本文介绍: 如果iframe有唯一的名称或ID,最好使用名称或ID来切换到iframe。如果存在多个iframe并且可以根据其在页面中的位置来区分,可以使用索引来切换到特定的iframe。如果已经通过其他方式定位到了iframe的WebElement对象,可以直接使用该对象来切换到iframe。2.通过名称或ID:如果iframe具有名称或ID属性,可以通过名称或ID来切换到该iframe。如果已经定位到iframe的WebElement对象,可以直接使用该对象来切换到该iframe。仅供学习参考,请勿用于数据获取。
使用selenium对模拟登录获取内部数据
要求:
网站:
前置知识点:
高级xpath:
在XPath语法中,可以使用以下方式表示最后一个标签和第一个标签:
请注意,XPath中的索引从1开始计数,而不是从0开始计数。
切换页面:
当使用switch_to.frame()方法切换到iframe时,参数可以是以下几种形式之一:
2.通过名称或ID:如果iframe具有名称或ID属性,可以通过名称或ID来切换到该iframe。可以将名称或ID作为字符串传递给switch_to.frame()方法。例如,switch_to.frame("myframe")表示切换到名称或ID为”myframe”的iframe。
3.通过WebElement:可以将表示iframe的WebElement对象作为参数传递给switch_to.frame()方法。如果已经定位到iframe的WebElement对象,可以直接使用该对象来切换到该iframe。
思路:

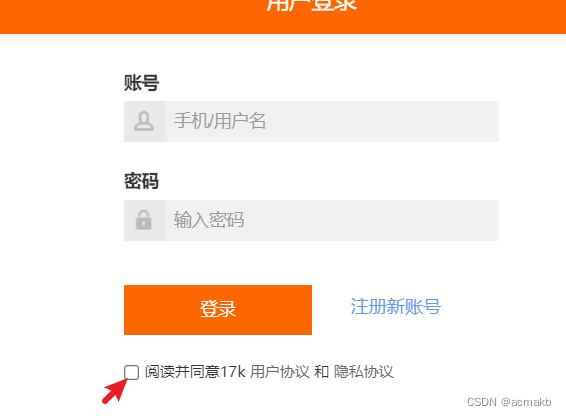
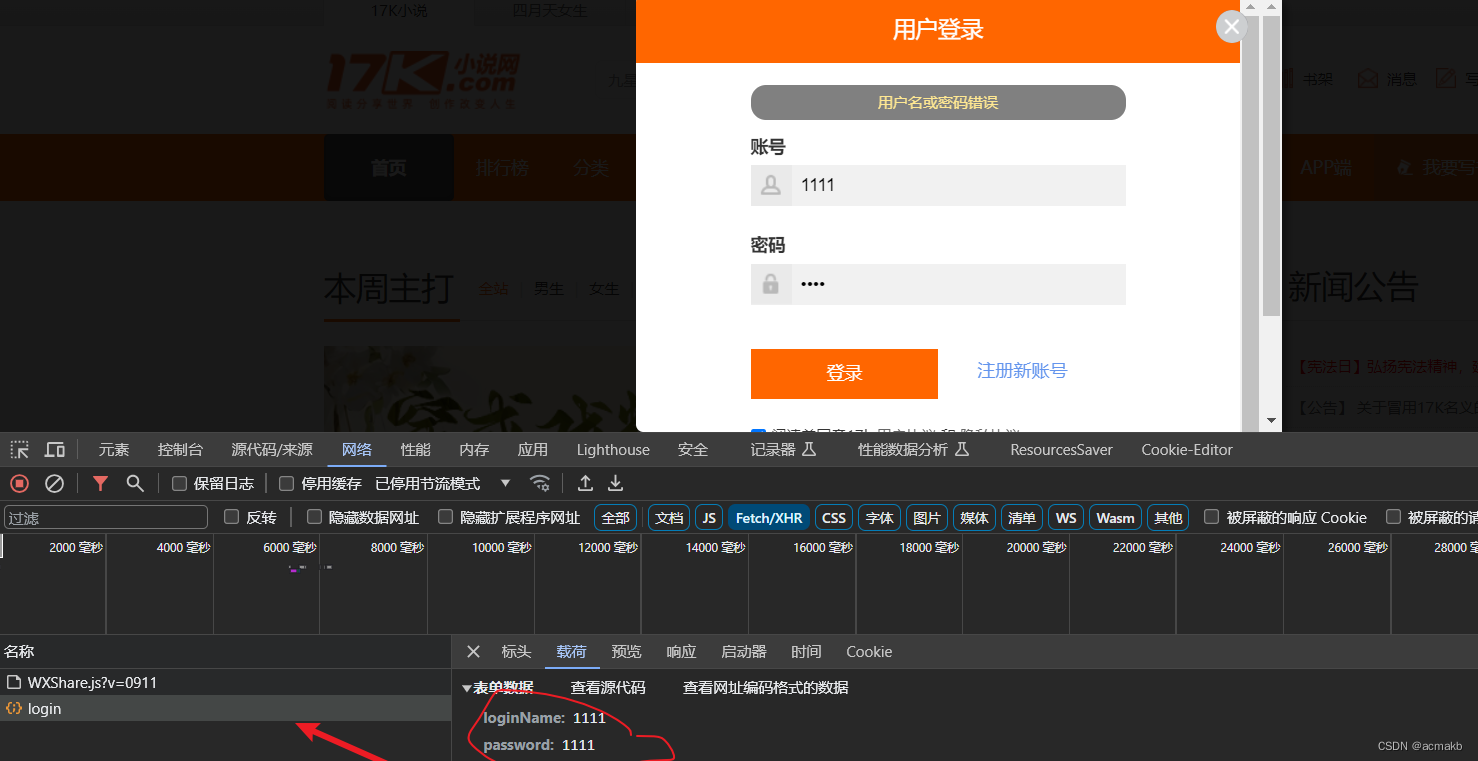




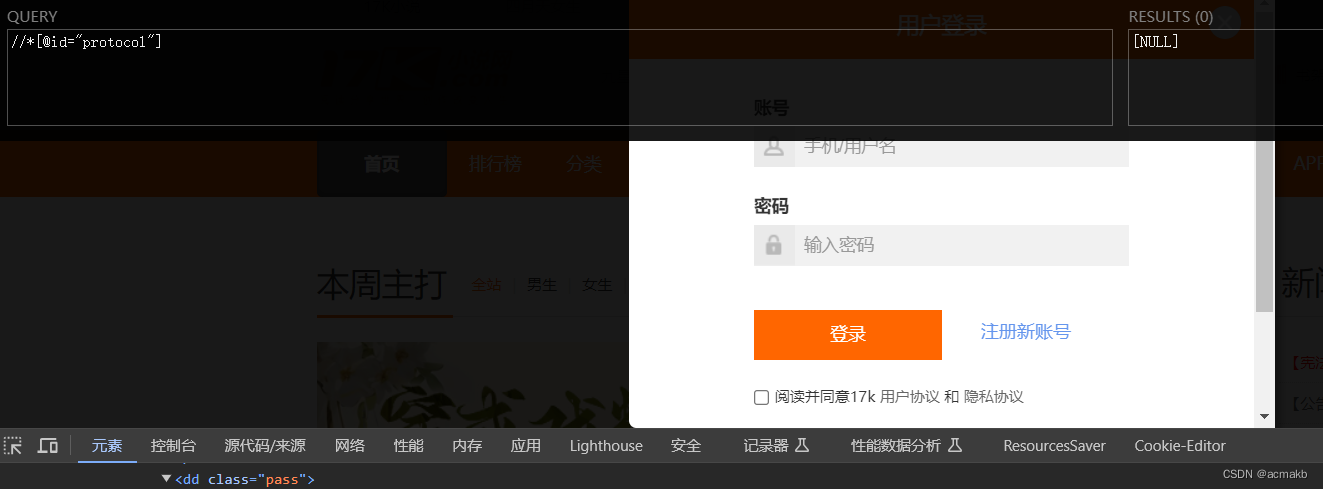

完整代码:
温馨提示:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。