本文介绍: 一直以来对科学研究有两大范式,第一个是以数据驱动的开普勒范式。第二个是以第一性原理驱动的牛顿范式。开普勒范式是通过观察、总结的方式,研究事物的规律,开普勒范式三大定律就是通过不断的天文观测,前人积累的天文经验总结出来的。开普勒范式属于数据驱动,通过观察事物的现象,总结规律,然后拿它解决实际的问题。这种方式解决问题有一个缺点,可能会出现知其然不知所以然的情况,很难泛化。牛顿范式是从事物的本质出发,通过第一性原理,发现事物的规律。牛顿范式属于模型驱动,模型驱动比较准确,但因为计算的量大,很难用以解决实际的问题。
2020 年末,谷歌旗下 DeepMind 研发的 AI 程序 AlphaFold2 在国际蛋白质结构预测竞赛上取得惊人的准确度,使得 “AI 预测蛋白质结构” 这一领域受到了空前的关注。今天我们邀请到同领域企业,深势科技为大家分享其搭建基础平台时的实践与思考。AI 场景中的使用的数据有哪些新特点?混合云架构如何与超算平台结合?为何会选择 JuiceFS?
背景
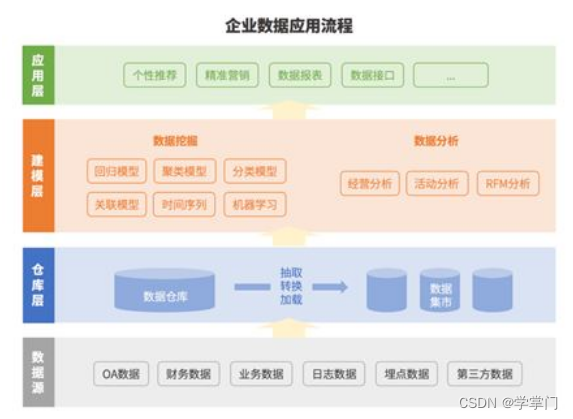
深势科技成立于 2018 年,是 “AI for Science” 科学研究范式的先行者,致力于运用人工智能和分子模拟算法,结合先进计算手段求解重要科学问题,为人类文明最基础的生物医药、能源、材料和信息科学与工程研究打造新一代微尺度工业设计和仿真平台。
新一代分子模拟技术,是深势科技研究问题的本质方法;高性能计算、机器学习、科学计算方法,这些是研究分子模拟技术的一些工具和手段。
Hermite 和 Bohrium 是针对不同行业领域的解决方案,Hermite 是针对药物研发领域的一个计算设计平台, Bohrium 是针对材料和科学领域的微尺度计算设计平台,Lebesgue 是任务调度和算力编排平台。
什么是 AI for Science
一直以来对科学研究有两大范式,第一个是以数据驱动的开普勒范式。第二个是以第一性原理驱动的牛顿范式。
AI for Science 范式如何解决科学原理工程化问题
混合云架构的选择与挑战
为什么选择混合云架构
混合云架构的挑战
云与超算融合的探索
存储架构的思考与实践
存储诉求
方案选型 & JuiceFS 测试
总结与展望
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[EFI]ThinkPad-X13-Gen1电脑 Hackintosh 黑苹果efi引导文件](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)