本文介绍: Apache Flink 的前身是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了Apache Software Foundation的顶级项目之一。2019 年 1 年,阿里巴巴收购了 Flink 的母公司 Data Artisans,并宣布开源内部的 Blink,Blink 是阿里巴巴基于 Flink 优化后的版本,增加了大量的新功能,并在性能和稳定性上进行了各种优化,经历过阿里内部多种复杂业务的挑战和检验。Flink 是一个分布式的流处理。
一、Flink 简介
Apache Flink 的前身是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了Apache Software Foundation的顶级项目之一。2019 年 1 年,阿里巴巴收购了 Flink 的母公司 Data Artisans,并宣布开源内部的 Blink,Blink 是阿里巴巴基于 Flink 优化后的版本,增加了大量的新功能,并在性能和稳定性上进行了各种优化,经历过阿里内部多种复杂业务的挑战和检验。
Flink 是一个分布式的流处理框架,它能够对有界和无界的数据流进行高效的处理。
二、Flink 组件栈
Flink 采用分层的架构设计,从而保证各层在功能和职责上的清晰。如下图所示,由上而下分别是 API & Libraries 层、Runtime 核心层以及物理部署层:
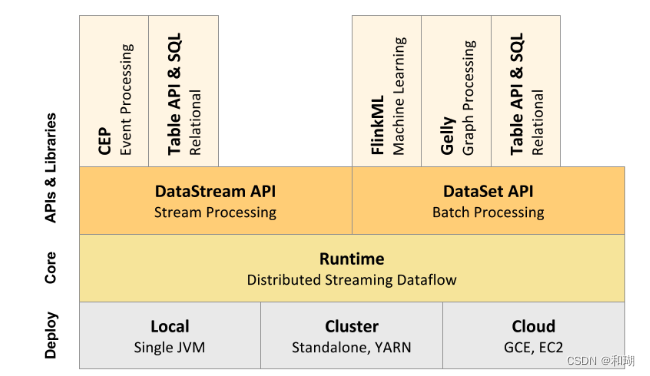
1. API & Libraries 层
这里的API可以进行更具体的划分
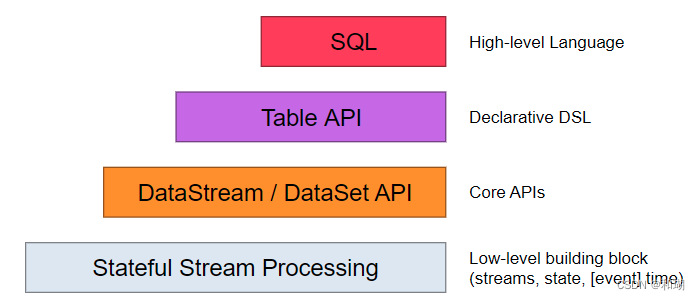
API 的一致性由下至上依次递增,接口的表现能力由下至上依次递减
2. runtime层
3. 物理部署层
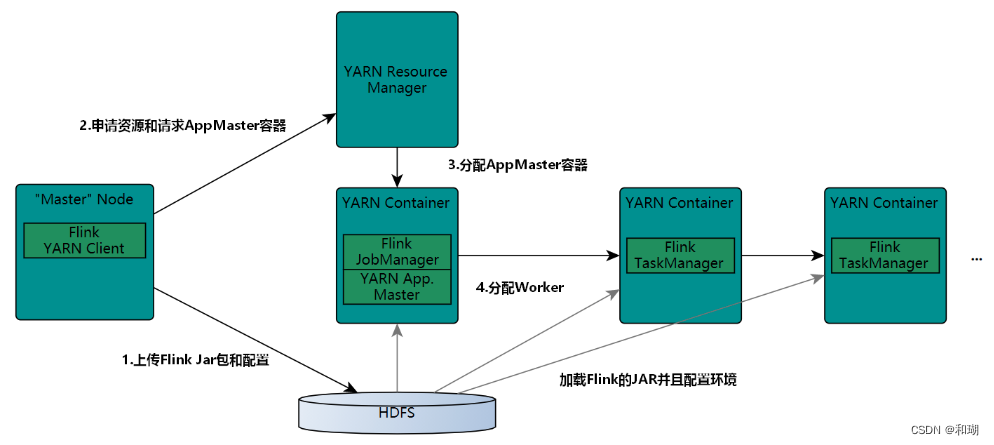
三、Flink 集群架构
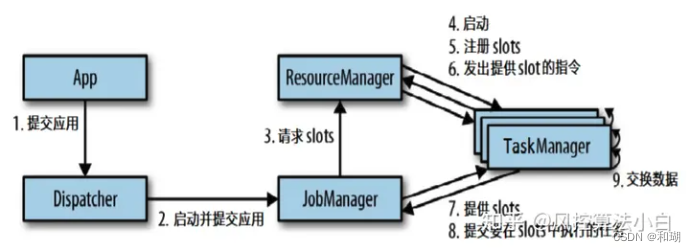
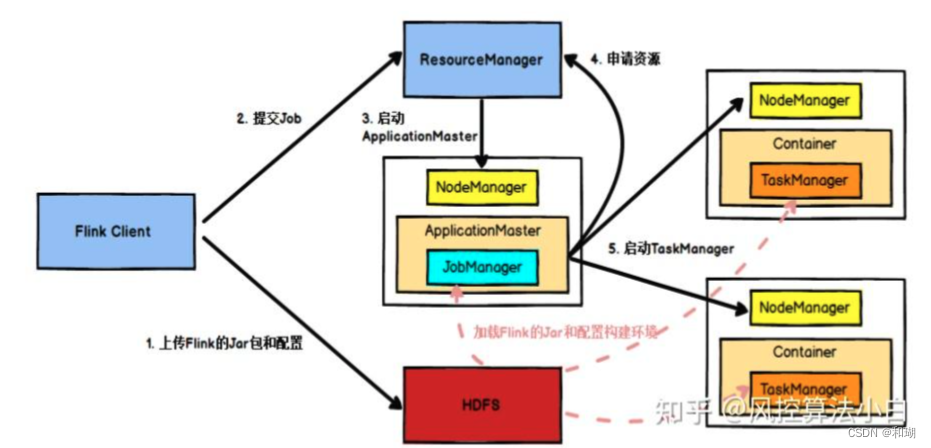
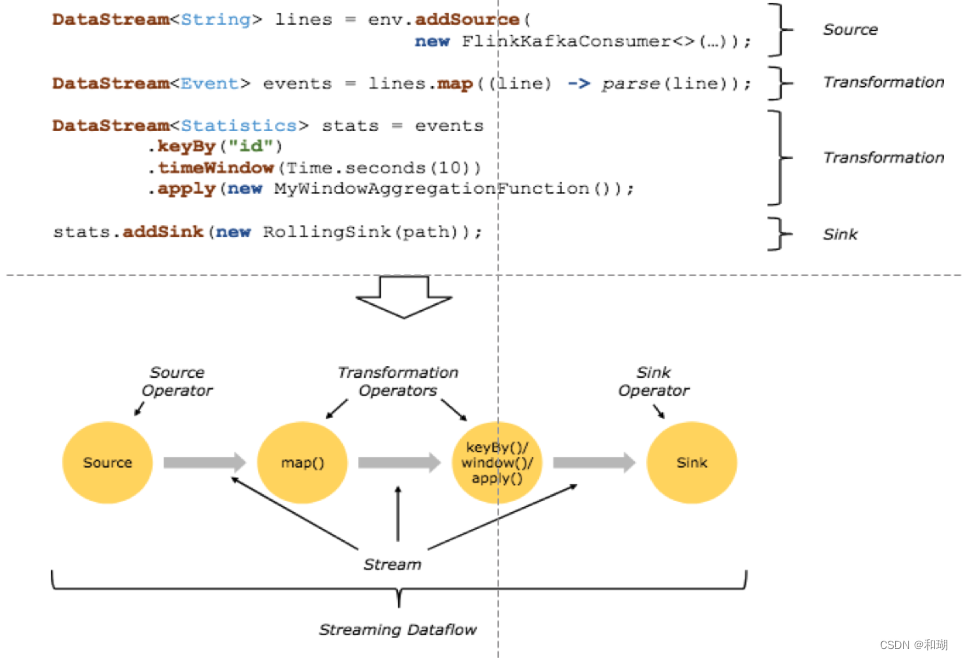
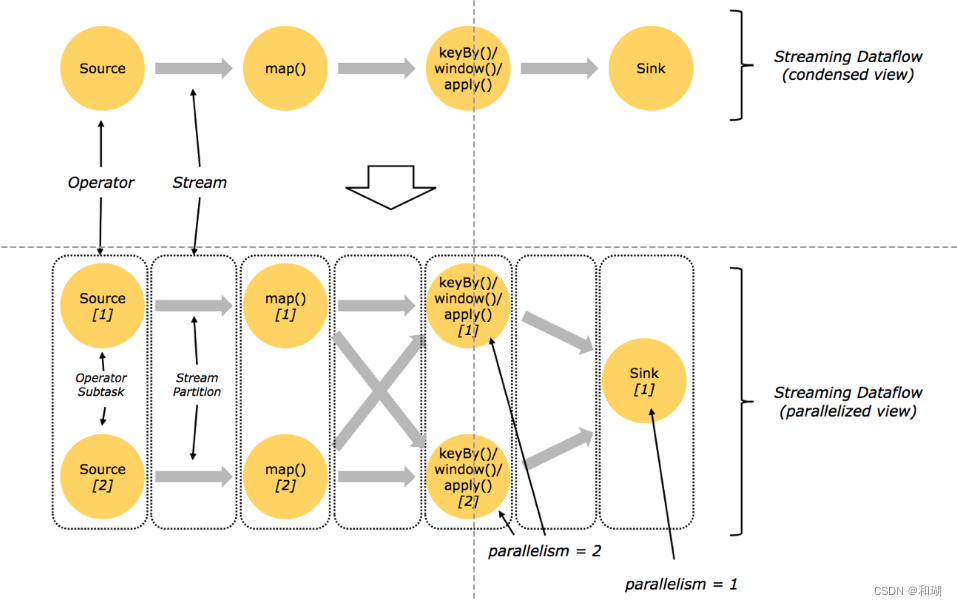
四、Flink基本编程模型
五、Flink 的优点
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。