互斥锁后开辟一个新线程去进行数据库查询,重建缓存。其余线程仍然使用逻辑上的旧数据。
原文地址:https://blog.csdn.net/zmbwcx/article/details/134758410
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_40868.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!