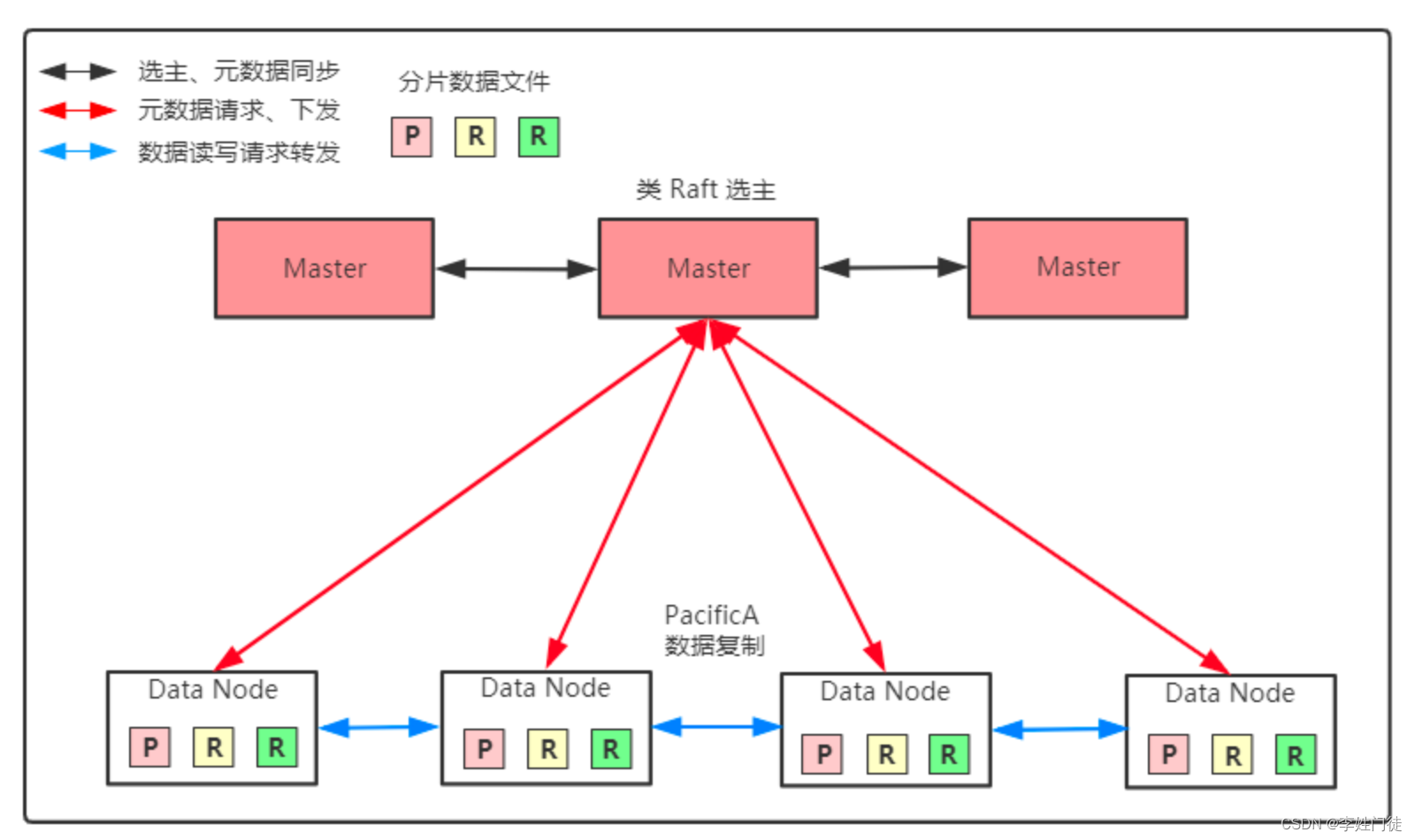
目录
前言
最近线上的项目部分数据表增量速度比较快,可以预见的是,个把月后数据量会急剧增长至千万级,所以只是简单的使用索引等已经无法满足业务需求了,分库分表势在必行!于是着手研究如何整合ShardingSphere到现有项目中,顺带记录一下实验过程吧。
特别声明:这边是实验配置阶段,还没有完成整合到项目、以及测试联调阶段,所以不敢保证实验过程是否正确。 而且,在我的业务中,还涉及到【普通单表】与【分片表】之间的联表查询,所以需要后期比较严谨的测试才能知道最终效果。不过我自己对比了站内其他大佬的教程,大体是没问题的。
阅读对象
无论你是采用ShardingSphere-JDBC还是ShardingSphere-Proxy,这篇文章同样适用
笔记正文
一、ShardingSphere介绍
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建【异构数据库】上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
说人话:ShadingSphere并非是一个数据库,而是数据库上层应用,关注于多数据库之间的分布式协作问题。
所谓【异构数据库】:多种不同类型的数据库产品
ShardingSphere目前有2个独立的产品:ShardingSphere-JDBC、ShardingSphere-Proxy。他们提供的服务是相同的,如下:
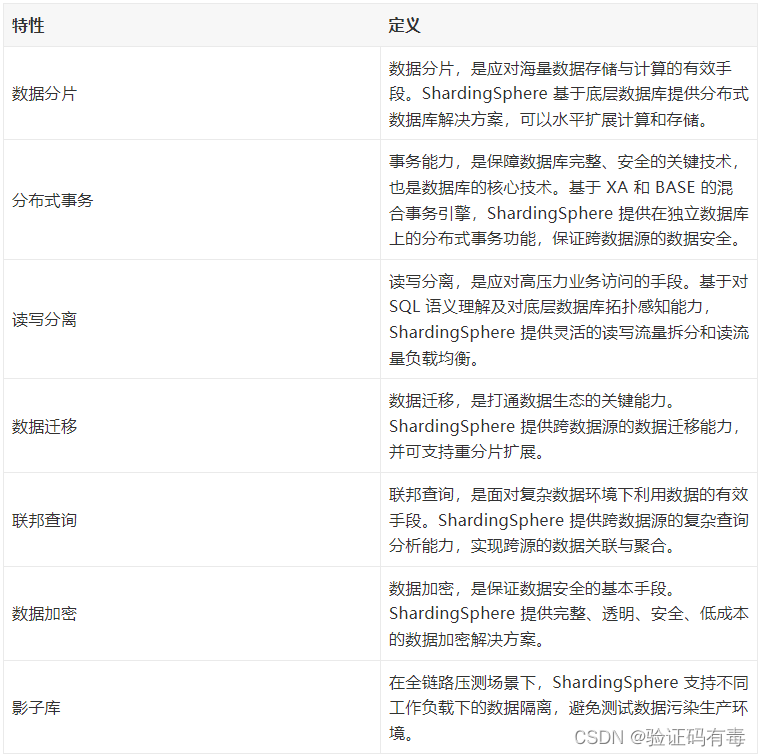
一张图给大家介绍一下ShardingSphere的生态结构图:

1.1 ShardingSphere-JDBC:代码级别
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。他有如下特点:
JDBC(Java Database Connectivity)是Java中用于连接和操作数据库的一组API,是Java数据库连接的标准,它为Java应用程序连接数据库提供了一种标准的接口。JDBC API可以连接几乎所有的主流数据库,如Oracle、MySQL、PostgreSQL、DB2等。
JDBC API由一组Java类和接口组成,这些类和接口定义了Java应用程序与数据库之间的通信方式。通过使用JDBC API,Java应用程序可以执行SQL语句、查询数据库、插入数据、更新数据等操作。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template,或直接使用 JDBC
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP,Druid等
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库
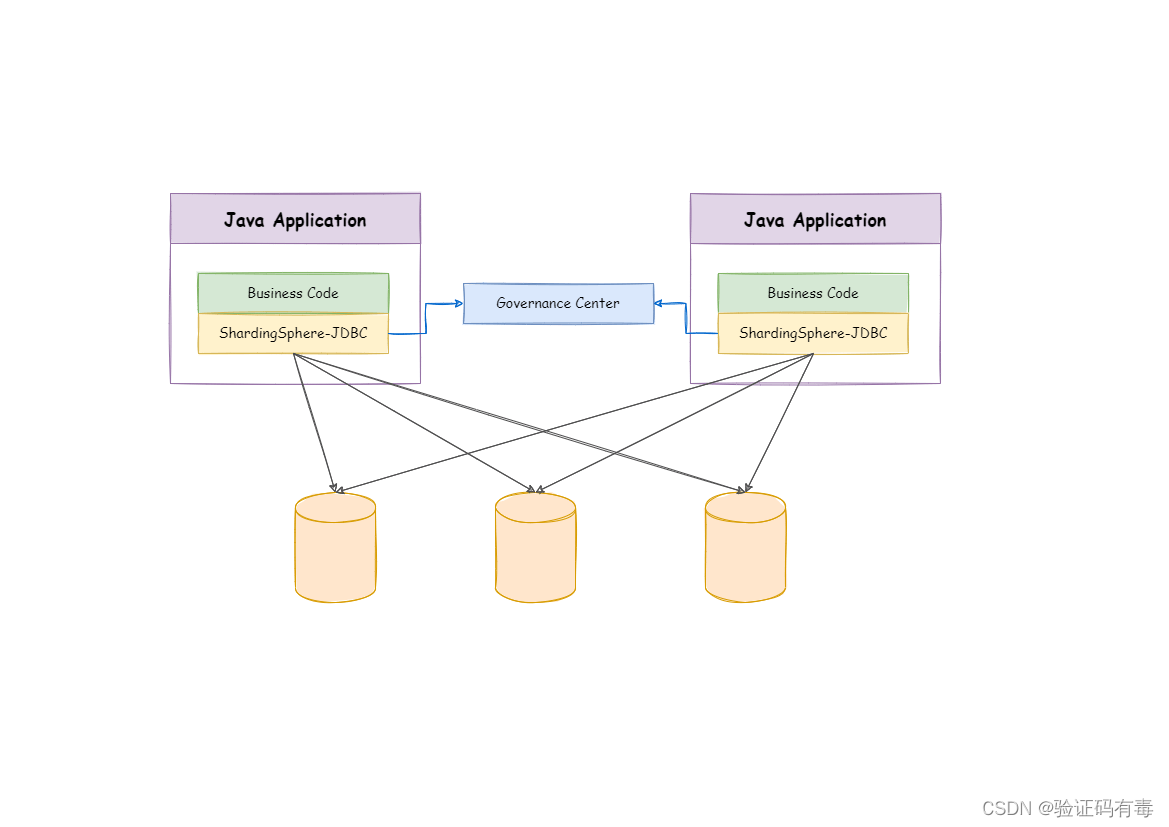
1.2 ShardingSphere-Proxy:应用级别
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等
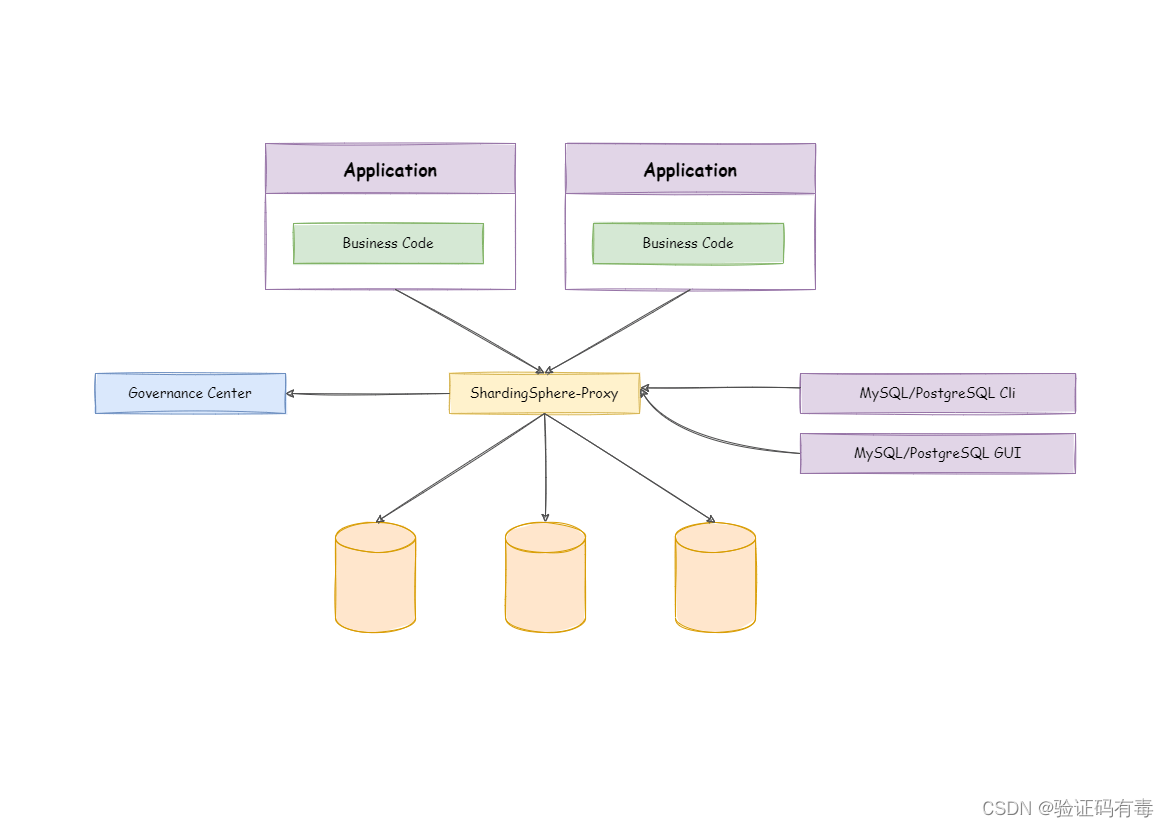
1.3 横向对比图
二、ShardingSphere之——数据分片
由于我的需求只是需要使用ShardingSphere的数据分片能力,所以为了节省时间我直接进入正题学习它了。
2.1 基本介绍
什么是数据分片?
数据分片是指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果
为什么需要数据分片?
突破单点数据阈值限制。无论再牛逼的机器配置,随着数据量的增大,一定会出现性能瓶颈
如何实现数据分片?
分库和分表。分库除了能在数据层面将数据分散开来以外,还能够有效地分散对数据库单点的访问量。而分表虽然无法直接缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能
讲人话:分表通常都是发生在单库下面的,单库单点之下当然避免了分布式事务。 分表还有另一个特点,那就是减少了检索深度。单表的时候,随着数据量增大,哪怕在B+树结构下,树的深度也会不可避免地增加,进而导致检索深度增加,IO次数也增加,最后检索时间增大
2.2 分片的形式
2.2.1 垂直分片
按照业务拆分的方式称为垂直分片,它的核心理念是专库专用。
在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
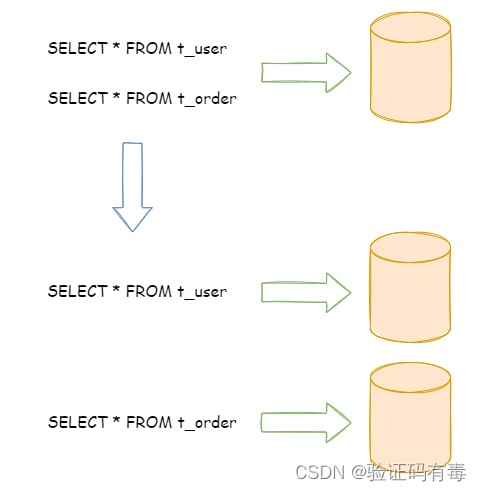
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
2.2.2 水平分片
水平分片相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。
例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示:
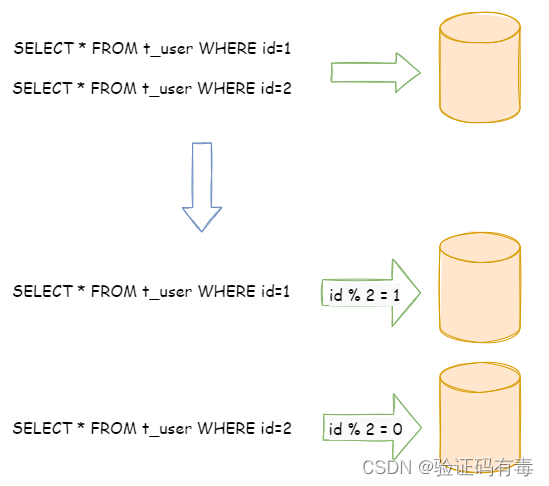
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
2.3 数据分片核心概念
2.3.1 表
表是透明化数据分片的关键概念。ShardingSphere 通过提供多样化的表类型,适配不同场景下的数据分片需求。在ShardingSphere 中有如下类型的表:
例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order。
- 真实表:在水平拆分的数据库中真实存在的物理表。 即上个示例中的 t_order_0 到 t_order_9
- 绑定表(比较难理解):指分片规则一致的一组分片表。使用绑定表进行多表关联查询时,必须使用【分片键】进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。
例:t_order 表和 t_order_item 表,均按照 order_id 分片,并且使用 order_id 进行关联,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系,并且使用 order_id 进行关联后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中 t_order 表由于指定了分片条件,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。
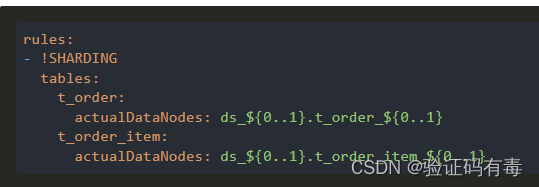
注意:绑定表中的多个分片规则,需要按照逻辑表前缀组合分片后缀的方式进行配置,例如:
2.3.2 数据节点
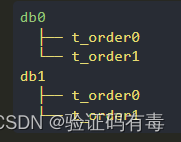
数据分片的最小单元,由数据源名称和真实表组成。 例:ds_0.t_order_0。逻辑表与真实表的映射关系,可分为均匀分布和自定义分布两种形式。
均匀分布:
指数据表在每个数据源内呈现均匀分布的态势, 例如:

2.3.3 分片概念集合
- 分片算法:用于将数据分片的算法,支持 =、>=、<=、>、<、BETWEEN 和 IN 进行分片。 分片算法可由开发者自行实现,也可使用 Apache ShardingSphere 内置的分片算法语法糖,灵活度非常高
- 自动化分片算法:分片算法语法糖,用于便捷的托管所有数据节点,使用者无需关注真实表的物理分布。 算法包括取模、哈希、范围、时间等常用分片算法的实现
- 自定义分片算法:提供接口让应用开发者自行实现与业务实现紧密相关的分片算法,并允许使用者自行管理真实表的物理分布。 自定义分片算法又分为:
- 分片策略:包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略
例:按照员工登录主键分库,而数据库中并无此字段。 SQL Hint 支持通过 Java API 和 SQL 注释两种方式使用。 详情请参见强制分片路由
- 分布式主键:传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。 数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
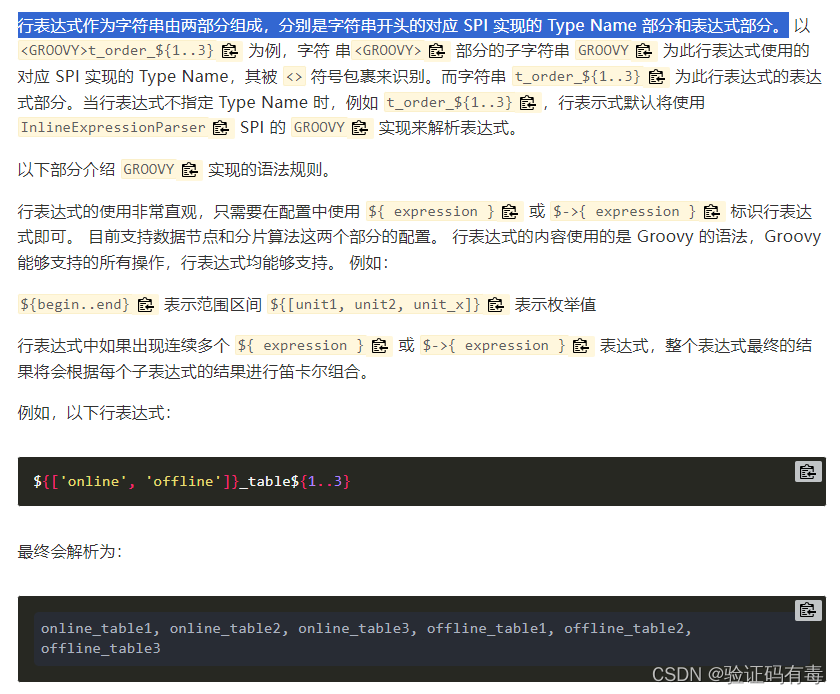
目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。为了方便用户使用、满足不同用户不同使用场景的需求, Apache ShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器 - 行表达式:行表达式是为了解决【配置的简化】与【一体化】这两个主要问题。在繁琐的数据分片规则配置中,随着数据节点的增多,大量的重复配置使得配置本身不易被维护。 通过行表达式可以有效地简化数据节点配置工作量。
对于常见的分片算法,使用 Java 代码实现并不有助于配置的统一管理。 通过行表达式书写分片算法,可以有效地将规则配置一同存放,更加易于浏览与存储。
三、下载
先说我的选择,我当前采用的方案是ShardingSphere-Proxy,而不是jdbc那一套。为什么选择这个?因为感觉会简单一点,jdbc毕竟是jar包形式,肯定存在代码侵入。选择proxy,作为一个独立应用,感觉会安全一点。
官方下载地址:传送门
我下载的是:5.4.1,二进制发布包
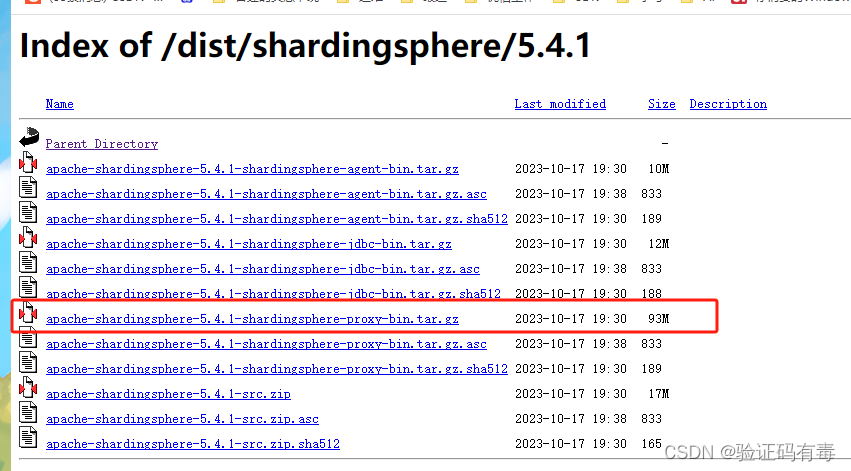
然后当前测试环境是windows11,目标环境是linux Centos7.
大家下载完上面那个不用担心系统问题,直接解压,配置完之后就能启动了,官方已经提供了win跟Linux环境的启动脚本。

注意,这个版本应该挺重要的,根据我这两天百度的情况来看,我猜测不同版本的配置属性是不太一样的。所以,如果你发现了配置属性跟我的不一样,那你要看看版本是否一致了。最好是结合官方给的配置属性看咯,官方不是给了很多模板嘛
四、配置启动
理论上,我们跟着上面提到的【官方启动教程】就可以理解配置过程了,但讲真还是有一丢丢难度的,官方的给的案例对新手而言不是特别友好,我本人也是反复翻看了官方文档以及CSDN站内大神的整合博客才开始懂的。我这边也大致的按照官方教程给大家翻译一下了。
结合我自己的业务场景噢!
但是在给大家翻译解读这些配置之前,需要给大家介绍一下我的项目背景,以及最终选择的分片策略。
背景:目前有一些报表类的业务数据增长非常快,但也仅仅只是那几张报表而已,其他的表数据量很正常
目的:减少表数据量大小,将耗时的报表业务与其他系统业务数据剥离
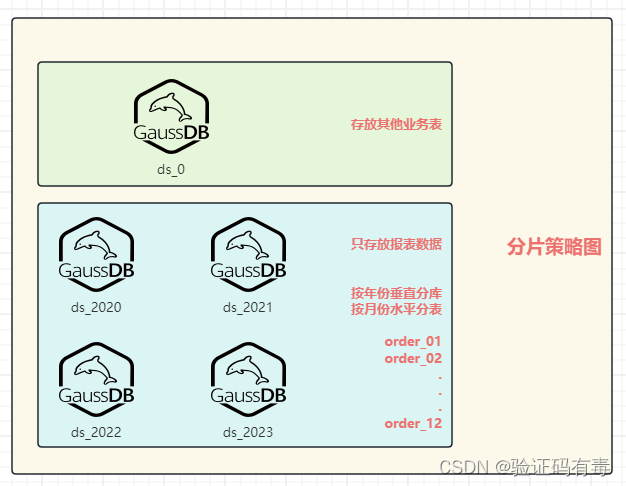
分片策略:基于上述特点【个别数据量增长迅速】,我初步计划是采取【垂直分片】+【水平分片】的方式。那我该如何设计我的分片策略呢?我主要是参考了官方的分片算法,通读之后了,再做出的选择。官方内置分片算法传送门:传送门
最后,我决定使用的
分片算法是官方提供的时间范围分片算法。分片策略结构图如下:
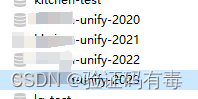
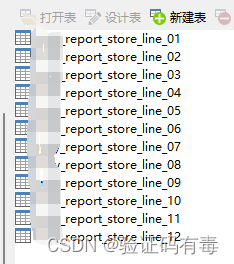
实验结果效果图:(4个垂直业务库)
每个业务库下面,水平分了12张表
OK,言归正传,下面开始配置实验。
步骤1:下载ShardingSphere-Proxy
这一步我在【三、下载】已经说了。下载之后(绿色版),解压到你要安装的位置,如下:我解压到了F盘上。下面我们称之为:安装目录

步骤2:认识一下conf目录
这里需要特别解释一下是:安装目录/conf/下以config-开头的各种yaml文件,其实他们的命名方式是以[config-]+[功能名].yaml命名的。
比如:config-sharding.yaml,配置的是数据分片功能;config-encrypt.yaml,配置的是数据加密功能等等。有啥功能大家看【一、ShardingSphere介绍】下面的图吧。
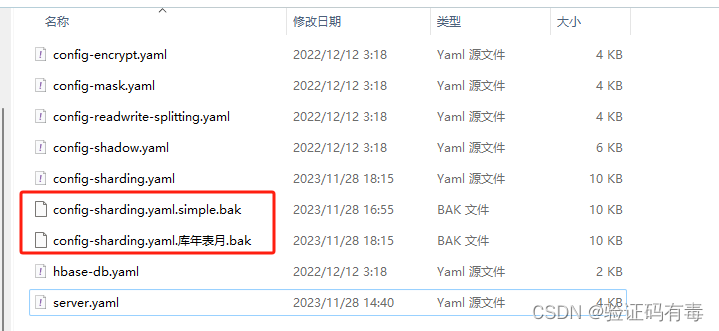
很显然,这里我们配置的就是config-sharding.yaml这个文件了。上面红框内的东西是我自己的配置备份,不是官方的。
步骤3:规则配置:YAML配置
官方规则配置传送门:传送门
这里的规则配置,指的是配置安装目录下的conf包下的配置。正常来说,需要配置如下内容:
1. 认证和授权
这里说的配置,指的是配置
安装目录/conf/server.yaml下的authority,官方已经提供了模板,我只是打开了注释
大家也可以看官方的配置内容,我当前测试环境没有做很麻烦的配置,只是配置了账号密码。

因为我自己目前也是在实验阶段,所以我也只是这么简单的配置一下,到了生产上可能就不是这样了,大家需要自己去衡量哦。或者我在后面上线生产的时候,我再回来更新,看看哪些是必须要配置的
2. 属性配置
官方已经提供了模板,我只是打开了注释。还是之前说的,我只是实验阶段,具体生产要怎么配置需要进一步调试。
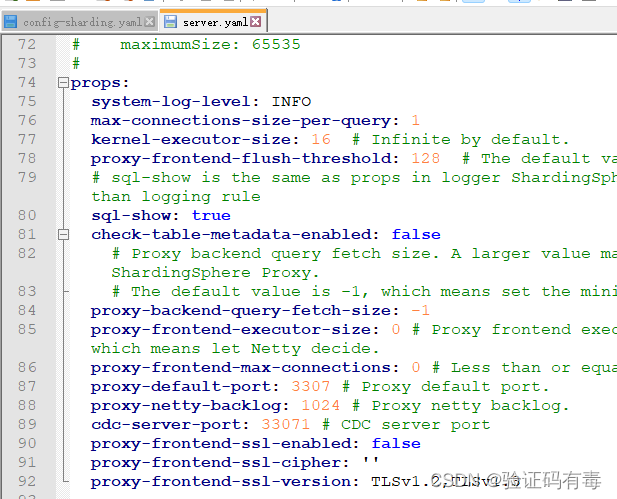
3. 模式配置
模式,指的是【运行模式】。有单机、集群等。默认单机
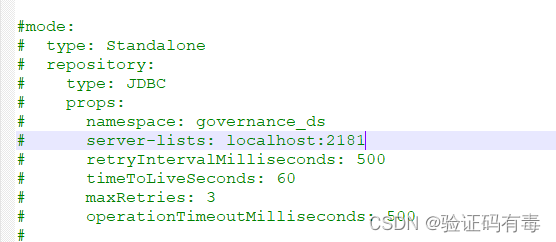
由于实验阶段,所以我默认了单机,所以啥都不用管。
*4. 数据源配置
这里说的配置,指的是配置
安装目录/conf/config-sharding.yaml下的databaseName和dataSources,官方已经提供了模板
到了这里,其实就比较关键了。这个数据源配置,需要跟自己的业务结合起来选择怎么配置,配置多少个数据源。而且对于我们初学者来说,通常没办法一次性就确定数据源的配置,而是将当前步骤【4. 数据源配置】和【5. 规则配置(功能配置)】一起进行的。
当然,官方也提供了模板:
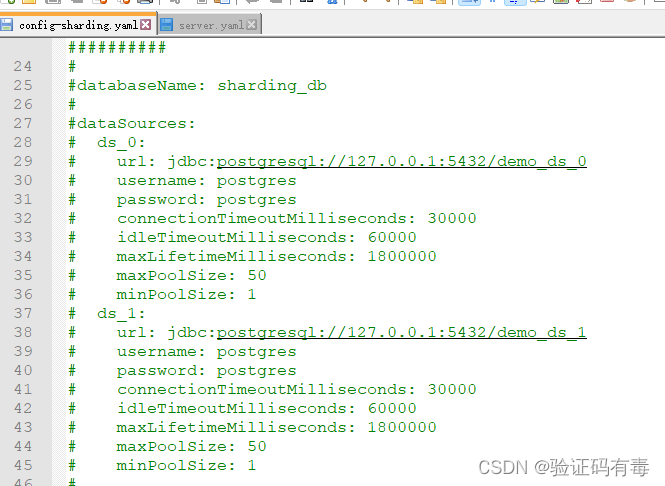
而我最终的配置是:
# 分库后逻辑数据库名称
databaseName: sharding_unify_db
# 数据源配置
dataSources:
# 数据源名称
ds_0:
# 数据源链接池完整类名
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/shen-dev
username: shen
password: 123456
ds_2020:
# 数据源链接池完整类名
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/shen-unify-2020
username: shen
password: 123456
ds_2021:
# 数据源链接池完整类名
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/shen-unify-2021
username: shen
password: 123456
ds_2022:
# 数据源链接池完整类名
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/shen-unify-2022
username: shen
password: 123456
ds_2023:
# 数据源链接池完整类名
dataSourceClassName: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/shen-unify-2023
username: shen
password: 123456
不过这里有一个要注意的点,因为我选择的是Alibaba的Druid数据源,并且是Mysql数据库,所以,我们需要复制我们当前项目的两个jar包到安装目录/lib下,比如我的是下面这两个包:
*5. 规则配置(功能配置)
根据官方引导,这一步【规则配置】,ShardingSphere-proxy跟ShardingSphere-jdbc的【规则配置】内容是一样的,所以最后去看了ShardingSphere-jdbc的【规则配置】。
官方传送门:传送门

我们要实现的功能是【数据分片】所以看看数据分片的内容。到了这里难度就剧增了,眼花缭乱的配置,甚至有一些内容我自己也没吃透,所我目前没办法给大家伙保证我下面的实验一定是正确的。
根据我的学习理解来说,要完成【规则配置(功能配置)】其实可以分为下面几个小步骤:
1)配置表的分库策略(针对需要分片的表)
2)配置表的分表策略(针对需要分片的表)
3)配置分布式主键策略
4)配置分片审计策略
5)配置默认的分库、分表策略(针对其余业务表)
6)配置分片算法实现策略
7)配置分布式序列算法实现策略
8)配置分片审计策略
总得来说,需要设置分片表的分库分表策略;设置对应的算法策略。
OK,贴上我自己的配置策略:
# 规则配置
rules:
- !SHARDING
# 数据分片规则配置
tables:
# 逻辑表名称
shen_report_store_line:
# 数据节点。数据源+表(行表达式)
actualDataNodes: ds_${2020..2023}.shen_report_store_line_0${1..9},ds_${2020..2023}.shen_report_store_line_1${0..2}
# 分库规则
databaseStrategy:
# 用于单分片键的标准分片场景
standard:
# 分片键名称
shardingColumn: biz_date
# 分片算法名称,具体算法在后面的【算法模块】声明
shardingAlgorithmName: database_interval
# 分表策略
tableStrategy:
# 用于单分片键的标准分片场景
standard:
# 分片键名称
shardingColumn: biz_date
# 分片算法名称,具体算法在后面的【算法模块】声明
shardingAlgorithmName: shen_report_store_line_interval
# 分布式主键策略
keyGenerateStrategy:
# 自增列名称
column: id
# 分布式主键生成算法,具体算法在后面的【算法模块】声明
keyGeneratorName: uuid
# 分片审计策略
auditStrategy:
# 分片审计算法名称
auditorNames:
- sharding_key_required_auditor
# 是否禁用分片审计hint
allowHintDisable: true
# 默认分片键名称
#defaultShardingColumn: create_time
# 绑定表
#bindingTables:
# - t_order,t_order_item
# 默认数据库分片策略
defaultDatabaseStrategy:
none:
defaultTableStrategy:
none:
# 分片算法配置
shardingAlgorithms:
database_interval:
# 分片算法类型。这里表示使用:时间范围分片算法
type: INTERVAL
# 分片算法属性配置
props:
# 分片键的格式
datetime-pattern: "yyyy-MM-dd HH:mm:ss"
# 分片下界值,格式必须同上面的datetime-pattern
datetime-lower: "2020-01-01 00:00:00"
# 分片上界值,格式必须同上面的datetime-pattern
datetime-upper: "2050-01-01 00:00:00"
# 分片数据源或真实表的后缀格式
sharding-suffix-pattern: "yyyy"
# 分片键时间间隔,超过该时间间隔将进入下一分片
datetime-interval-amount: 1
# 分片键时间间隔单位 DAYS/MONTHS/YEARS
datetime-interval-unit: "YEARS"
# 分片算法名称
shen_report_store_line_interval:
# 分片算法类型。这里表示使用:时间范围分片算法
type: INTERVAL
# 分片算法属性配置
props:
datetime-pattern: "yyyy-MM-dd HH:mm:ss"
datetime-lower: "2020-01-01 00:00:00"
datetime-upper: "2050-01-01 00:00:00"
sharding-suffix-pattern: "MM"
datetime-interval-amount: 1
datetime-interval-unit: "MONTHS"
# 分布式序列算法配置
keyGenerators:
uuid:
type: UUID
auditors:
sharding_key_required_auditor:
type: DML_SHARDING_CONDITIONS
# 广播表,我这里没有广播表
#- !BROADCAST
# tables:
# - t_address
# 单表
- !SINGLE
tables:
# MySQL 风格,加载指定数据源中的全部单表
- ds_0.*
# 默认数据源,仅在执行 CREATE TABLE 创建单表时有效。缺失值为空,表示随机单播路由。
defaultDataSource: ds_0
CREATE TABLE `shen_report_store_line` (
`id` varchar(20) NOT NULL,
`tenant_id` varchar(20) DEFAULT NULL COMMENT '租户id',
`line_id` varchar(20) DEFAULT NULL COMMENT '档口id',
`store_id` varchar(20) DEFAULT NULL COMMENT '所属餐厅id',
`report_type` tinyint(4) DEFAULT NULL COMMENT '报表类型(1-日报;2-周报;3-月报;4-季报;5-年报)',
`biz_date` datetime DEFAULT NULL COMMENT '账目日期',
`year` int(4) DEFAULT NULL COMMENT '年',
`month` int(4) DEFAULT NULL COMMENT '月',
`week` int(4) DEFAULT NULL COMMENT '周(年属第几周)',
`turnover` decimal(10,2) DEFAULT '0.00' COMMENT '营业额',
`operating_cost` decimal(10,2) DEFAULT '0.00' COMMENT '主营业务成本',
`total_cost` decimal(10,2) DEFAULT '0.00' COMMENT '总成本',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`create_user` varchar(20) DEFAULT NULL COMMENT '创建人',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`update_user` varchar(20) DEFAULT NULL COMMENT '更新人',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='餐厅营业数据-档口维度';
还记得我要实现的分表策略吧?说到策略这个东西,它跟分片算法离不开。我使用的是官方提供的时间范围分片算法。
该算法的介绍及参数如下:
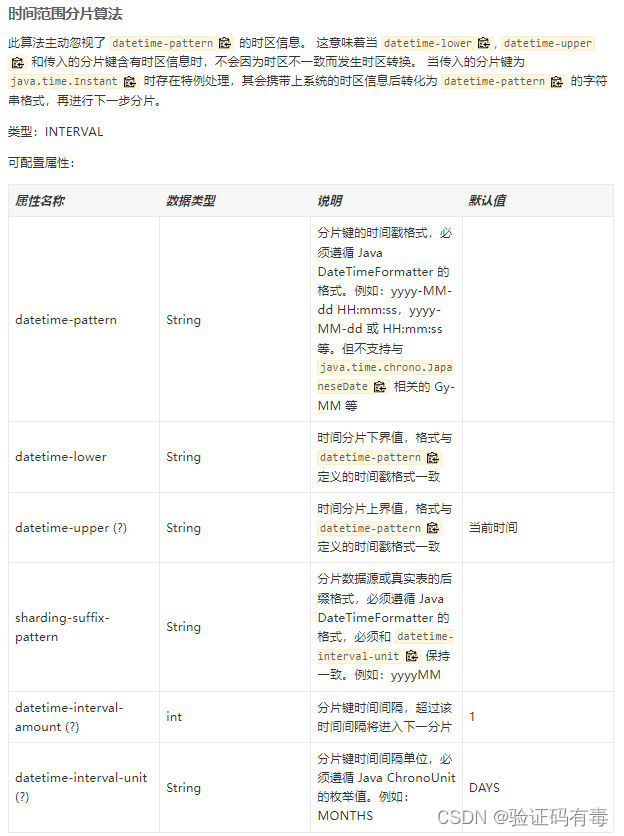
讲真的,这个算法我也是研究了一下才晓得怎么用的,官方还不提供模板示例,规则讲的也不是很清楚,我是把源码翻出来之后,把官方源码掏出来自己debug才晓得怎么耍的。如果你们也要尝试使用这个算法,可以用下面这段代码校验:
@Test
public void test() {
String datetimePattern = "yyyy-MM-dd HH:mm:ss";
String shardingSuffixPattern = "yyyyMM";
String datetimeLower = "2020-01-01 00:00:00";
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(datetimePattern);
TemporalAccessor dateTime = dateTimeFormatter.parse(datetimeLower);
System.out.println(dateTime);
DateTimeFormatter tableSuffixPattern = DateTimeFormatter.ofPattern(shardingSuffixPattern);
String tableSuffix;
if (!dateTime.isSupported(ChronoField.NANO_OF_DAY)) {
if (dateTime.isSupported(ChronoField.EPOCH_DAY)) {
System.out.println(1);
tableSuffix = tableSuffixPattern.format(dateTime.query(TemporalQueries.localDate()));
System.out.println(tableSuffix);
return;
}
if (dateTime.isSupported(ChronoField.YEAR) && dateTime.isSupported(ChronoField.MONTH_OF_YEAR)) {
System.out.println(2);
tableSuffix = tableSuffixPattern.format(dateTime.query(YearMonth::from));
System.out.println(tableSuffix);
return;
}
if (dateTime.isSupported(ChronoField.YEAR)) {
System.out.println(3);
tableSuffix = tableSuffixPattern.format(dateTime.query(Year::from));
System.out.println(tableSuffix);
return;
}
if (dateTime.isSupported(ChronoField.MONTH_OF_YEAR)) {
System.out.println(4);
tableSuffix = tableSuffixPattern.format(dateTime.query(Month::from));
System.out.println(tableSuffix);
return;
}
}
if (!dateTime.isSupported(ChronoField.EPOCH_DAY)) {
System.out.println(5);
tableSuffix = dateTime.query(TemporalQueries.localTime()).format(tableSuffixPattern);
System.out.println(tableSuffix);
return;
}
System.out.println(6);
tableSuffix = LocalDateTime.from(dateTime).format(tableSuffixPattern);
System.out.println(tableSuffix);
}
步骤4:启动服务
OK,配置完毕之后就可以启动了,很简单,win下就是双击安装目录/bin下的start.bat就好了。
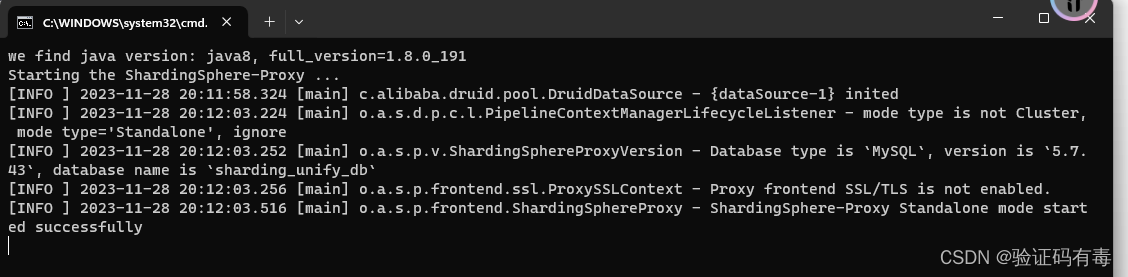
出现了start successfully就代表启动成功了。
五、SpringBoot整合ShardingSphere-Proxy
这个我在下一篇笔记讲咯,我采用的方案是ShardingSphere-Proxy,应该比较简单,毕竟只是一个独立的应用。
学习总结
感谢
感谢CSDN站内大佬【作者:攻城狮悠扬】的文章《Sharding-Proxy代理Mysql服务》
感谢CSDN站内大佬【作者:攻城狮悠扬】的文章《ShardingSphere-Proxy5 分片算法-时间范围分片》
原文地址:https://blog.csdn.net/qq_32681589/article/details/134651667
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_42158.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!