前期准备
随便找个网站进行爬取,这里我选择的是(一个卖书的网站)
https://www.bookschina.com/24hour/62700000/

探索该网页的HTML码的特点
在该网页右键,选择检查,就可以看到下面的样子
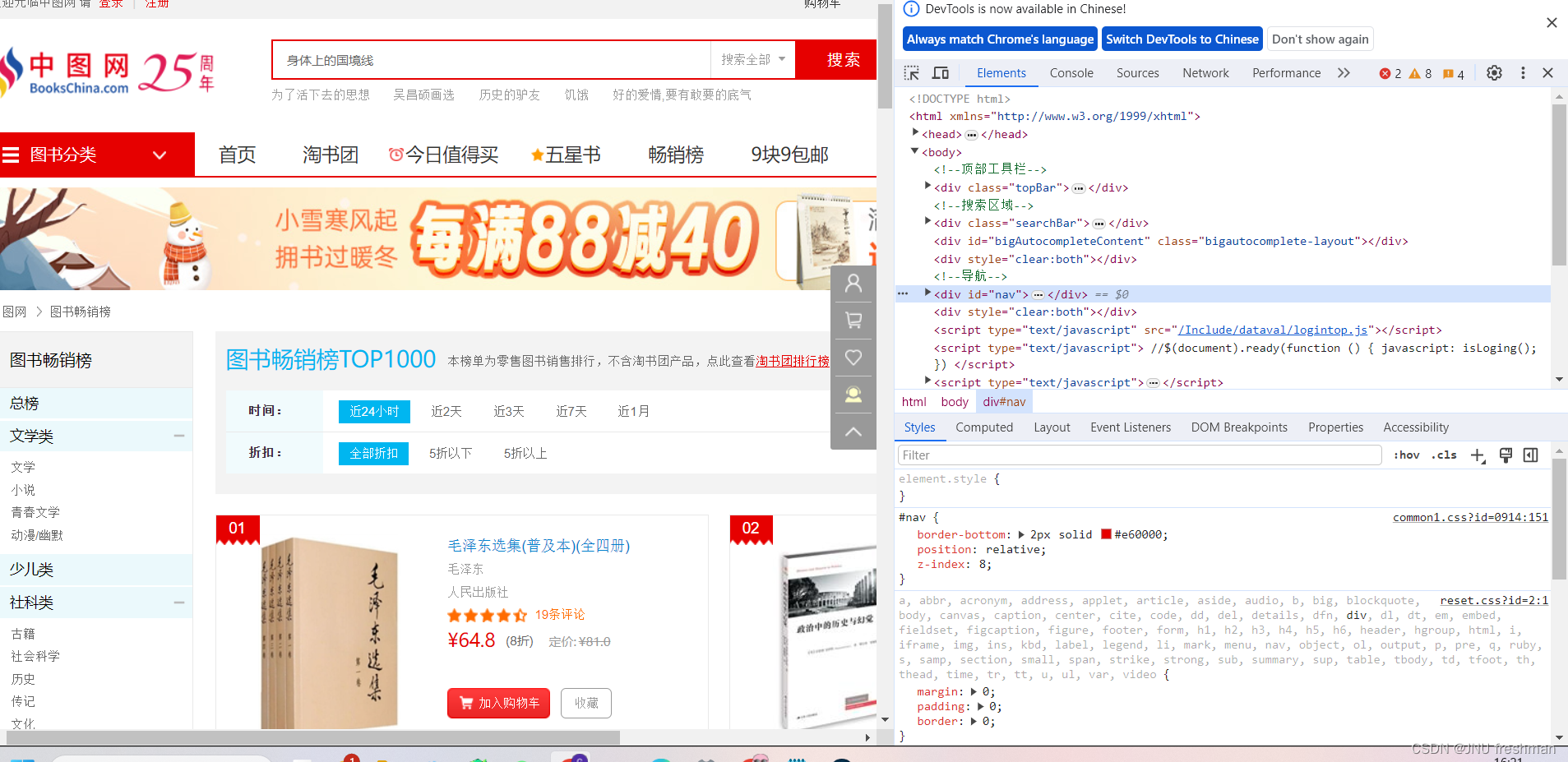
然后按下面图片的第一个按键(作用是:当你鼠标停留在网页时,会自动显示到对应的网页代码)

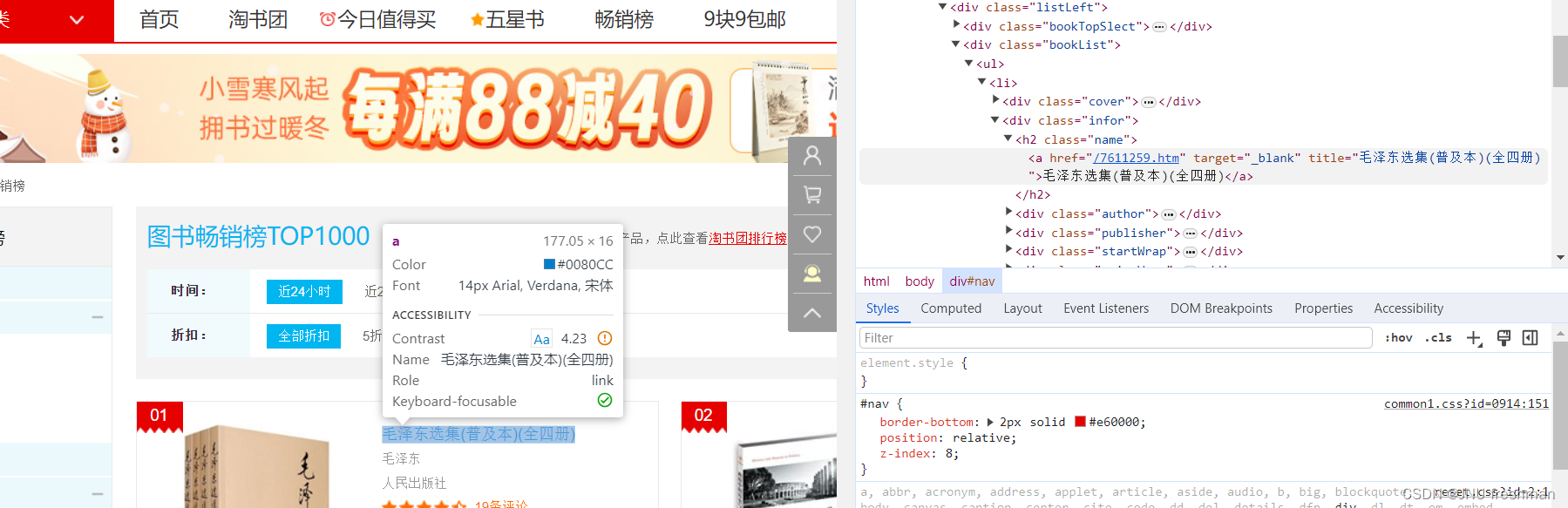

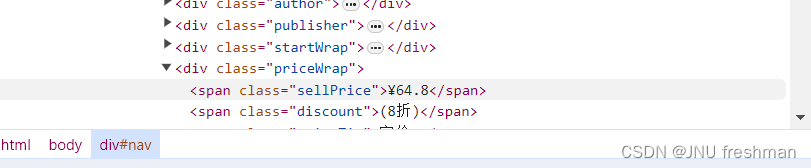
我们发现,书名是位于<h2 class = "name" >标签的 <a >标签里面的
开始编写代码
存入文件
总的程序
文件存储效果

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。