摘要
在视频异常检测领域,基于自动编码器(Auto-Encoder,AE)的帧重构(当前或未来帧)方法是一种流行的技术。通过在正常数据上进行训练,模型通常能够将异常场景的重构误差与正常场景相比显著增大。之前的一些方法在自动编码器中引入了内存存储库(memory bank),以编码跨训练视频的各种正常模式。然而,这些方法会消耗大量内存,并且无法处理在测试数据中出现的未见过的新场景。
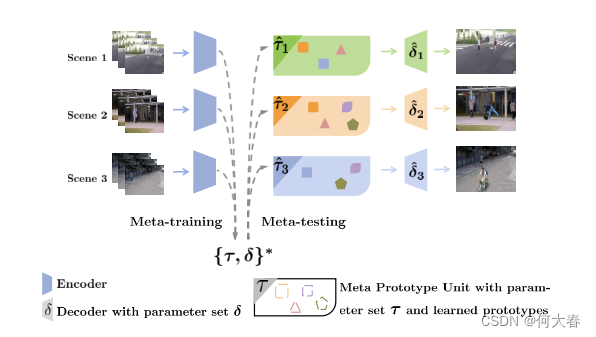
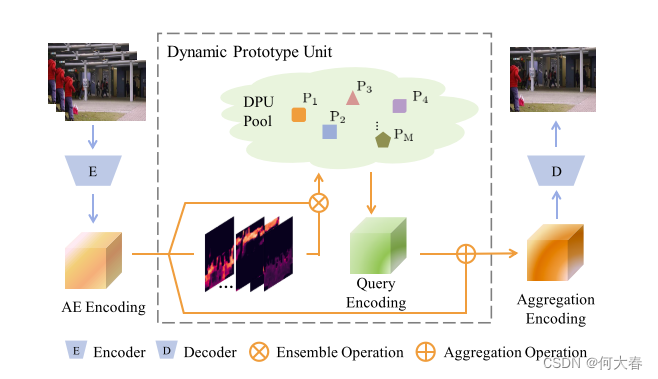
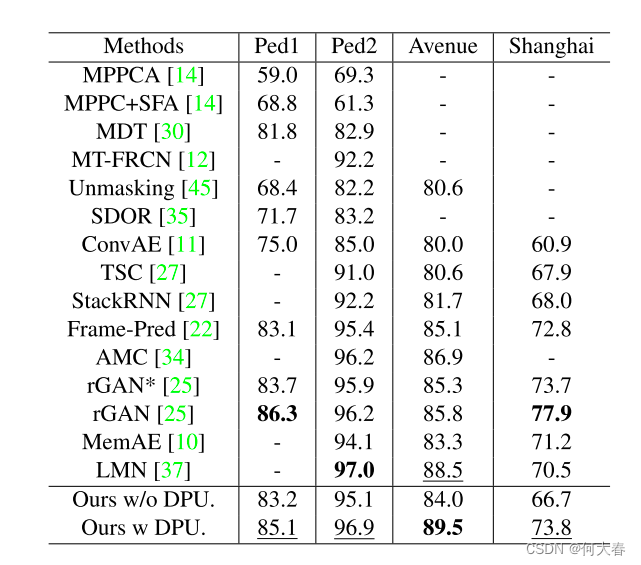
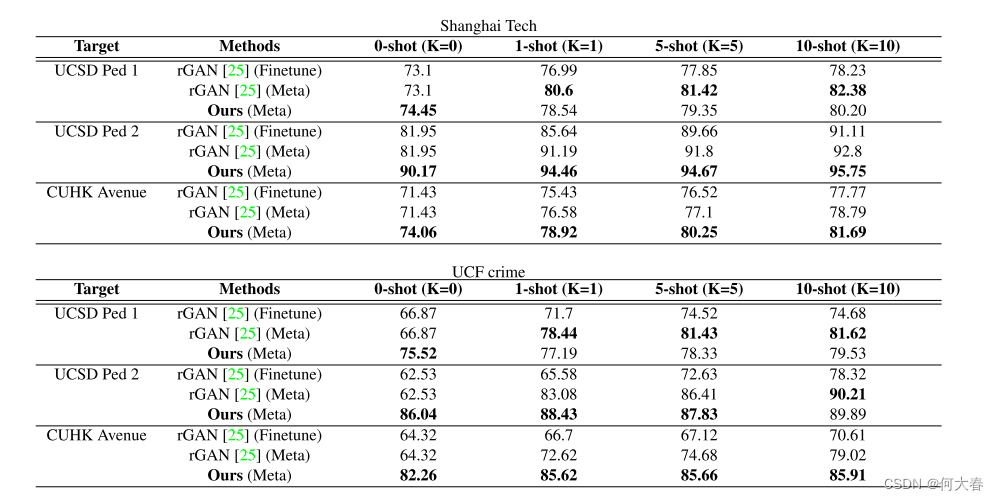
在我们的工作中,我们提出了一种动态原型单元(Dynamic Prototype Unit,DPU),用于实时将正常动态编码为原型,而无需额外的内存成本。此外,我们引入了元学习到我们的动态原型单元,形成了一种新颖的少样本正常性学习器,即元原型单元(Meta-Prototype Unit,MPU)。这使得我们的系统能够通过仅消耗少量迭代即可快速适应新场景。我们在多个基准数据集上进行了广泛的实验,结果表明我们的方法在性能上优于当前最先进的方法,证明了我们方法的有效性。
1.介绍
作者的主要工作是在视频异常检测(VAD)领域,提出了一种新的方法。首先,他们介绍了视频异常检测的背景和重要性,尤其是在公共安全监控中的关键作用。然后,作者指出了目前的异常检测方法中存在的问题,即对“异常”的定义概念不确定,难以收集所有可能异常的数据。因此,异常检测通常被制定为一种无监督学习问题,旨在通过学习模型仅利用正常数据中的规律模式。作者指出,Deep Auto-Encoder(AE)是视频异常检测的流行方法,通常用于对历史帧建模并重构当前帧或预测未来帧。
为了解决传统方法中存在的问题,作者提出了一种动态原型单元(DPU),用于实时编码正常动态并形成原型。他们还引入了元学习到DPU,形成了一种少样本正常性学习器,称为Meta Prototype Unit(MPU)。MPU通过学习目标模型的初始化,并在推断过程中通过少量参数更新调整到新场景,从而提高了场景适应能力。
主要贡献包括: