本文介绍: 在此实验中,我们使用Glue 的爬网程序自动解析存储在s3桶中的原始数据,自动创建了表。通过Glue数据库中的表,我们可以使用Athena对表进行查询(Athena每次检索表对应的s3桶数据,按检索量收费)。接下来我们会对原始数据进行转换、清洗以及分区操作,以及使用API Gateway+Lambda实现一个无服务架构,通过API查询数据。
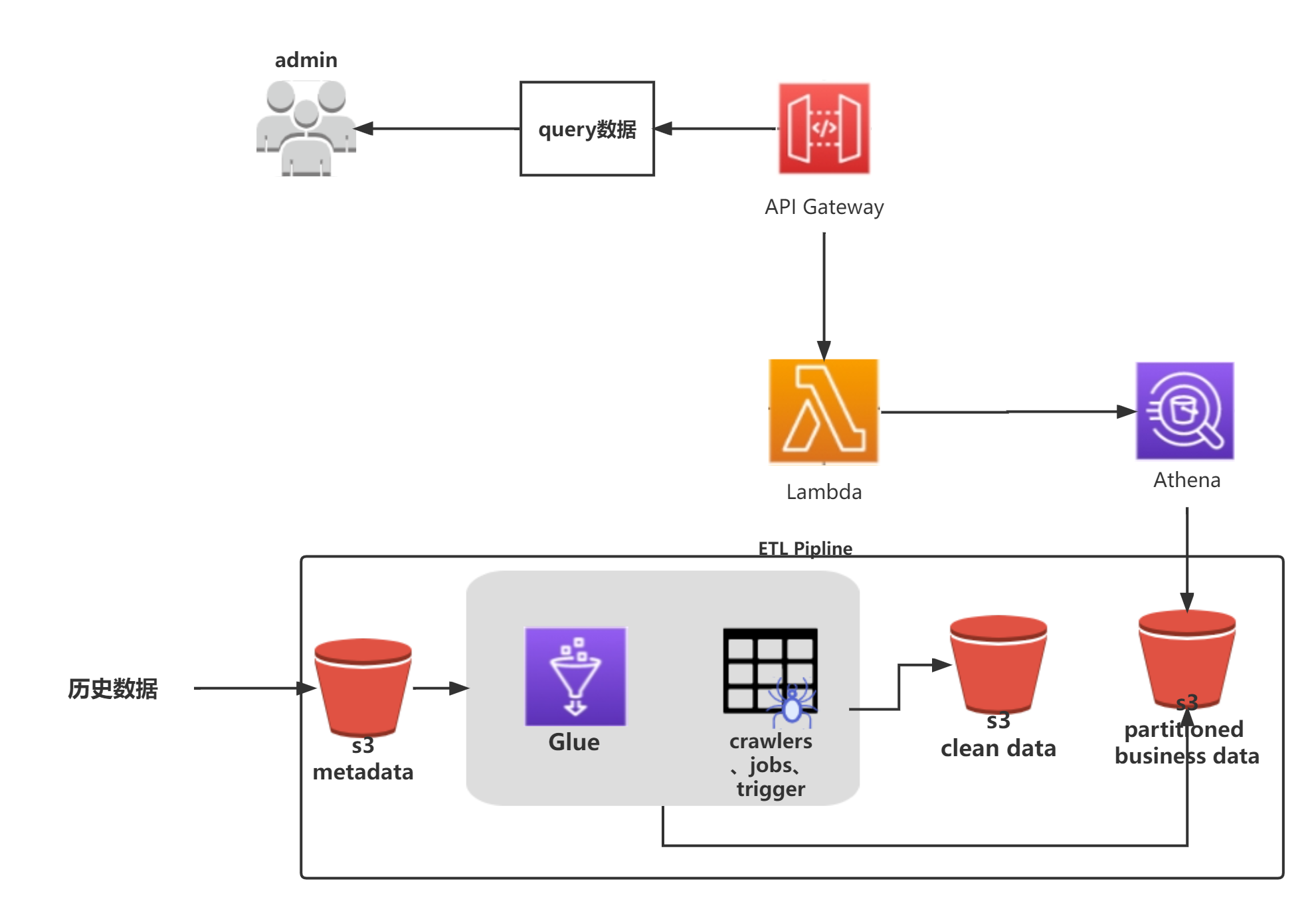
1 通过Athena查询s3中的数据
1.1 架构图
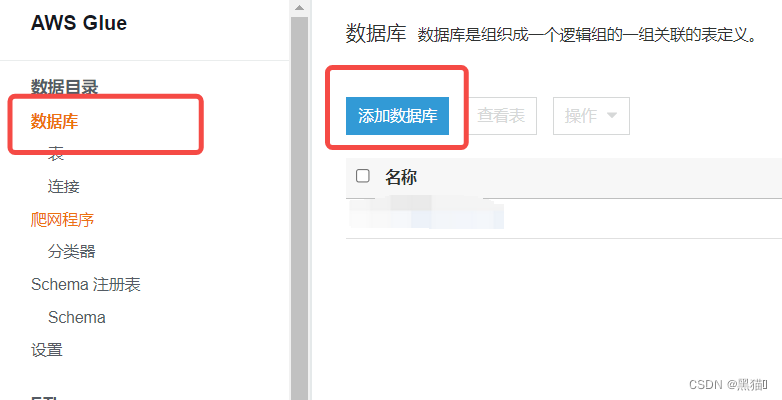
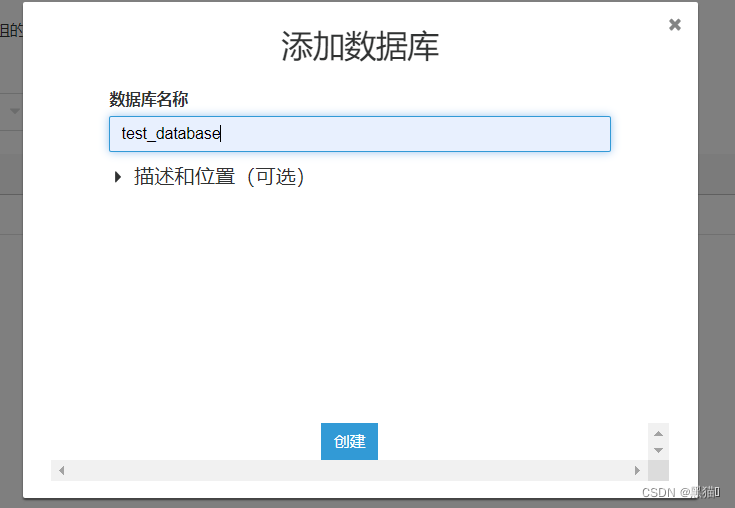
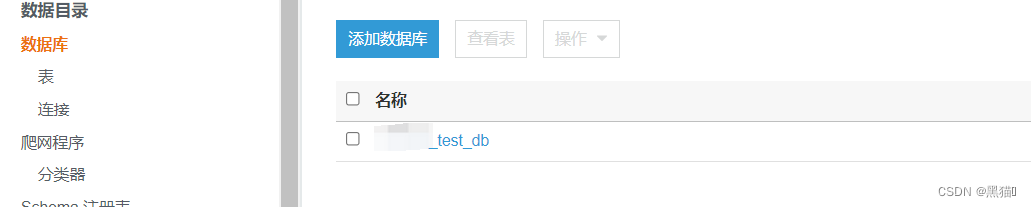
1.2 创建Glue数据库
首先我们需要创建一个数据库。我们将会使用爬网程序来填充我们的数据目录。
1.3 创建爬网程序
在任务中,我们经常会使用Glue爬网程序来填充我们的数据目录。
爬虫可以在一次运行中爬取多个数据存储。在爬取完成后,我们会在数据目录中看到由爬虫创建的一个或多个表。
创建表后,我们就可以在接下来的Athena查询或ETL作业中使用表来作为源或目标了。
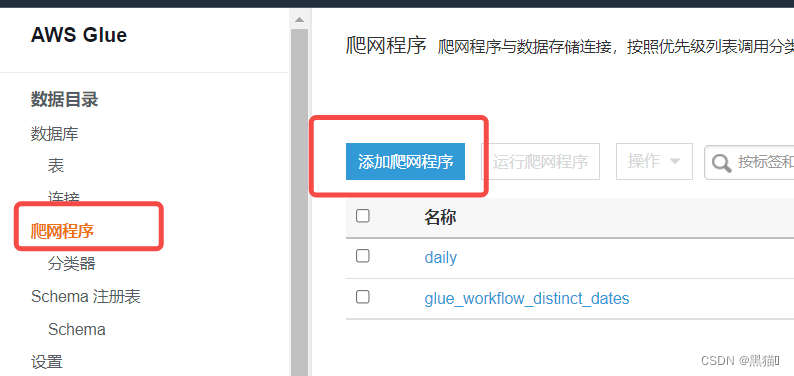
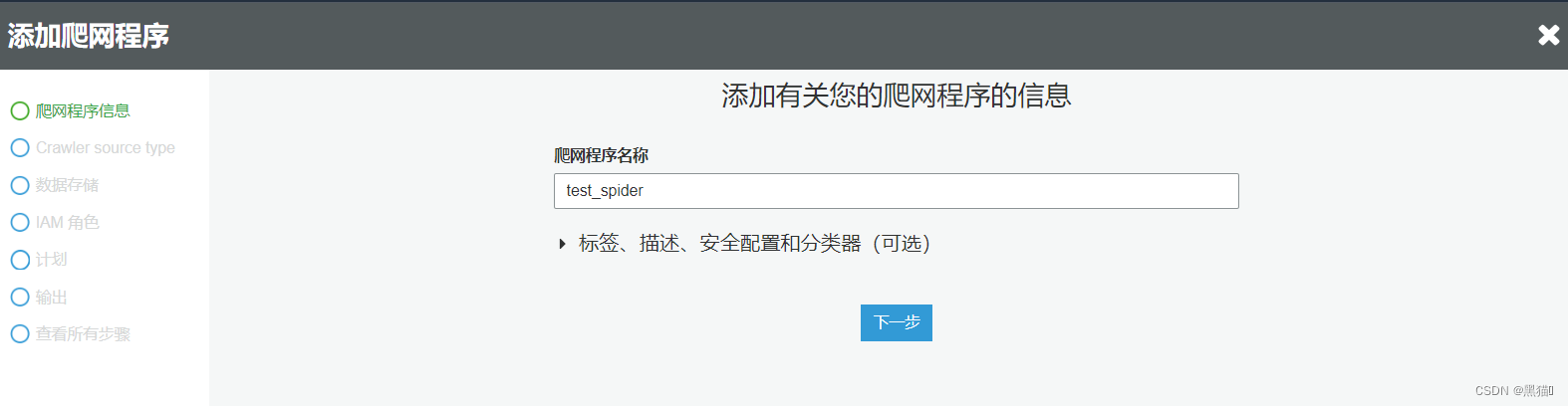
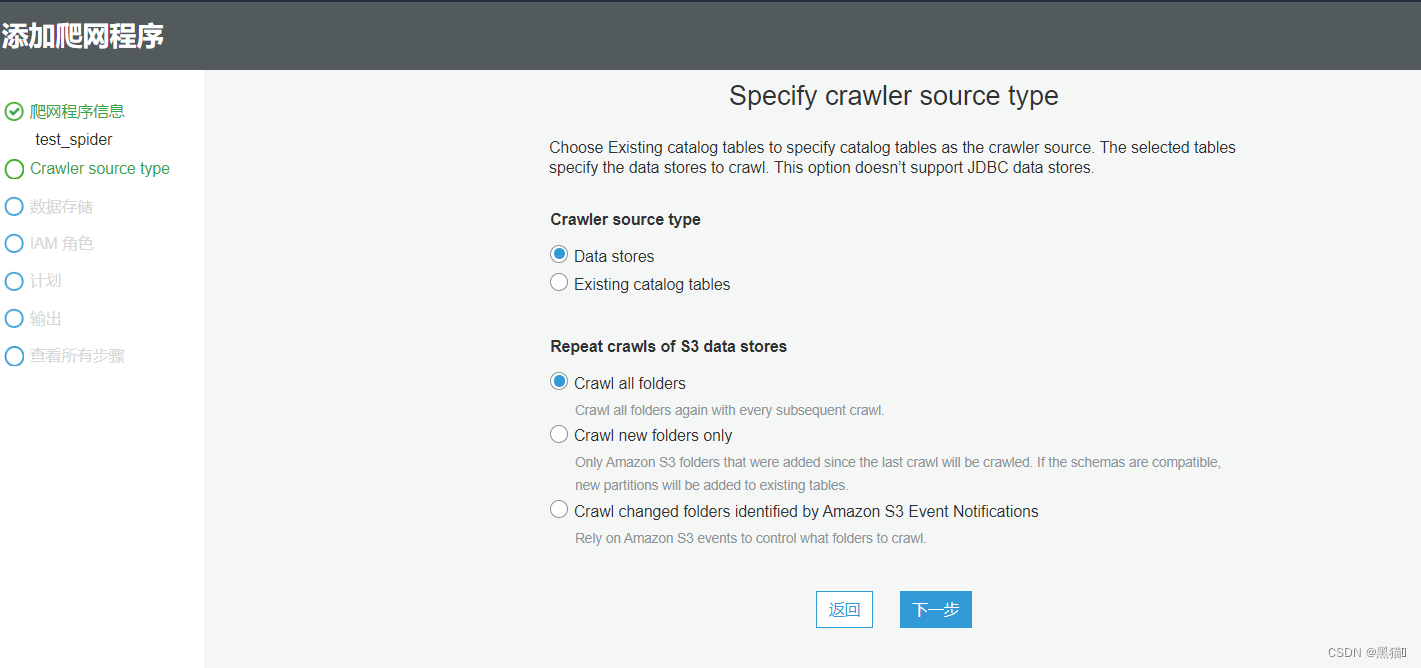
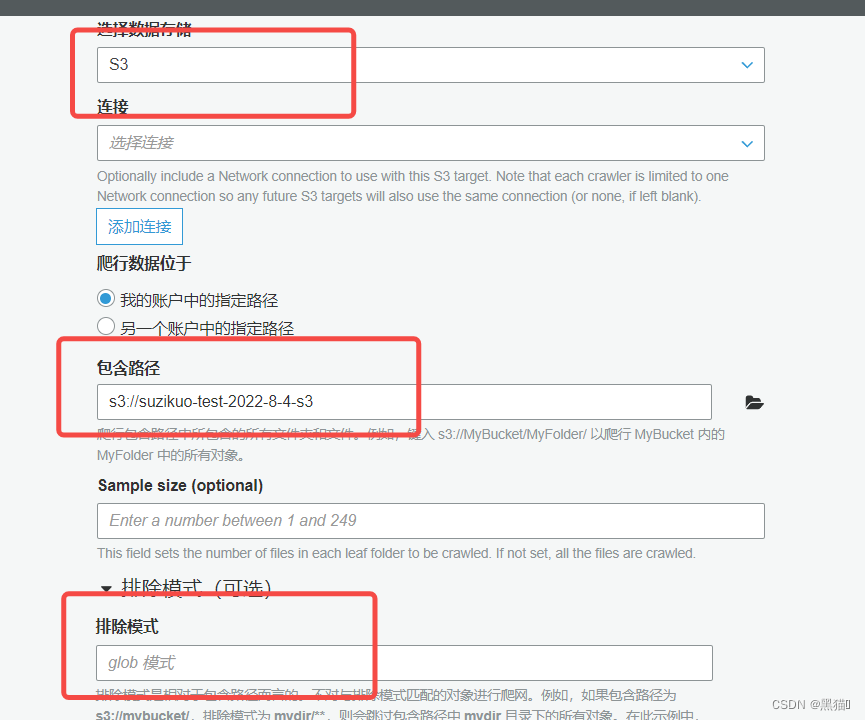
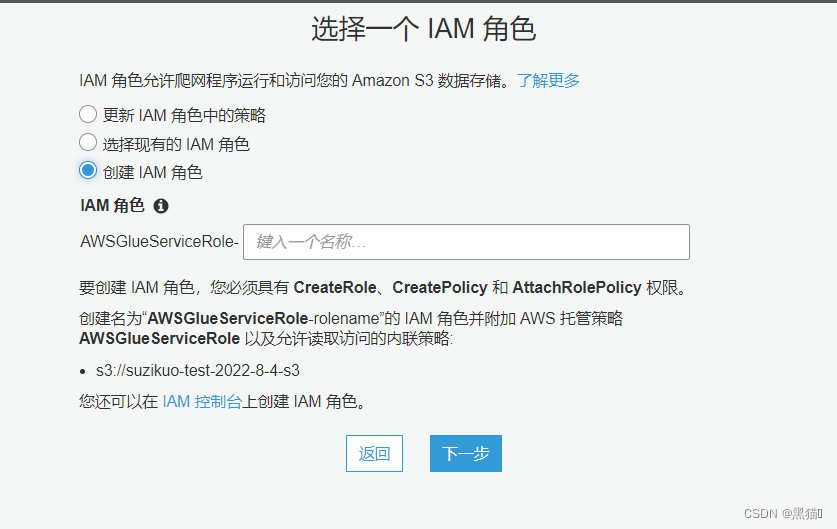
此时,数据库与爬网程序已准备完毕。
我们将会运行爬网程序自动分析数据结构并创建表。
1.4 创建表
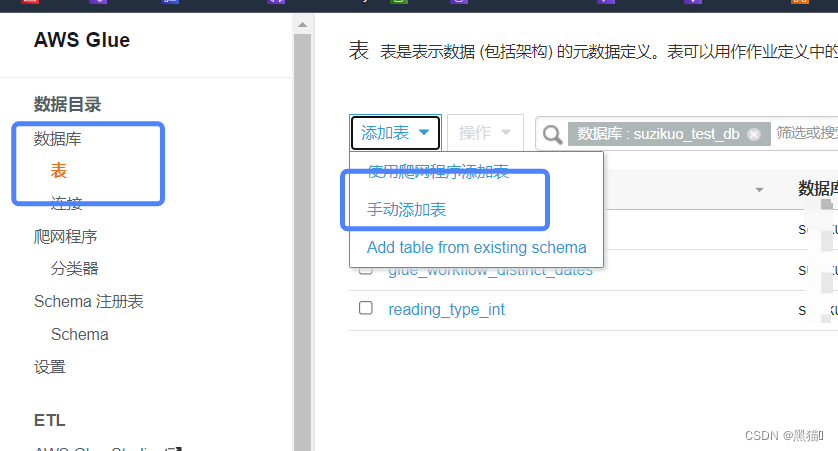
如果对待爬取数据结构未知,或者结构复杂、字段繁杂,则使用“爬网程序创建表”;对于对待爬取数据结构清晰明了的,可以使用“手动创建表”模式。
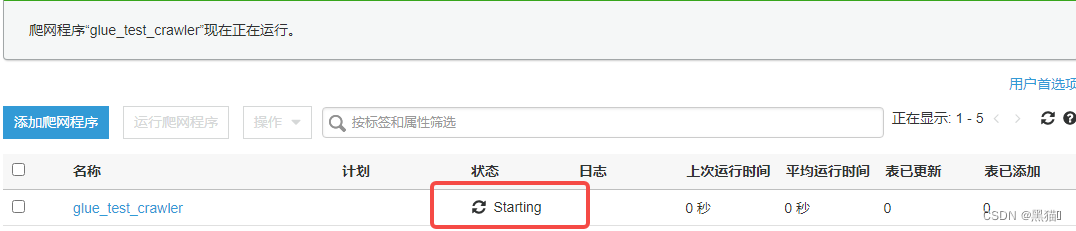
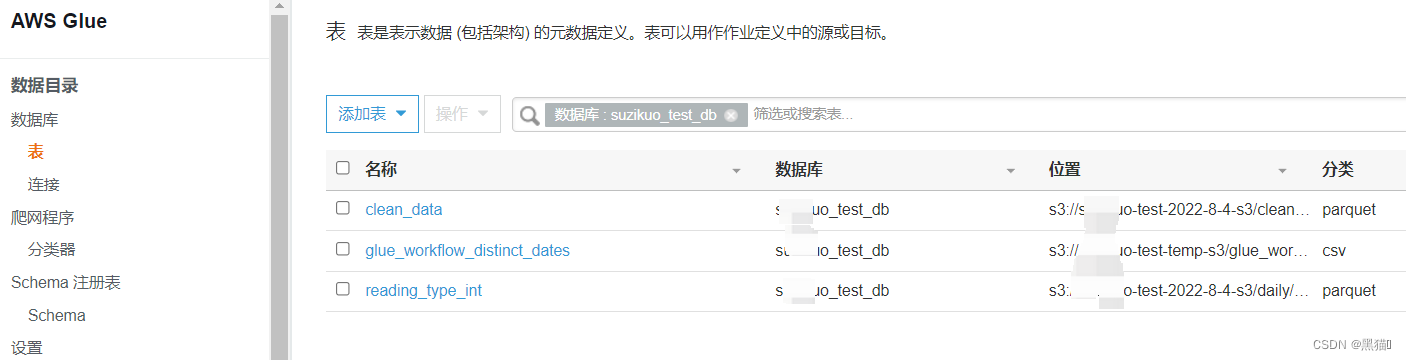
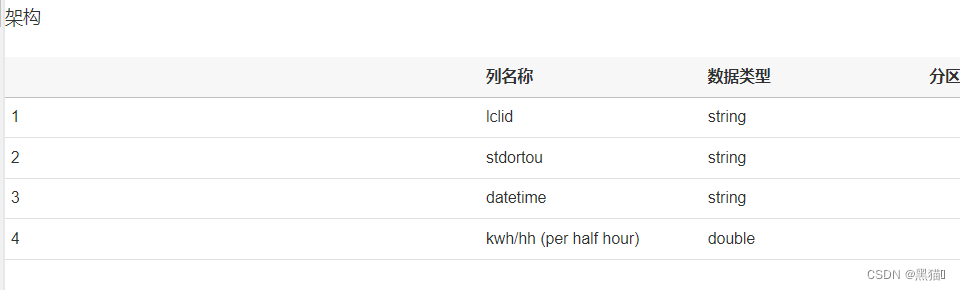
1.4.1 爬网程序创建表


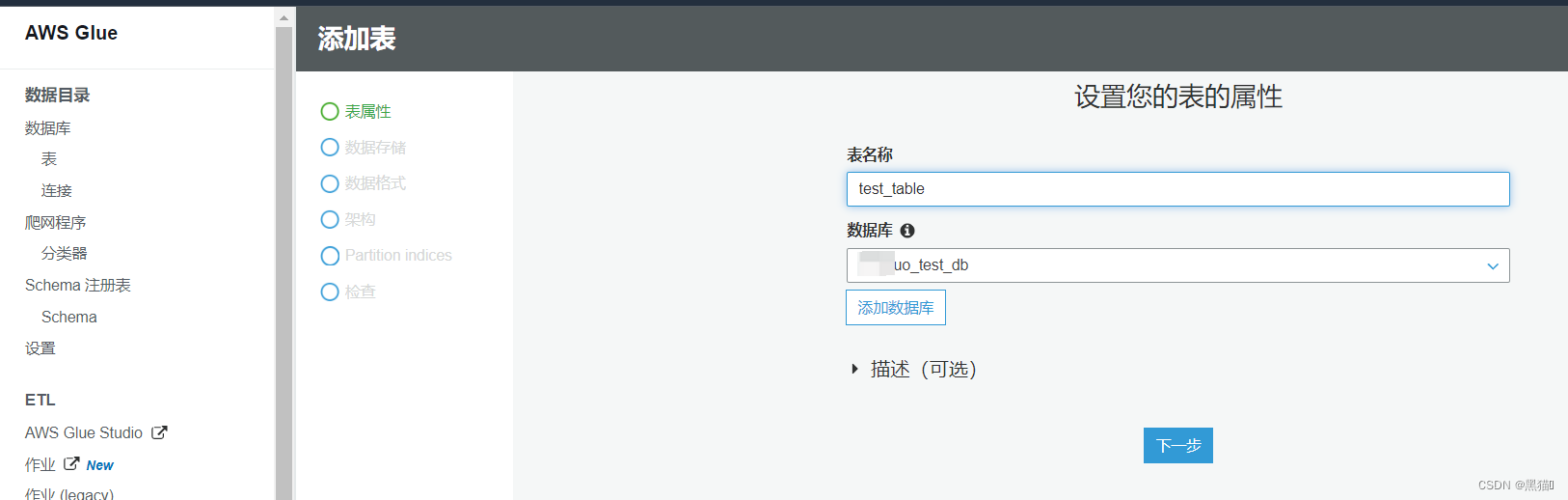
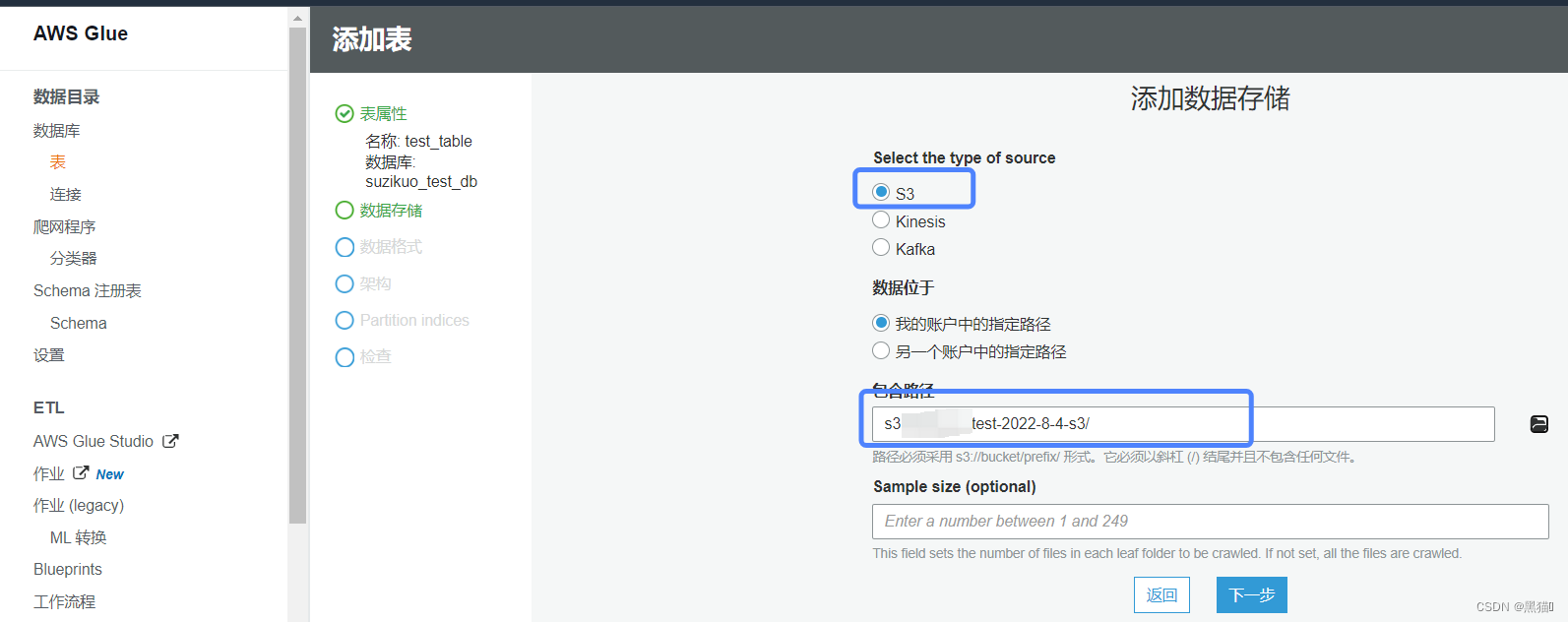
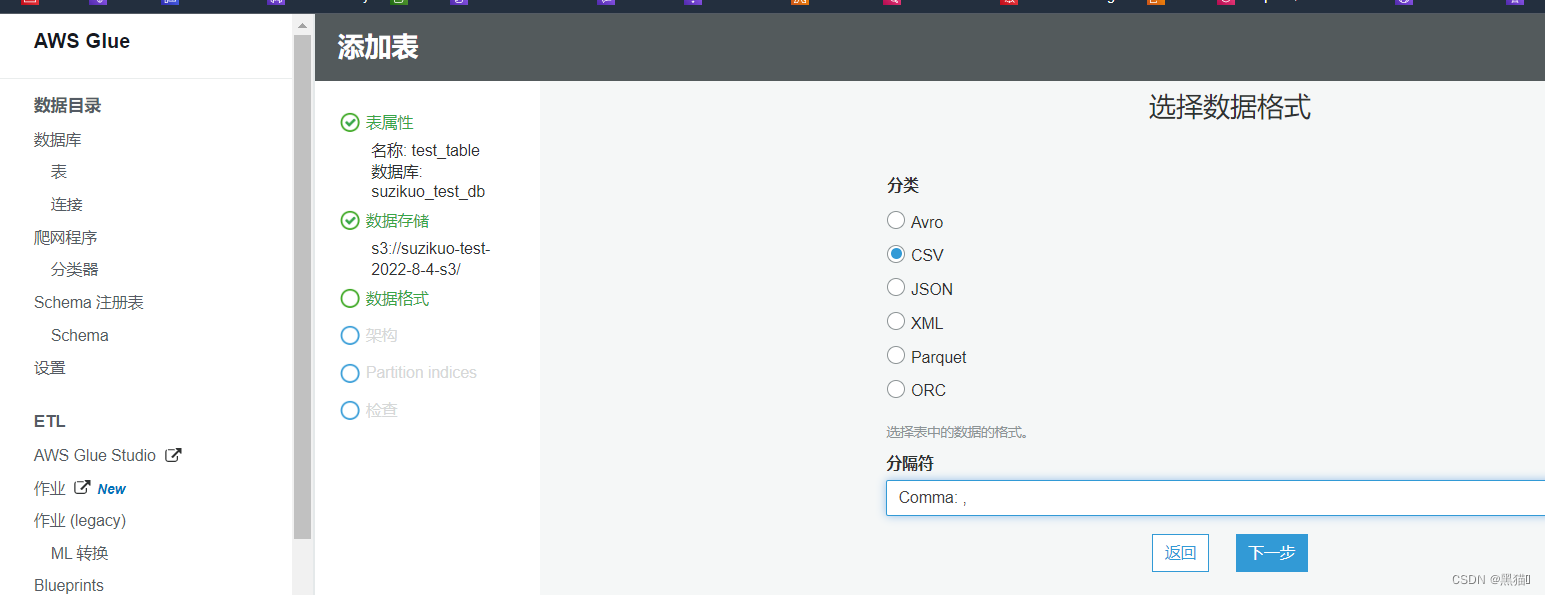
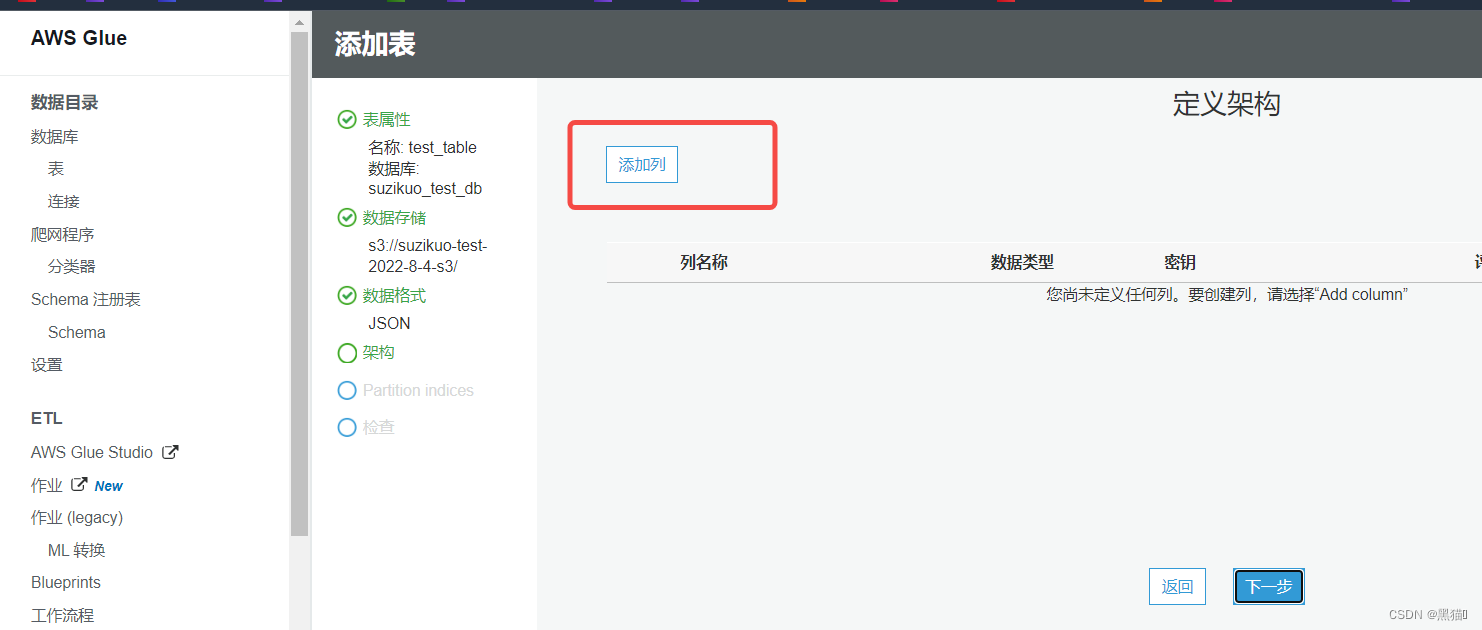
1.4.2 手动创建表
1.5 Athena查询
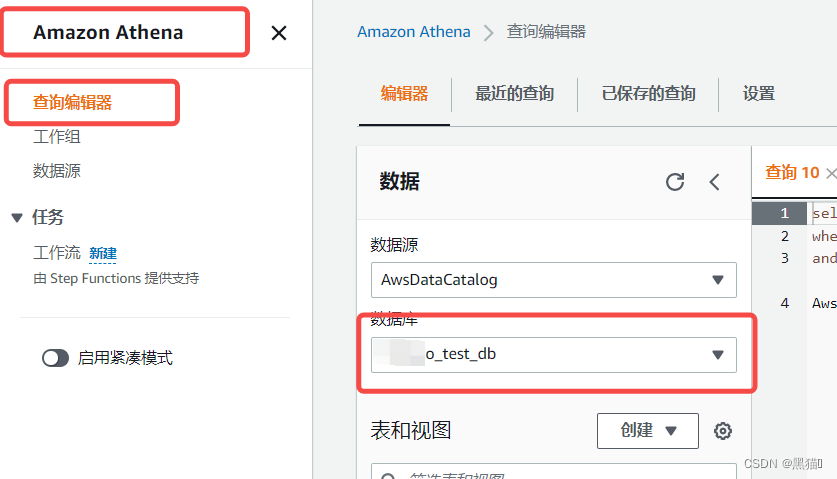
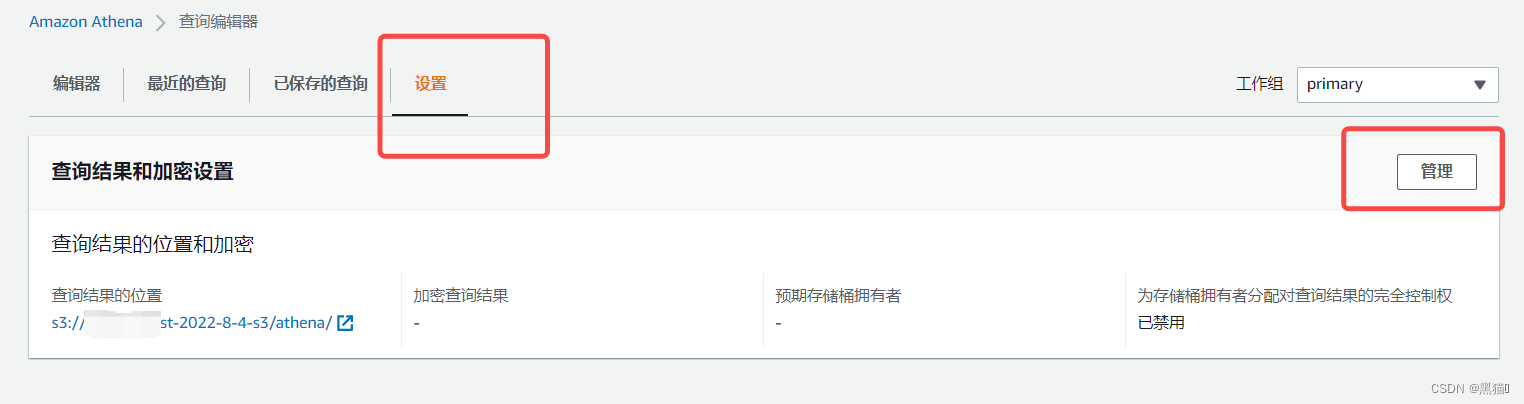
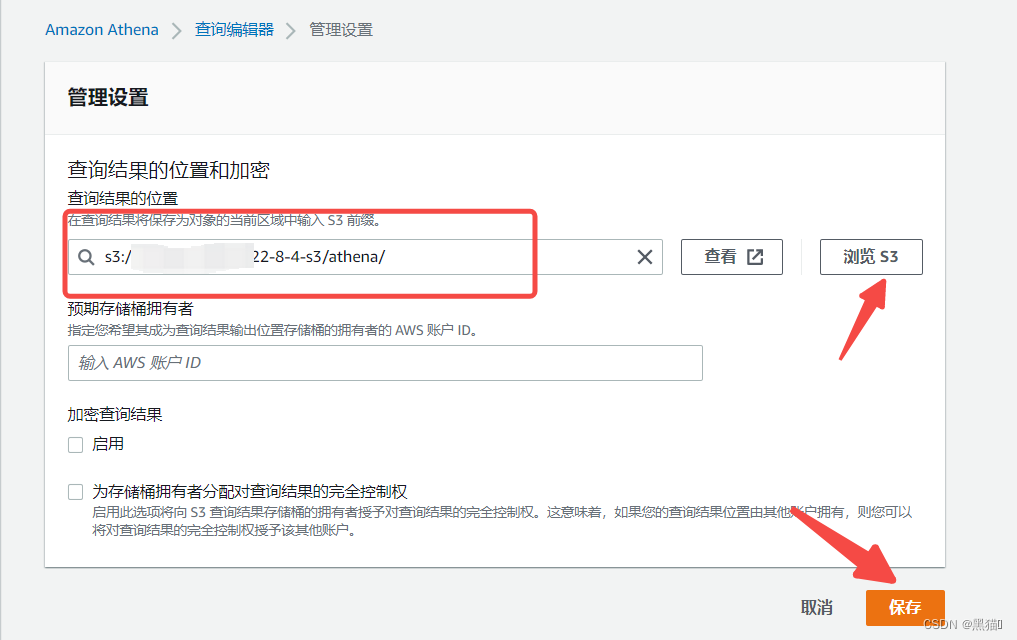
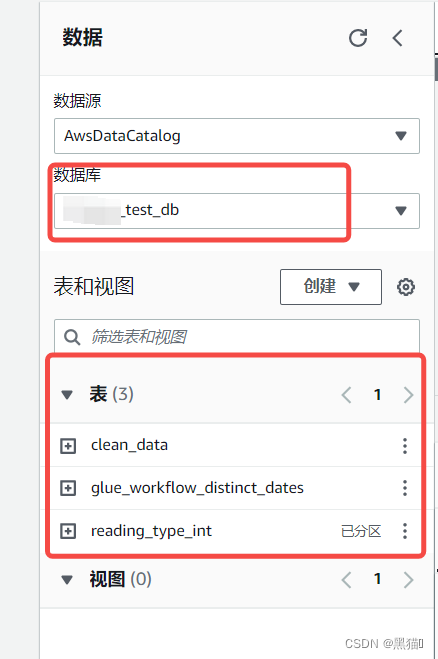
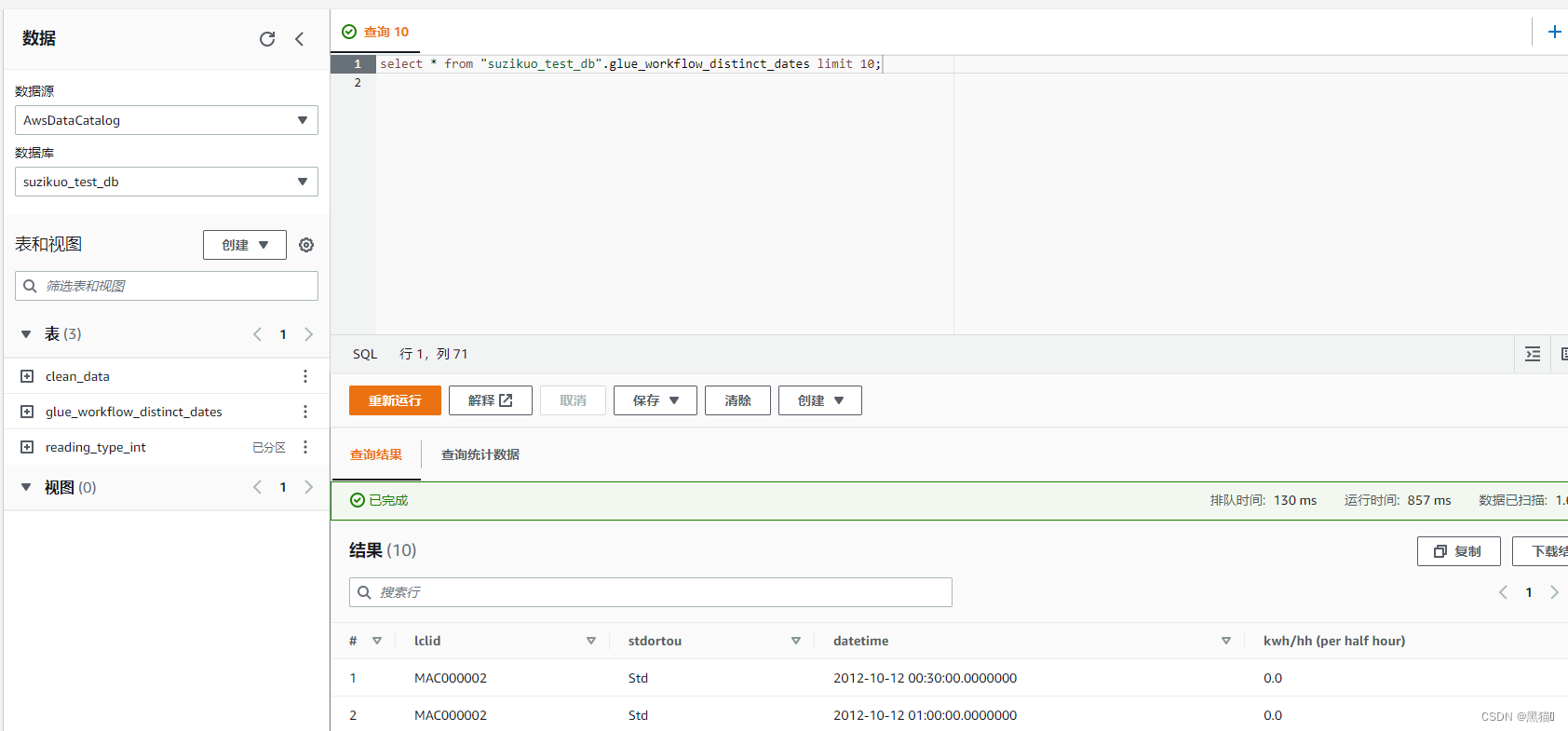
1.6 总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。