最近在复习java web 相关的内容,在servlet章节有一个非常重要也是在面试中经常会被问到的一个问题,那就是如何解决get请求或者post请求参数的中文乱码问题。下面我将给出解决方案,并进行详细解析,毕竟学习编程不仅要知其然,更要知其所以然嘛。
问题描述
无论是get请求还是post请求,在没有做任何乱码处理的情况下,接收的中文参数在控制台输出都会出现乱码现象。
@WebServlet("/demo") public class servletDemo extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String username = req.getParameter("username"); System.out.println(username); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String username = req.getParameter("username"); System.out.println(username); } }

下面我将从get请求以及post请求两个方面去解决乱码问题。
POST请求参数中文乱码原因分析及解决方案:
我们想要解决该问题,就需要了解Post请求的底层是如何获取参数的。
POST底层通过POST.getReader()获取字节输入流,而获取的输入流的字符编码是ISO-8859-1。而我们页面大多数支持的字符编码都是UTF-8的,所以这就是Post请求参数会出现中文乱码的问题所在。
因此,解决方法就显而易见了,我们只需要在接收数据的时候去“通知”tomcat重新定义获取字节输入流的编码(UTF-8)就可以了。
解决方法:
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 解决乱码:Post.getReader()
req.setCharacterEncoding("UTF-8"); //设置字节输入流的字符编码
String username = req.getParameter("username");
System.out.println(username);
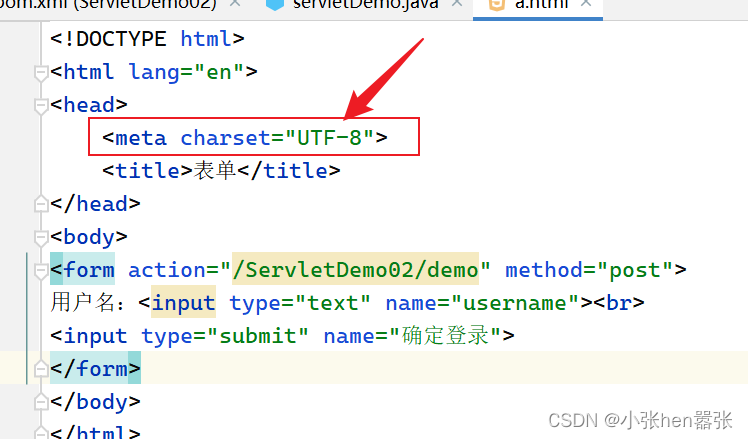
}要注意的是:我们设置的字符编码是跟你的页面中的字符编码相匹配的,如果你页面的字符编码是GBK或者其他,就需要设置GBK……的字符编码。 页面的字符编码如下图所示:
GET请求参数中文乱码原因分析及解决方案:
首先我们要知道GET底层是如何获取参数的, GET请求是通过getQueryString()的方法(这也是getParameter()底层方法)来获取参数的,并没有像POST请求那样走字节输入流,所以我们用修改字符编码的方式(因为get底层走的是方法,而方法里的编码方式是写死的。所以不能像POST请求那样直接走字节流,可以直接修改字节流的编码方式来解决)是无法解决乱码问题的。
要想解决GET方式的乱码问题,我们可以通过分析编码解码的过程来寻找突破口。
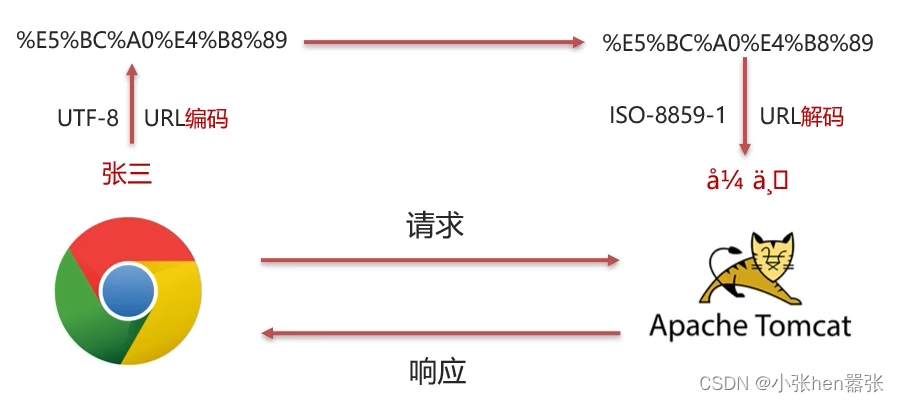
因为浏览器不支持中文,所以在进行前后端交互的时候中文字符串都需要进行转码。如上图所示,整个转码过程分为两部分,第一,浏览器会对你输入的中文字符串进行转码,然后将转好的码去交给tomcat进行解码,从上文我们知道tomcat解码的默认方式是ISO-8859-1,所以编码解码方式的不匹配从而产生了乱码现象。下面我们以”张三“为例来进行上文过程的解析。
如上图所示: 浏览器在发送参数时(张三)会根据你自己页面上的字符编码(UTF-8)来进行转码(该转码是浏览器自己做的,下文会向大家展示浏览器的转码结果),因为UTF-8编码对中文转码是一个汉字三个字节,所以“张三”被转为了六个字节。进行完该转码后浏览器还会将转好的UTF-8码进行URL编码,然后将数据转发给tomcat。
URL编码的逻辑是
2.每个字节转为2个16进制数并在前面加上%,如上图(因为“张三“对应的UTF-8码是六个字节,所以转为二进制是48个二进制数,再将每两个字节对应的二进制数转为16进制就会呈现下图所示的码)。


tomcat在接收到浏览器发送的参数码的时候会进行相应的解码,首先进行URL解码,在进行编码解码,但是因为tomcat底层的编码方式默认是ISO-8859-1,所以无法正确的将参数码解码,从而导致了如上图所示的乱码问题。
相信细心的小伙伴已经发现了,虽然我们乱码的根本原因是前后的编码解码不一致,但是有一个地方是相同的,那就是浏览器的URL编码与tomcat的URL解码。
因为URL编码和URL解码分别是浏览器发送请求参数码的最后一步和tomcat解码的第一步,所以浏览器进行URL编码的数据与tomcat进行URL解码的数据是一模一样的,那么我们是不是可以将tomcat获取的解码后的乱码参数重新转成字节数据,然后再根据字节数据重新按照UTF-8的编码进行二次解码呢?答案是肯定的!我们解决get请求中文乱码问题的关键也就在这里。
第一:对于得到的数据进行二次编码,转为字节数组。
第二:对编码后的数据进行二次解码。
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String username = req.getParameter("username");
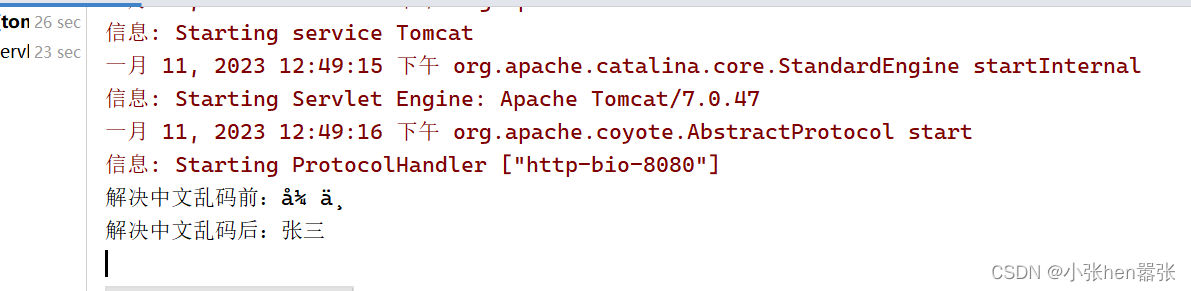
System.out.println("解决中文乱码前:"+username);
// 对获取的username进行二次编码 转为字节数组
byte[] bytes = username.getBytes(StandardCharsets.ISO_8859_1);
// 对获得的字节数组进行解码 UTF-8
username = new String(bytes, StandardCharsets.UTF_8);
System.out.println("解决中文乱码后:"+username);
}
通过上文,我们知道中文乱码的原因以及解决方案,以及更多的是从原理上去分析、了解问题的根本。我是小张hen嚣张(不嚣张),感谢大家的关照,以后我会继续更新该类文章。
原文地址:https://blog.csdn.net/ZGJLZL/article/details/128635831
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_42242.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)