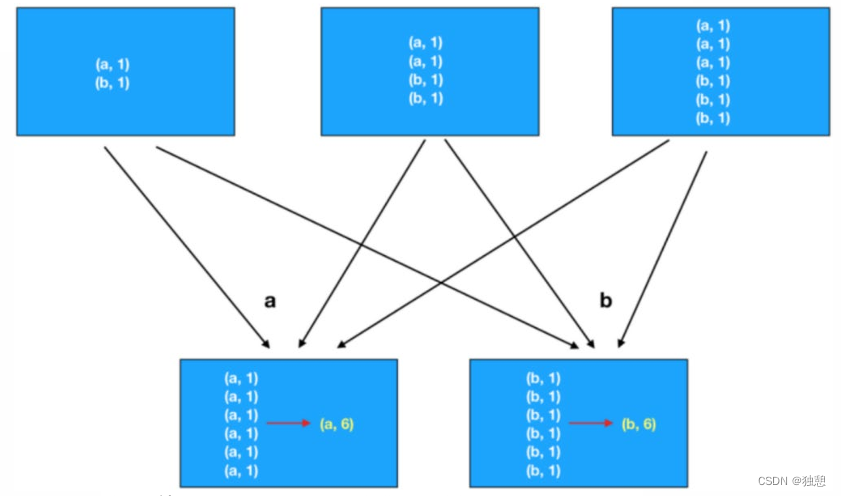
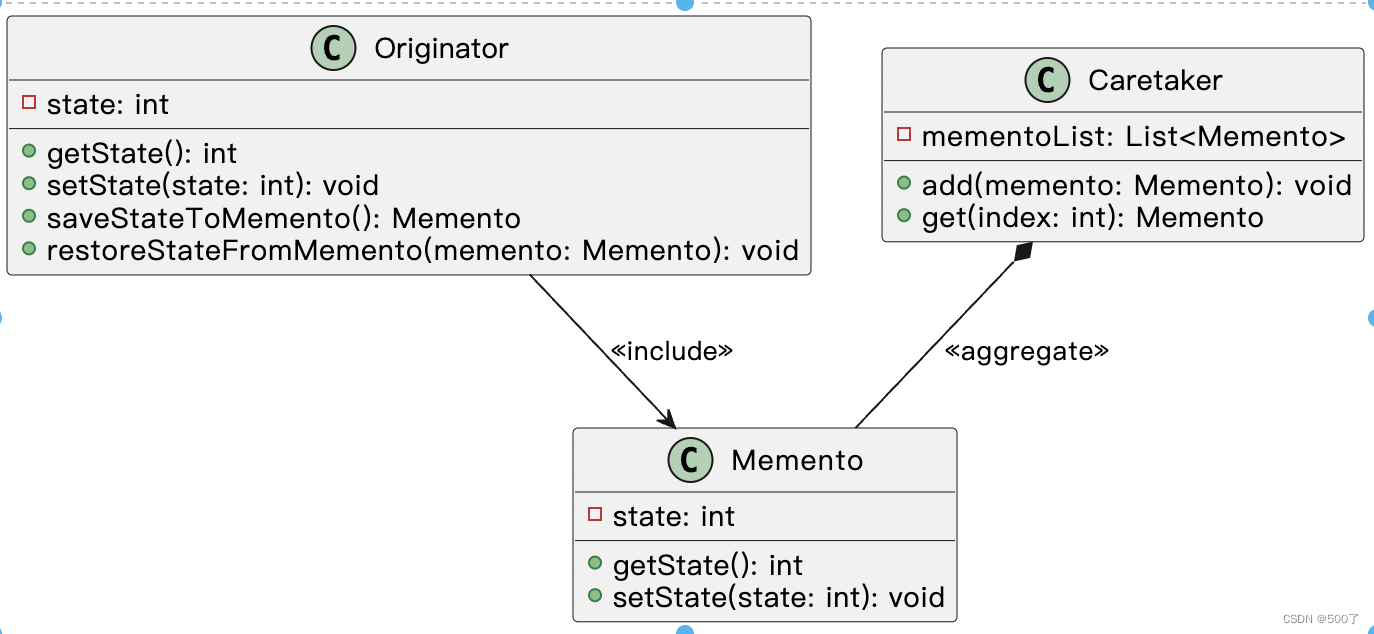
一、状态概念
在流处理中有很多操作只依赖独立的事件即可,有的操作不仅需要依赖当前事件还要依赖前序事件。这样flink的算子就分为无状态算子和有状态算子。
flink对算子的状态保存不仅可以实现更多高级特性,还可以通过状态的保存和恢复来实现容错。
二、状态实现
1.状态触发
2.状态存储实现
Flink内置了两个状态存储实现HashMapStateBackend和EmbeddedRocksDBStateBackend,默认使用HashMapStateBackend。
2.1 HashMapStateBackend
状态数据以Java对象的形式存储在JVM堆中,状态快照可以持久化到文件系统或者Job Manager的堆中。
2.2 EmbeddedRocksDBStateBackend
2.3 状态存储对比
3.设置状态存储实现
3.1 单个作业设置
3.2 全局设置
三、容错机制
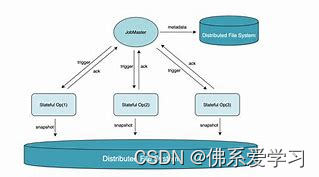
1.状态快照
2.状态快照生成
3.Checkpoint Barrier
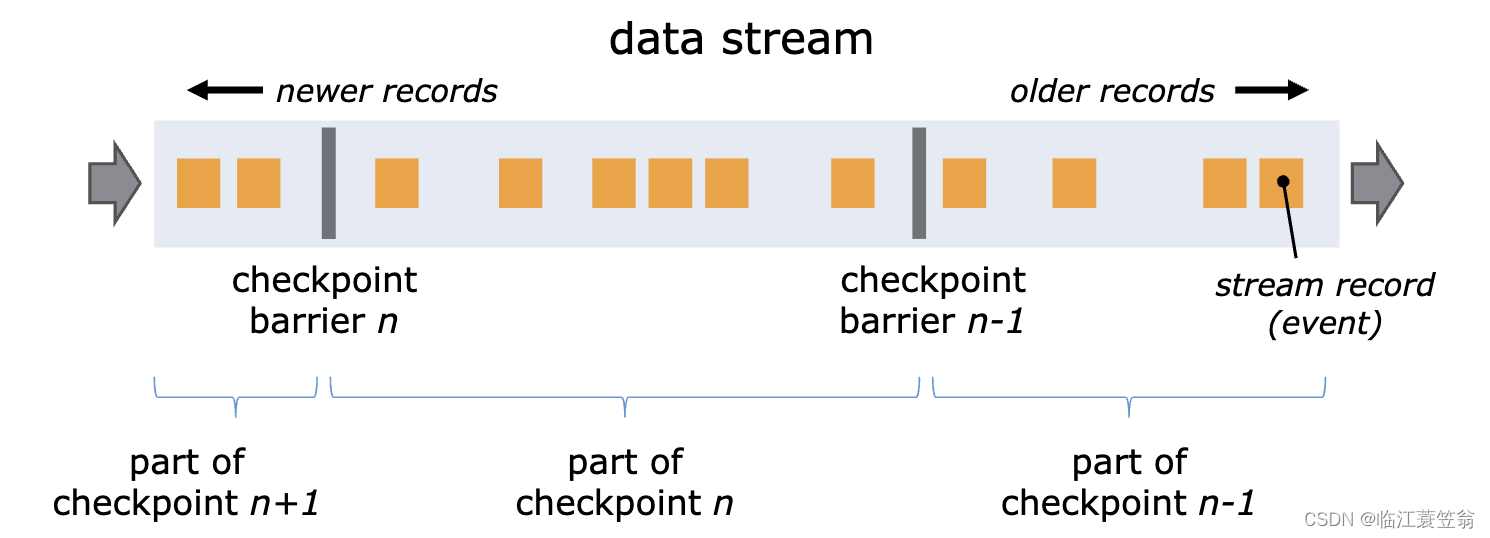

4.Aligned Checkpointing
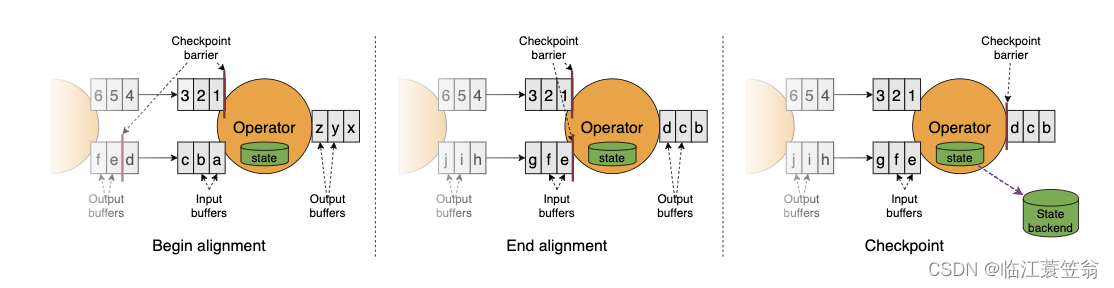
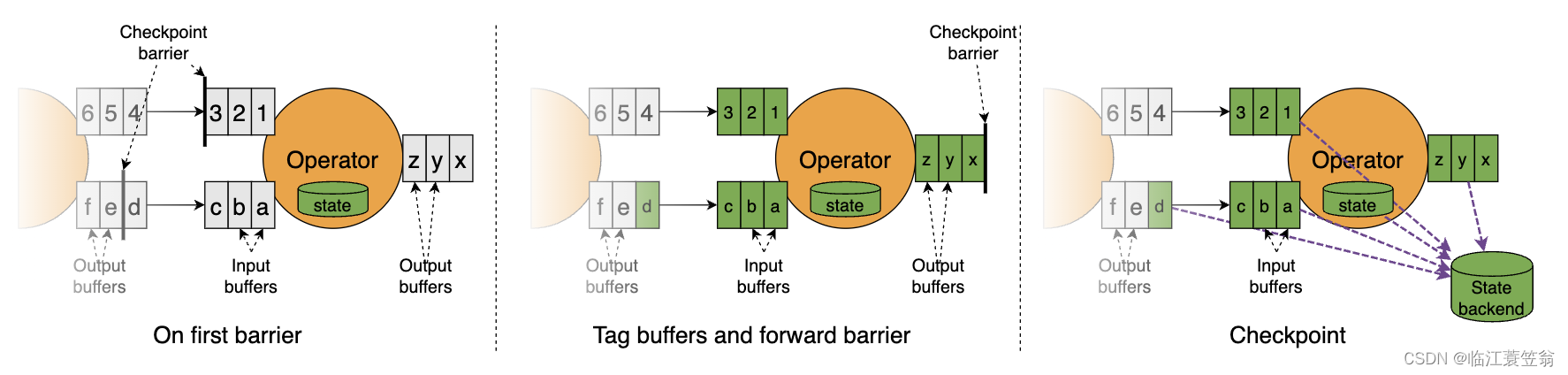
5.Unaligned Checkpointing
总结
参考链接
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。