1.迁移学习
迁移学习是一种机器学习方法,它通过将已经在一个任务上学习到的知识应用到另一个相关任务上,来改善模型的性能。迁移学习可以解决数据不足或标注困难的问题,同时可以加快模型的训练速度。
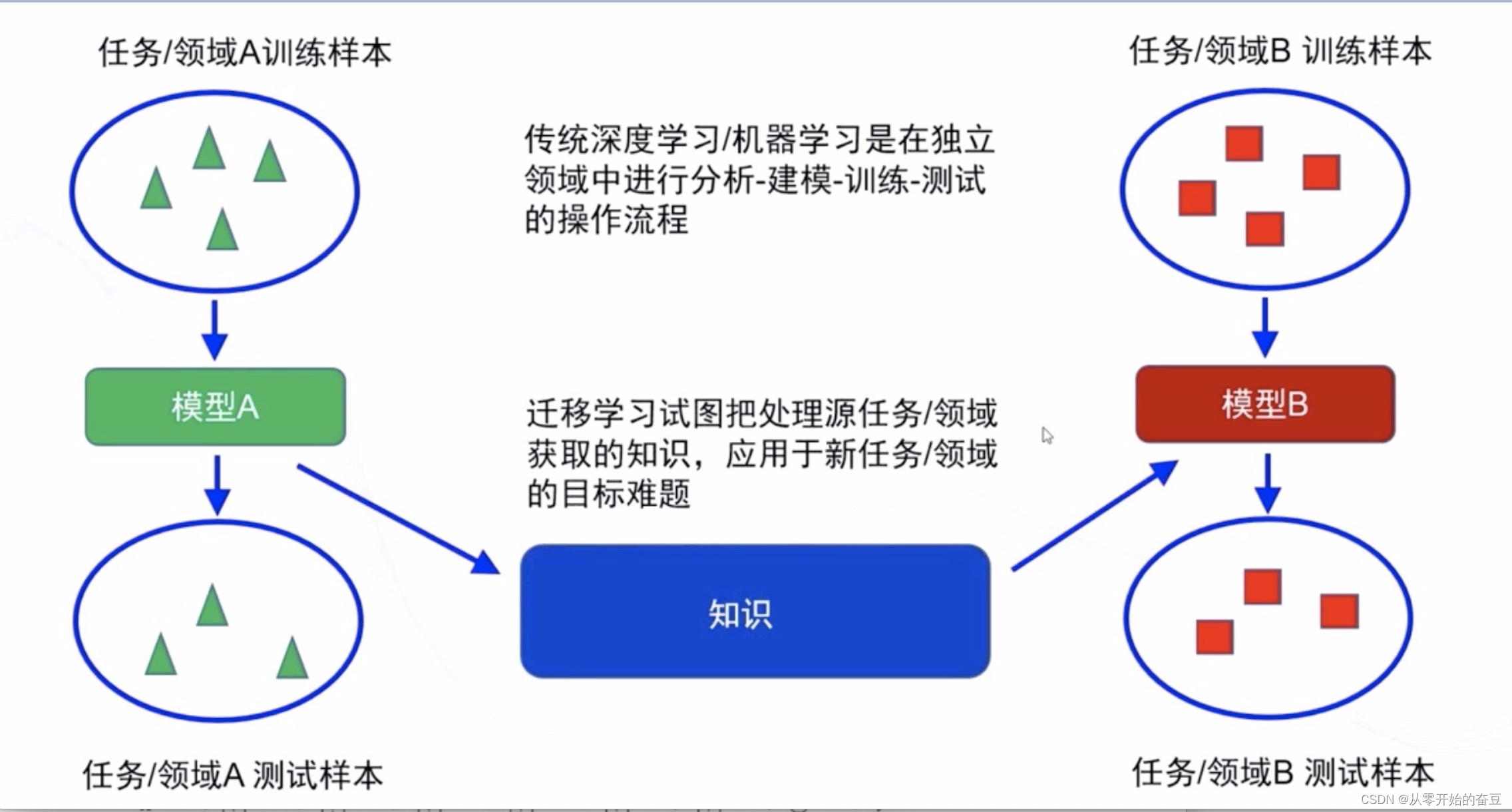
迁移学习的核心思想是将源领域的知识迁移到目标领域中。源领域是已经有大量标注数据的领域,而目标领域是需要解决的新问题。通过迁移学习,源领域的知识可以帮助目标领域的学习过程,提高模型的泛化能力和性能。
迁移学习可以通过多种方式实现,包括特征提取、模型微调和领域自适应等方法。特征提取是将源领域的特征应用到目标领域中,模型微调是在源模型的基础上对目标模型进行调整,领域自适应则是通过对目标领域进行适应性训练来提高性能。
迁移学习在计算机视觉、自然语言处理等领域都有广泛的应用。它可以帮助解决许多实际问题,提高模型的效果和效率。
1.1分类
-
基于实例的迁移学习(Instance–based Transfer Learning):
基于实例的迁移学习是将源任务中的实例样本直接应用于目标任务。这种方法通常通过调整实例的权重或选择一部分实例来实现。例如,如果源任务是图像分类,目标任务是目标检测,可以将源任务中的图像样本用作目标任务的训练数据,从而提供更多的样本和多样性。 -
基于特征的迁移学习(Feature–based Transfer Learning):
基于特征的迁移学习是将源任务的特征表示应用于目标任务。这种方法通常通过共享特征提取器或调整特征的权重来实现。例如,在计算机视觉中,可以使用预训练的卷积神经网络(CNN)作为特征提取器,将其冻结或微调,并将其特征用于目标任务的训练。 -
基于模型的迁移学习(Model-based Transfer Learning):
基于模型的迁移学习是将源任务的模型应用于目标任务。这种方法通常通过微调源模型或在源模型的基础上构建新模型来实现。例如,在自然语言处理中,可以使用预训练的语言模型(如BERT)作为源模型,然后在目标任务上微调该模型,以适应目标任务的特定要求。 -
基于关系的迁移学习(Relation–based Transfer Learning):
基于关系的迁移学习是通过学习源任务和目标任务之间的关系,来进行知识迁移和模型优化。这种方法通常通过学习源任务和目标任务之间的相似性、相关性或映射关系来实现。例如,在推荐系统中,可以通过学习用户和物品之间的关系,将源任务中学习到的用户兴趣模型应用于目标任务中,以提高推荐的准确性和个性化程度。
1.2训练技巧
-
预训练模型(Pretrained Models):使用在大规模数据集上预训练好的模型作为迁移学习的起点,可以帮助提取通用的特征表示。这些预训练模型可以是在类似任务上训练得到的,也可以是在其他领域的任务上训练得到的。
-
微调(Fine-tuning):在迁移学习中,可以将预训练模型的部分或全部参数作为初始参数,然后在目标任务上进行微调。通过在目标任务上进行有限的训练,可以使模型适应目标任务的特定要求,同时保留预训练模型的通用特征。
-
冻结层(Freezing Layers):在微调过程中,可以选择冻结预训练模型的一部分或全部层,只更新目标任务相关的层。这样可以防止过拟合和减少训练时间,尤其在目标任务数据较少的情况下效果更明显。
-
数据增强(Data Augmentation):通过对目标任务的数据进行增强,如旋转、翻转、裁剪等操作,可以扩充数据集的多样性,提高模型的泛化能力。
-
领域自适应(Domain Adaptation):当源任务和目标任务的数据分布存在差异时,可以通过领域自适应技术来减小领域间的差距。例如,使用领域自适应方法对源领域和目标领域进行特征对齐或实例重权,以提高模型在目标领域上的性能。
-
多任务学习(Multi–task Learning):当源任务和目标任务之间存在相关性时,可以将它们作为多个任务一起进行训练。通过共享模型参数和学习任务间的关系,可以提高模型的泛化能力和效果。
2.resnet50
ResNet-50是一种深度残差网络(Residual Network),是ResNet系列中的一种经典模型。它由微软研究院的Kaiming He等人于2015年提出,被广泛应用于计算机视觉任务,如图像分类、目标检测和图像分割等。
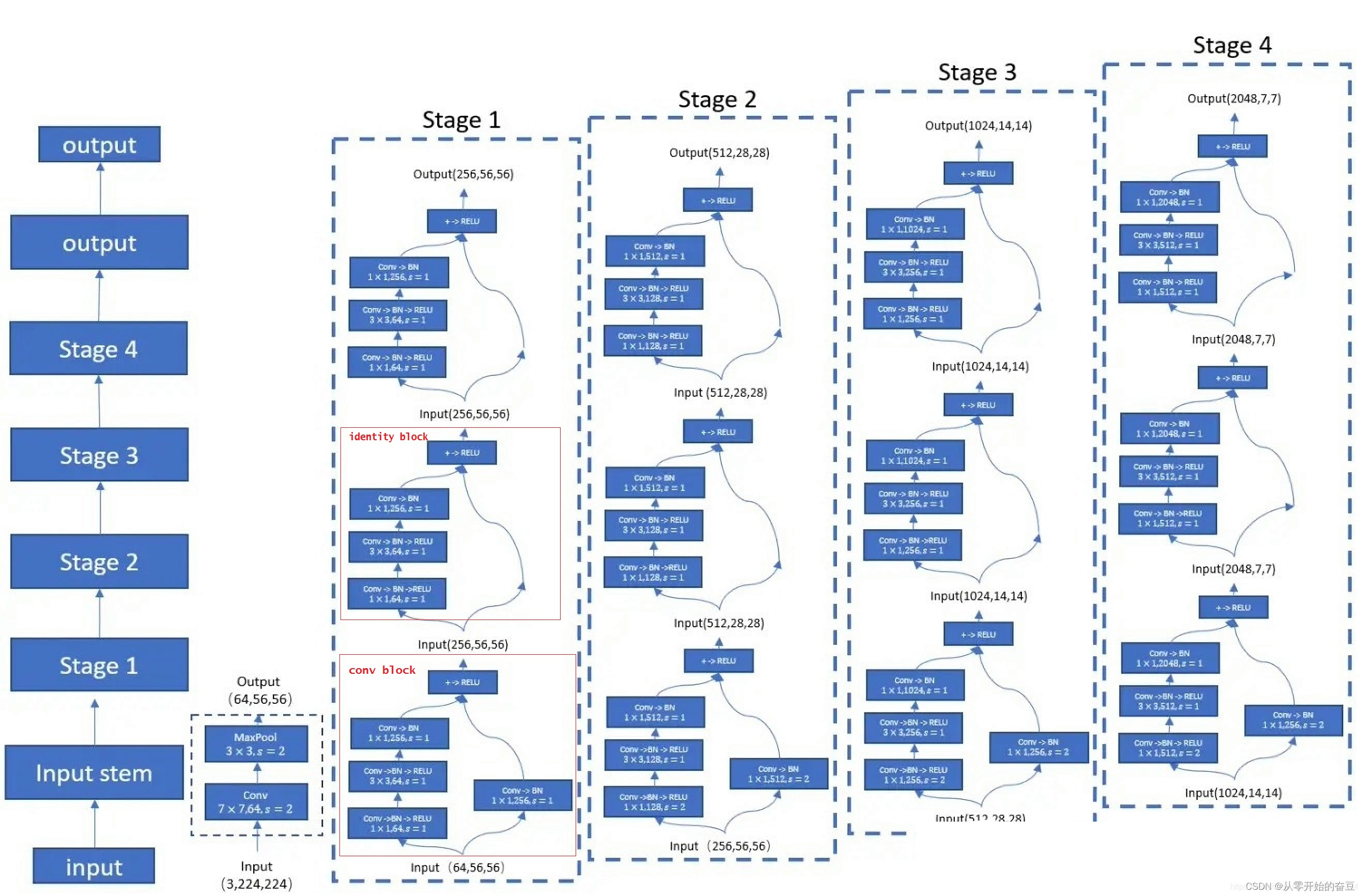
2.1 Convolutional Block和Identity Block
ResNet-50有两个基本块Convolutional Block和Identity Block。
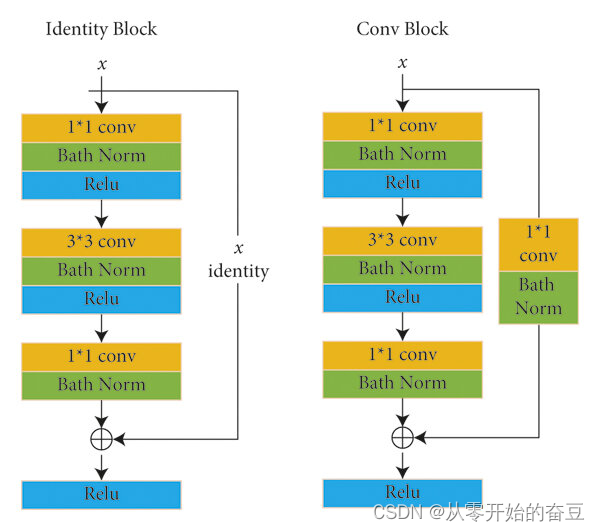
-
Convolutional Block(卷积块):Convolutional Block由一系列卷积层组成,用于学习图像的特征。它的典型结构是:
-
Identity Block(恒等块):Identity Block由三个卷积层组成,其中第一个和第三个卷积层是1x1卷积层,中间的卷积层是3×3卷积层。它的结构如下:
Identity Block的输入和输出具有相同的维度,通过跳跃连接(skip connection)将输入直接添加到输出上,保留了原始输入的信息。
ResNet-50通过堆叠Convolutional Block和Identity Block来构建整个网络。这些块的设计使得ResNet-50能够更深更容易训练,并且在图像分类等任务上取得了很好的性能。
2.2 批归一化(Batch Normalization)层
ResNet-50使用了对批归一化(Batch Normalization)层。

批归一化是一种常用的正则化技术,用于加速神经网络的训练过程并提高模型的性能。在ResNet-50中,批归一化层通常在卷积层之后、激活函数之前应用。
批归一化的作用是对每个小批量的输入进行归一化处理,使得输入的均值接近于0,方差接近于1。这有助于缓解梯度消失和梯度爆炸问题,提高网络的稳定性和收敛速度。
- 对于每个通道,计算小批量输入的均值和方差。
- 使用计算得到的均值和方差对小批量输入进行归一化。
- 对归一化后的输入进行缩放和平移,通过可学习的参数进行调整。
- 最后,通过激活函数对调整后的输入进行非线性变换。
批归一化层的引入有助于加速训练过程,提高模型的泛化能力,并且可以允许使用更高的学习率。在ResNet-50中,批归一化层的使用有助于网络的训练和性能的提升。
3.代码实现
3.1数据集
# 下载数据集
dataset_url = "https://s3.amazonaws.com/fast-ai-imageclas/imagewoof2-160.tgz"
download_url(dataset_url, '.')
# 提取压缩文件
with tarfile.open('./imagewoof2-160.tgz', 'r:gz') as tar:
tar.extractall(path='./data')
# 查看数据目录中的内容
data_dir = './data/imagewoof2-160'
print(os.listdir(data_dir))
classes = os.listdir(data_dir + "/train")
print(classes)

数据进行增强和归一化,创建数据加载器,划分数据集,这里由于我的设备跑不动,所以只加载了25分之一。
# 数据转换(归一化和数据增强)
stats = ((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
train_tfms = tt.Compose([tt.RandomCrop(160, padding=4, padding_mode='reflect'),
tt.RandomHorizontalFlip(),
tt.ToTensor(),
tt.Normalize(*stats,inplace=True)])
valid_tfms = tt.Compose([tt.Resize([160,160]),tt.ToTensor(), tt.Normalize(*stats)])
# 创建ImageFolder对象
train_ds = ImageFolder(data_dir+'/train', train_tfms)
valid_ds = ImageFolder(data_dir+'/val', valid_tfms)
print(f'训练数据集长度 = {len(train_ds)}')
print(f'验证数据集长度 = {len(valid_ds)}')
# 计算数据集中的样本数量
num_samples = int(len(train_ds)/25)
print(num_samples)
# 创建一个随机索引
indices = list(range(num_samples))
# 打乱索引
random.shuffle(indices)
# 设置训练集的大小
train_size = int(0.8 * num_samples)
# 创建训练集和验证集的索引
train_indices = indices[:train_size]
valid_indices = indices[train_size:]
# 创建训练集和验证集的随机抽样器
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(valid_indices)
# 设置批量大小
batch_size = 64
# 创建训练集和验证集的数据加载器
train_dl = DataLoader(train_ds, batch_size=32, sampler=train_sampler)
valid_dl = DataLoader(valid_ds, batch_size=32, sampler=valid_sampler)
""" # PyTorch数据加载器
# 创建数据加载器
train_dl = DataLoader(train_ds, batch_size, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size*2) """
#展示数据
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 12))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images[:64], nrow=8, normalize=True).permute(1, 2, 0))
break
plt.show()
show_batch(train_dl)
3.2 设置设备
#设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
train_dl = DeviceDataLoader(train_dl, device)
valid_dl = DeviceDataLoader(valid_dl, device)
3.3加载resnet50网络结构
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], last_lr: {:.5f}, train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(
epoch, result['lrs'][-1], result['train_loss'], result['val_loss'], result['val_acc']))
class Resnet50(ImageClassificationBase):
def __init__(self):
super().__init__()
# Use a pretrained model
self.network = models.resnet50(pretrained=True)
# Replace last layer
num_ftrs = self.network.fc.in_features
self.network.fc = nn.Linear(num_ftrs, 10)
def forward(self, xb):
return torch.sigmoid(self.network(xb))
def freeze(self):
# To freeze the residual layers
for param in self.network.parameters():
param.require_grad = False
for param in self.network.fc.parameters():
param.require_grad = True
def unfreeze(self):
# Unfreeze all layers
for param in self.network.parameters():
param.require_grad = True
model = to_device(Resnet50(), device)
3.4训练及保存模型
# Set up cutom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)
# Set up one-cycle learning rate scheduler
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs,
steps_per_epoch=len(train_loader))
这段代码首先定义了一个优化器 optimizer,它使用余弦退火(Cosine Annealing)策略进行学习率调度。余弦退火是一种常用的学习率调度策略,它可以在训练过程中缓慢增加学习率,然后在训练过程中缓慢减小学习率,从而实现更高效的训练。
接着,代码定义了一个 OneCycleLR 学习率调度器,它根据余弦退火策略调整学习率。max_lr 参数表示最大学习率,epochs 参数表示总共有多少个训练 epoch,steps_per_epoch 参数表示每个 epoch 中有多少个迭代步骤。
最后,代码将优化器 optimizer 和学习率调度器 sched 分别赋值给模型 model。
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
with torch.no_grad():
for data,target in val_loader:
output = model(data)
pred = output.argmax(dim=1,keepdim=True)
return model.validation_epoch_end(outputs),pred
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader,
weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):
torch.cuda.empty_cache()
history = []
# Set up cutom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)
# Set up one-cycle learning rate scheduler
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs,
steps_per_epoch=len(train_loader))
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
lrs = []
print("Epoch: ", epoch+1)
for batch in tqdm(train_loader):
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
# Gradient clipping
if grad_clip:
nn.utils.clip_grad_value_(model.parameters(), grad_clip)
optimizer.step()
optimizer.zero_grad()
# Record & update learning rate
lrs.append(get_lr(optimizer))
sched.step()
# Validation phase
result,pred = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
result['lrs'] = lrs
model.epoch_end(epoch, result)
history.append(result)
return history
history = []
print(history)
#训练
model.freeze()
epochs = 10
max_lr = 0.0001
grad_clip = 0.1
weight_decay = 1e-4
opt_func = torch.optim.Adam
""" history += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl,
grad_clip=grad_clip,
weight_decay=weight_decay,
opt_func=opt_func)
def plot_accuracies(history):
accuracies = [x['val_acc'] for x in history]
plt.plot(accuracies, '-x')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Accuracy vs. No. of epochs')
plt.show()
plot_accuracies(history)
torch.save(model.state_dict(), 'RES.pth') """
3.5预测
model.load_state_dict(torch.load('RES.pth'))
r,result=evaluate(model, valid_dl)
print(result)
data_loader_iter = iter(valid_dl)
while True:
try:
item = next(data_loader_iter)
# 对 item 进行处理
image, label = item
except StopIteration:
break
images=image.numpy()
labels=label.numpy()
fig = plt.figure(figsize=(25,4))
for idx in np.arange(9):
ax = fig.add_subplot(1,9, idx+1, xticks=[], yticks=[])
ax.imshow(images[idx][0])
ax.set_title('real:'+str(labels[idx].item())+'ped:'+str(result[idx].item()))
plt.show()

4.总代码
import os
import torch
import torchvision
import tarfile
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
from torchvision.datasets.utils import download_url
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import torchvision.transforms as tt
from torchvision.utils import make_grid
import torchvision.models as models
import matplotlib.pyplot as plt
from tqdm import tqdm
from torch.utils.data.sampler import SubsetRandomSampler
import random
#matplotlib inline
# 下载数据集
dataset_url = "https://s3.amazonaws.com/fast-ai-imageclas/imagewoof2-160.tgz"
download_url(dataset_url, '.')
# 提取压缩文件
with tarfile.open('./imagewoof2-160.tgz', 'r:gz') as tar:
tar.extractall(path='./data')
# 查看数据目录中的内容
data_dir = './data/imagewoof2-160'
print(os.listdir(data_dir))
classes = os.listdir(data_dir + "/train")
print(classes)
# 数据转换(归一化和数据增强)
stats = ((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
train_tfms = tt.Compose([tt.RandomCrop(160, padding=4, padding_mode='reflect'),
tt.RandomHorizontalFlip(),
tt.ToTensor(),
tt.Normalize(*stats,inplace=True)])
valid_tfms = tt.Compose([tt.Resize([160,160]),tt.ToTensor(), tt.Normalize(*stats)])
# 创建ImageFolder对象
train_ds = ImageFolder(data_dir+'/train', train_tfms)
valid_ds = ImageFolder(data_dir+'/val', valid_tfms)
print(f'训练数据集长度 = {len(train_ds)}')
print(f'验证数据集长度 = {len(valid_ds)}')
# 计算数据集中的样本数量
num_samples = int(len(train_ds)/25)
print(num_samples)
# 创建一个随机索引
indices = list(range(num_samples))
# 打乱索引
random.shuffle(indices)
# 设置训练集的大小
train_size = int(0.8 * num_samples)
# 创建训练集和验证集的索引
train_indices = indices[:train_size]
valid_indices = indices[train_size:]
# 创建训练集和验证集的随机抽样器
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(valid_indices)
# 设置批量大小
batch_size = 64
# 创建训练集和验证集的数据加载器
train_dl = DataLoader(train_ds, batch_size=32, sampler=train_sampler)
valid_dl = DataLoader(valid_ds, batch_size=32, sampler=valid_sampler)
""" # PyTorch数据加载器
# 创建数据加载器
train_dl = DataLoader(train_ds, batch_size, shuffle=True)
valid_dl = DataLoader(valid_ds, batch_size*2) """
#展示数据
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 12))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images[:64], nrow=8, normalize=True).permute(1, 2, 0))
break
plt.show()
show_batch(train_dl)
#设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def get_default_device():
"""Pick GPU if available, else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader():
"""Wrap a dataloader to move data to a device"""
def __init__(self, dl, device):
self.dl = dl
self.device = device
def __iter__(self):
"""Yield a batch of data after moving it to device"""
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
"""Number of batches"""
return len(self.dl)
train_dl = DeviceDataLoader(train_dl, device)
valid_dl = DeviceDataLoader(valid_dl, device)
#基于批量归一化的预训练 ResNet 模型的定义
def accuracy(outputs, labels):
_, preds = torch.max(outputs, dim=1)
return torch.tensor(torch.sum(preds == labels).item() / len(preds))
class ImageClassificationBase(nn.Module):
def training_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
return loss
def validation_step(self, batch):
images, labels = batch
out = self(images) # Generate predictions
loss = F.cross_entropy(out, labels) # Calculate loss
acc = accuracy(out, labels) # Calculate accuracy
return {'val_loss': loss.detach(), 'val_acc': acc}
def validation_epoch_end(self, outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean() # Combine losses
batch_accs = [x['val_acc'] for x in outputs]
epoch_acc = torch.stack(batch_accs).mean() # Combine accuracies
return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
def epoch_end(self, epoch, result):
print("Epoch [{}], last_lr: {:.5f}, train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(
epoch, result['lrs'][-1], result['train_loss'], result['val_loss'], result['val_acc']))
class Resnet50(ImageClassificationBase):
def __init__(self):
super().__init__()
# Use a pretrained model
self.network = models.resnet50(pretrained=True)
# Replace last layer
num_ftrs = self.network.fc.in_features
self.network.fc = nn.Linear(num_ftrs, 10)
def forward(self, xb):
return torch.sigmoid(self.network(xb))
def freeze(self):
# To freeze the residual layers
for param in self.network.parameters():
param.require_grad = False
for param in self.network.fc.parameters():
param.require_grad = True
def unfreeze(self):
# Unfreeze all layers
for param in self.network.parameters():
param.require_grad = True
model = to_device(Resnet50(), device)
print(model)
#fit函数
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
with torch.no_grad():
for data,target in val_loader:
output = model(data)
pred = output.argmax(dim=1,keepdim=True)
return model.validation_epoch_end(outputs),pred
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def fit_one_cycle(epochs, max_lr, model, train_loader, val_loader,
weight_decay=0, grad_clip=None, opt_func=torch.optim.SGD):
torch.cuda.empty_cache()
history = []
# Set up cutom optimizer with weight decay
optimizer = opt_func(model.parameters(), max_lr, weight_decay=weight_decay)
# Set up one-cycle learning rate scheduler
sched = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, epochs=epochs,
steps_per_epoch=len(train_loader))
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
lrs = []
print("Epoch: ", epoch+1)
for batch in tqdm(train_loader):
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
# Gradient clipping
if grad_clip:
nn.utils.clip_grad_value_(model.parameters(), grad_clip)
optimizer.step()
optimizer.zero_grad()
# Record & update learning rate
lrs.append(get_lr(optimizer))
sched.step()
# Validation phase
result,pred = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
result['lrs'] = lrs
model.epoch_end(epoch, result)
history.append(result)
return history
history = []
print(history)
#训练
model.freeze()
epochs = 10
max_lr = 0.0001
grad_clip = 0.1
weight_decay = 1e-4
opt_func = torch.optim.Adam
""" history += fit_one_cycle(epochs, max_lr, model, train_dl, valid_dl,
grad_clip=grad_clip,
weight_decay=weight_decay,
opt_func=opt_func)
def plot_accuracies(history):
accuracies = [x['val_acc'] for x in history]
plt.plot(accuracies, '-x')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Accuracy vs. No. of epochs')
plt.show()
plot_accuracies(history)
torch.save(model.state_dict(), 'RES.pth') """
model.load_state_dict(torch.load('RES.pth'))
r,result=evaluate(model, valid_dl)
print(result)
data_loader_iter = iter(valid_dl)
while True:
try:
item = next(data_loader_iter)
# 对 item 进行处理
image, label = item
except StopIteration:
break
images=image.numpy()
labels=label.numpy()
fig = plt.figure(figsize=(25,4))
for idx in np.arange(9):
ax = fig.add_subplot(1,9, idx+1, xticks=[], yticks=[])
ax.imshow(images[idx][0])
ax.set_title('real:'+str(labels[idx].item())+'ped:'+str(result[idx].item()))
plt.show()
原文地址:https://blog.csdn.net/m0_68926749/article/details/134792237
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_42634.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





