1. 函数功能
读取excel文件,支持读取xls,xlsx,xlsm等类型的EXCEL文件。能够读取一个sheet表或多个sheet表
2. 函数语法
3. 函数参数
3.1 读取文件
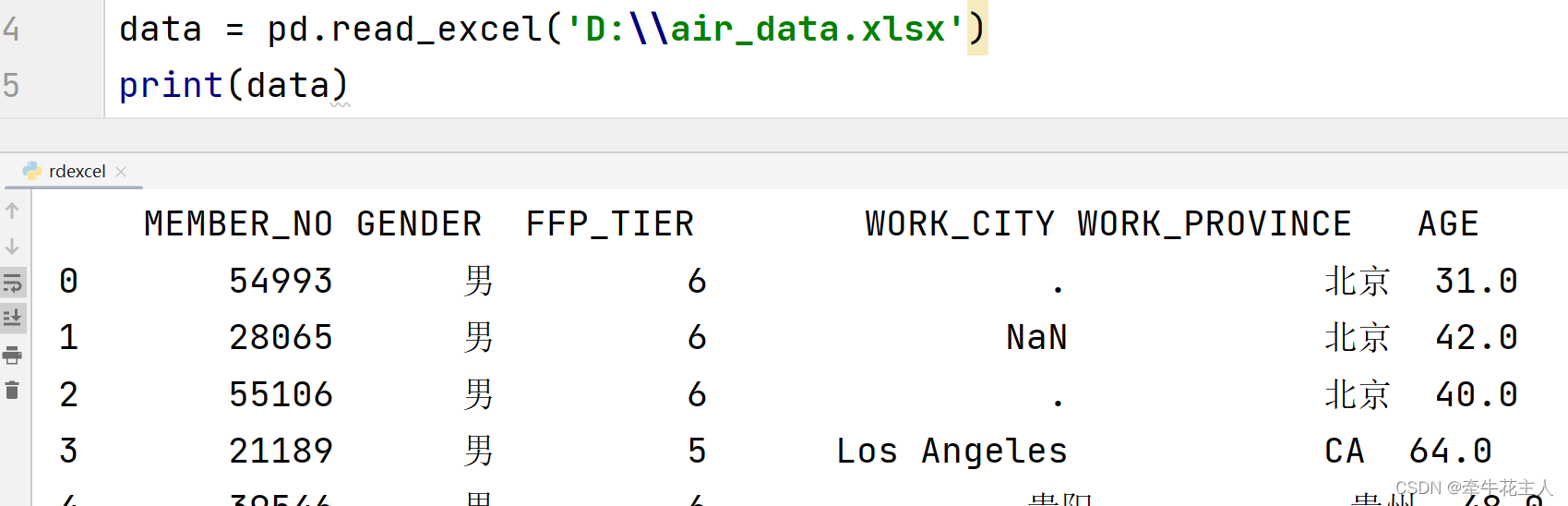
3.1.1 默认读取第一个sheet表
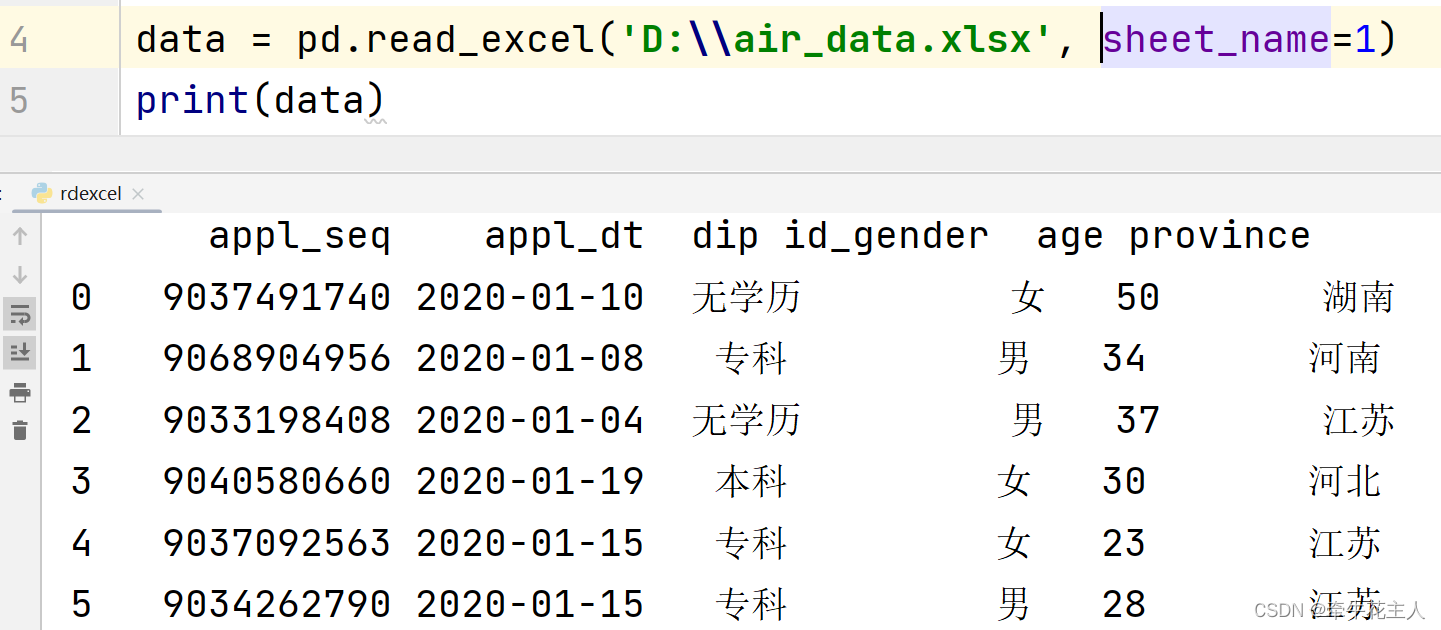
3.1.2 指定读取文件的索引
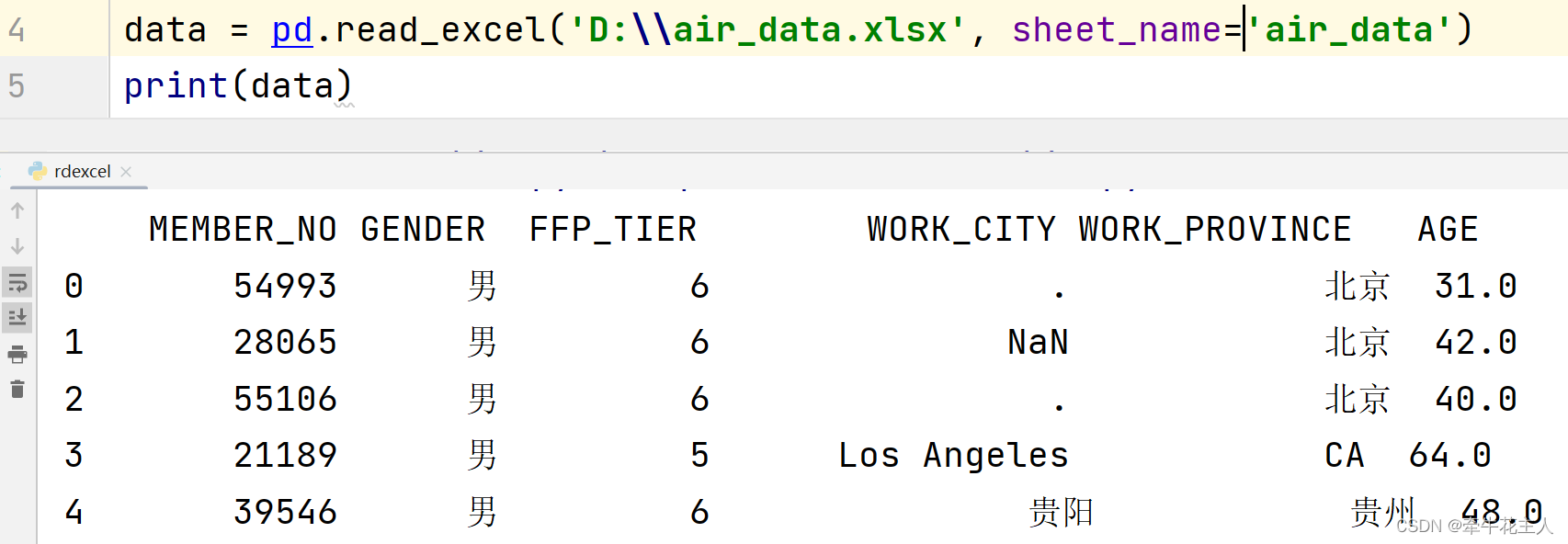
3.1.3 指定读取文件的名字
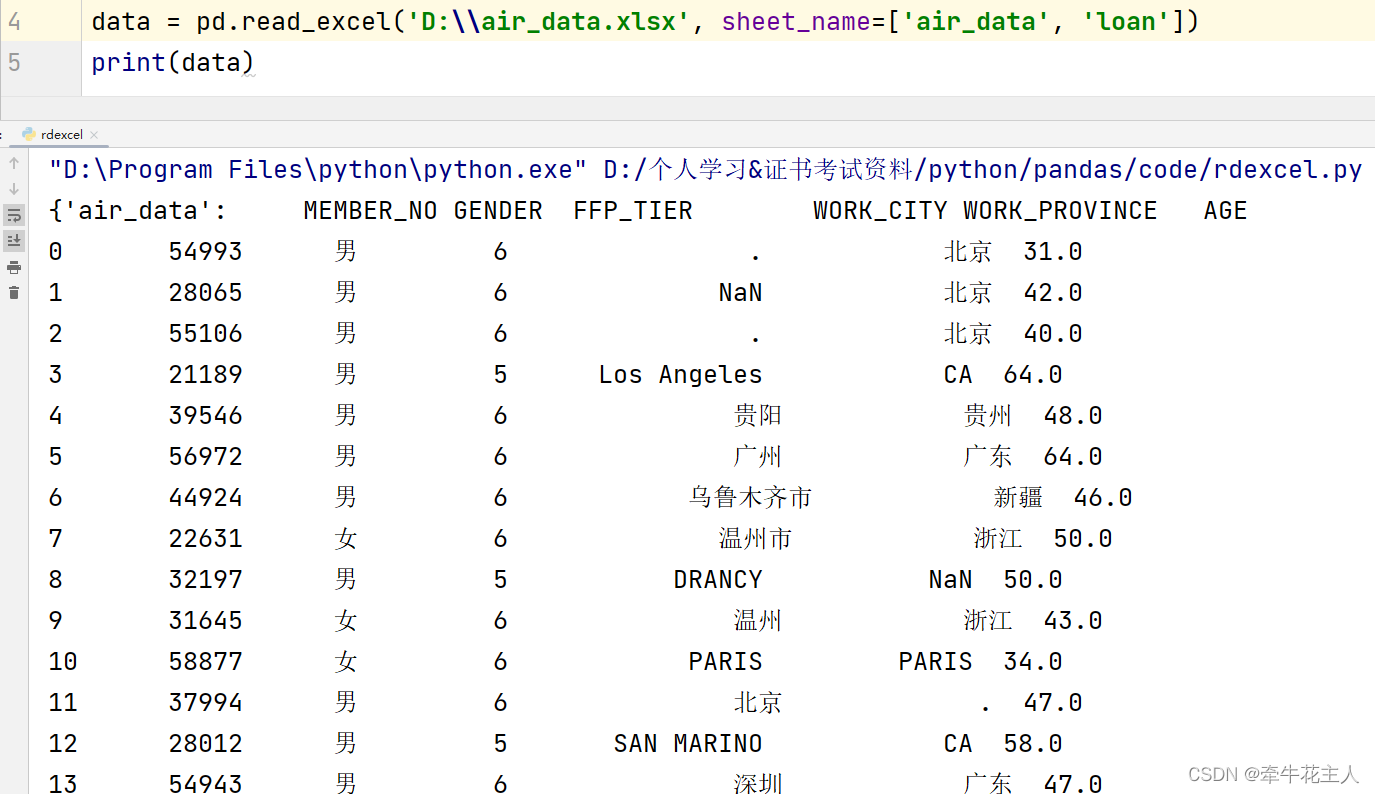
3.1.4 读取多个文件
可以使用文件名或文件索引组成的列表或者sheet_name=None:
读取的内容将: 以DataFrame组成的字典形式展示
3.2 其他常用参数
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[office] sumifs函数和sump #媒体#学习roduct哪个运算更快–Excel函数 #职场发展#媒体](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)