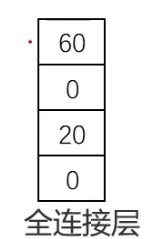
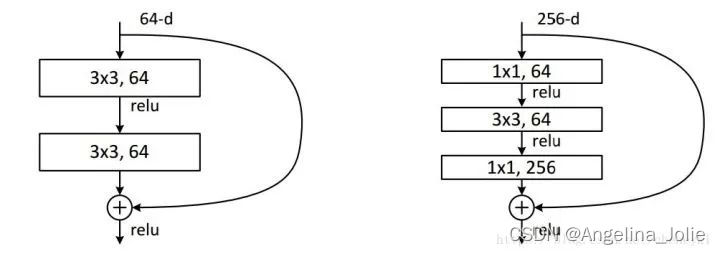
本文介绍: 使用1*1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3*3,64channels的卷积核后面添加一个1*1,28channels的卷积核,就变成了3*3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。右侧操作数:w*h*256*1*1*64 + w*h*64*3*3*64 +w*h*64*1*1*256 = 69632*w*h,,左侧参数大概是右侧的8.5倍。(实现降维,减少参数)
一、来源:[1312.4400] Network In Network (如果1×1卷积核接在普通的卷积层后面,配合激活函数,即可实现network in network的结构)
二、应用:GoogleNet中的Inception、ResNet中的残差模块
三、作用:
1、降维(减少参数)


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。