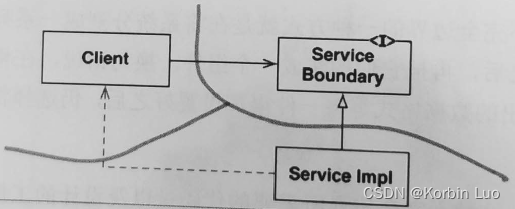
Clean 架构下的现代 Android 架构指南
Clean 架构是 Uncle Bob 提出的一种软件架构,Bob 大叔同时也是 SOLID 原则的命名者。

这张图描述的是整个软件系统的架构,而不是单体软件,其中至少包括服务端以及客户端。
对于 Android 单体应用开发来说应该还需要一个更贴切更精确的 Clean 架构图。
我大概总结了一下过往的开发经验,找出了应用架构中的重要部分,然后绘制了下面这张 Clean 架构指导下的 Android 应用架构图:

以及一般数据流向图:

依赖关系
Clean 架构基本准则是源码级别的内层不依赖外层,依赖关系永远是单向的,外层向内层依赖。
如上,Model 层是没有任何依赖的,UseCase 可以依赖 Model 和 Repo 等,但绝不能依赖 ViewModel,UI 层依赖 ViewModel,但 ViewModel 绝不能依赖 UI 层。
为了达到这种源码级别的依赖关系,我们必须借助一些工具来实现依赖注入,一般可以使用 Hilt 或者 Koin 这样的框架来实现。
另外,依赖注入不应该被滥用,不是所有的对象都适合用依赖注入,只有那些有明确层次关系的模块,互相有着明确的依赖关系的才需要。对于一些工具类,显然是没必要注入的。
Model(领域模型)
业务模型,或者叫领域模型,是根据软件业务设计出来的具体模型,一般来说会是个 data class,其中不包含任何业务逻辑,只是个单纯的模型对象。
由于是在整个架构的最内层,所以不依赖任何其他模块,并且相对稳定,设计的时候需要考虑这点。如果模型发生变化,那意味着整个上层的依赖方都可能发生变化,需要重新测试。
在命名和包结构上,领域模型不需要带 Entity 之类的后缀,直接命名为像 User 一样即可,但考虑到这是在软件的最内层,可能会被所有模块依赖到,所以要尽可能贴近其设计目标,并且不能太过宽泛。在包结构上,需要被存放在 model 包下面。
Adapter(数据适配器)
Adapter 层也比较纯粹,只负责简单的数据转换,而且对外暴漏的函数都是幂等函数。
如果数据转换过程中涉及到复杂的业务逻辑,可以考虑先用 UseCase 处理完成后再交给 Adapter。但因为 Adapter 层比 UseCase 层更靠内,所以 Adapter 不能依赖 UseCase。
习惯上,我们会以待转换类为开头,Adapter 结尾命名,例如我们要把 UserEntity 转换为 User, 那么应该这么写:
class UserEntityAdapter{
fun toUser(entity: UserEntity): User {
//...
}
}
Repo
对于我们 Android 开发来说,Repo 层应该是对网络接口或本地磁盘的数据读写的封装,对于 Repo 的使用者来说,不需要关注具体的实现,且 Repo 中一般不具备复杂的业务逻辑,只能包含简单的数据处理逻辑。
Repo 应当隐藏具体的实现细节,不仅包括获取方式是网络还是本地数据,也应该隐藏对应的实体数据类,这意味着 **Repo 层对外暴漏的函数的入参和出参不能包含接口返回的实体类,也不应该包含数据库表实体类,只能包含领域模型或者基本类型。**我们给 Room 设计的数据库表的 data class 应该限制在 Repo 内部,我们给 Retrofit 设计的接口返回数据 data class 也同样应该限制在 Repo 内部。
data class UserEntity(val name: String, val avatar: String)
interface UserService {
@GET("/user")
suspend fun getUserInfo(@query("id") id: String): UserEntity
}
data class User(val name: String, val avatar: String)
class UserEntityAdapter @Inject constructor() {
fun toUser(entity: UserEntity): User {
return User(name = entity.name, avatar = entity.avatar)
}
}
class UserRepo @Inject constructor(
private val userEntityAdapter: UserEntityAdapter,
) {
private val userService: UserService by lazy {
retrofit.create(UserService::class.java)
}
suspend fun getUser(id: String): User {
return userService.getUserInfo(id).let(userEntityAdapter::toUser)
}
}
除了上面说的相应数据的转换之外,请求数据也需要在 Repo 层转换,对于 Post 请求来说,可能会存在一个请求实体,这个实体数据类最好也不要对外暴漏,可以在 Repo 层的请求方法入参那里做一些转换,最好能让入参更简单友好。
Repo 层还有一个作用就是负责把从接口或者数据库中出来的不友好的数据模型转换成友好的数据模型。
另外,现在由于有了 BFF 的存在,在某些比较简单的业务场景下我们可以为了方便做一些妥协,也就是接口的响应数据实体类可以穿透 Repo 层,直接给到 ViewModel,甚至是 UiState 使用,但应该明白这只是为了方便的妥协,并不是最佳实践,需要严格控制影响范围。
UseCase(用例)
UseCase 一般是指特定应用场景下的业务逻辑,用例引导了数据在模型之间的输入输出,并且指挥着业务实体利用其中的关键业务逻辑来实现用例的设计目标。
因此,一个 UseCase 往往只包含一段具体的业务逻辑,他的输入是基本类型或者领域模型,输出也是,并且是幂等函数,也就是纯函数,所以 Google 建议我们每个 UseCase 只包含一个公开的函数,类似于下面这种写法:
class DoSomethingUseCase {
operator fun invoke(xxx: Foo): Bar {
// ...
}
}
通过利用 Kotlin 特性来使 UseCase 在使用的时候达到直接使用函数的体感。
但考虑到依赖以及管理问题,UseCase 最好还是不要直接使用函数来实现,应当按照上面的方式,定义一个类,然后再暴露一个通过操作符重载的函数。
class LoginViewModel @Inject constructor(
private val doSomething: DoSomethingUseCase,
): ViewModel(){
fun onLoginClick(){
doSomething()
}
}
UseCase 的问题
UseCase 的粒度非常细,基本上每个 UseCase 就是一个函数,在复杂的业务背景下将会存在非常多的 UseCase,随着业务的增加,对他们的管理将难以为继。
因此,UseCase 需要一个有效的手段来进行管理,首先,应当按功能对他们的包名进行划分。同一个业务的 UseCase 最好具备相同的包名。
其次,我们不能陷入所有业务都用 UseCase 的极端情况中,很多时候,我们可以将一些极度类似的功能组织在一个类中,其中提供多个公开的方法,这样的写法在以前很常见,比如各种 Manager, Helper, Resolver 等,他们能有效的减少 UseCase 数量,并且相对简单。
UiState
UiState 是用来描述当前 UI 状态的集合类,一般来说应该是个 data class。
UiState 一定是不可变类,如果希望更改其中的某个值,应当重新创建一个对象,直接通过 data class 提供的 copy 方法即可,例如:
data class LoginUiState(
val name:String,
val avatar: String,
val consentAgreed: Boolean
)
fun onAgreeChecked(){
uistate = uiState.copy(
consentAgreed = true,
)
}
UiState 中的数据应当尽可能的方便给 UI 直接使用,因为 UiState 本身就是为了 UI 设计的,例如对于一个需要显示的格式化后的时间,格式化的逻辑最好放在 ViewModel 或者更内层,而不是直接给 UiState 一个时间戳,让 UI 层去格式化。很多时候看起来简单的逻辑也可能犯错误,UI 层没有能力处理异常。
在 ViewModel 中如果需要更新 UiState,可以直接通过 update 方法。
_uiState.update {
it.copy(
name = "zhangke"
)
}
ViewModel
ViewModel 负责管理 UI 状态,执行对应的业务逻辑。
一般来说我们会通过直接使用 Jetpack 提供的 ViewModel,但也可以自己创建其他类型的 ViewModel,只要控制好生命周期即可。
ViewModel 主要负责两件事情:
当前 UI 状态我们通过将 UiState 包装在 StateFlow 里对外提供。
private val _uiState = MutableStateFlow()
val uiState:StateFlow<UserUiState> = _uiState.asStateFlow()
接受 UI 事件这点需要注意,ViewModel 需要做的是接收 UI 事件,例如用户手势输入,至于用户点击之后要做什么事情这是 ViewModel 的内部逻辑,不应该对外暴露。
UI 层
我们这里说的 UI 层就是指一个页面,除了常规的 Activity/Fragment 之外,对于 Compose 来说一个页面可能对应的是一个 Composable 函数,这取决于 UI 层的实现。
UI 层应该完全是数据驱动的,UI 层的作用就是百分之百的将 UiState 渲染出来,UiState 发生变化,UI 也跟着变化,这一点声明式 UI 框架做的很好。
UI 层虽然也可以处理一些简单的事件,但大部分的事件都还是要交给 ViewModel 来处理。
以上就是 Android 整洁架构中的一些关键概念的介绍,我已经按照这个架构开发了一年多了,目前看下来确实会让架构很整洁,但对于一些复杂的业务场景,尤其是可能需要穿透多个层级,跨越常规生命周期的模块就需要更精细的设计了。
原文地址:https://blog.csdn.net/u013872857/article/details/134790318
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_42230.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!