本文介绍: 这一点应该是很容易理解的,因为缓存不关心方法的执行逻辑,它能确定的是:对于同一个方法,如果参数相同,那么返回结果也是相同的。但是如果参数不同,缓存只能假设结果是不同的,所以对于同一个方法,你的程序运行过程中,使用了多少种参数组合调用过该方法,理论上就会生成多少个缓存的 key(当然,这些组合的参数指的是与生成 key 相关的)。也就是说,该方法的返回结果会放在缓存中,以便于以后使用相同的参数调用该方法时,会返回缓存中的值,而不会实际执行该方法。通常来讲,缓存管理器是与缓存组件类型相关联的。
1. 功能说明
@Cacheable 注解在方法上,表示该方法的返回结果是可以缓存的。也就是说,该方法的返回结果会放在缓存中,以便于以后使用相同的参数调用该方法时,会返回缓存中的值,而不会实际执行该方法。
注意,这里强调了一点:参数相同。这一点应该是很容易理解的,因为缓存不关心方法的执行逻辑,它能确定的是:对于同一个方法,如果参数相同,那么返回结果也是相同的。但是如果参数不同,缓存只能假设结果是不同的,所以对于同一个方法,你的程序运行过程中,使用了多少种参数组合调用过该方法,理论上就会生成多少个缓存的 key(当然,这些组合的参数指的是与生成 key 相关的)。下面来了解一下 @Cacheable 的一些参数:
2. cacheNames & value
@Cacheable 提供两个参数来指定缓存名:value、cacheNames,二者选其一即可。这是 @Cacheable 最简单的用法示例:
![]()
3. 关联多个缓存名
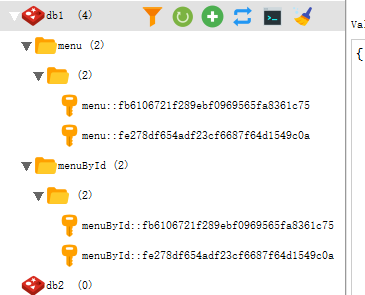
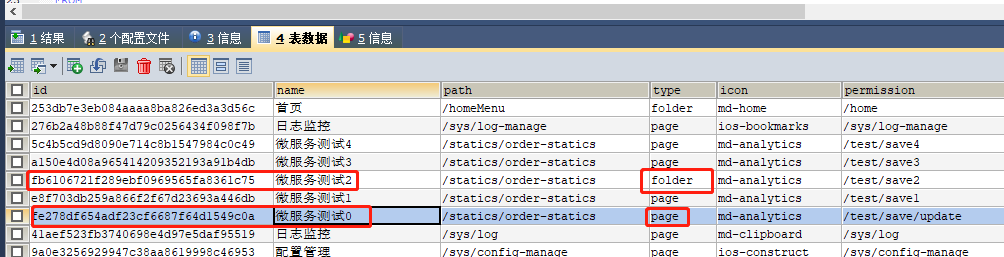
4. key & keyGenerator
4.1. KeyGenerator 自动生成
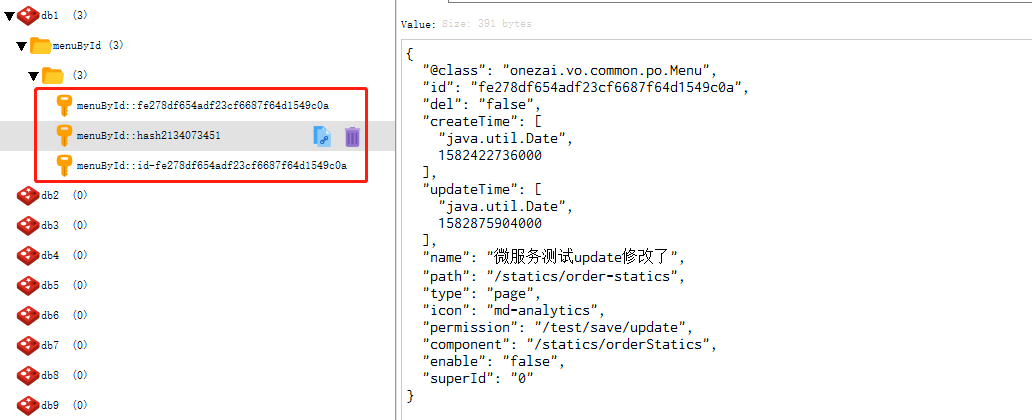
4.2. 显式指定 key
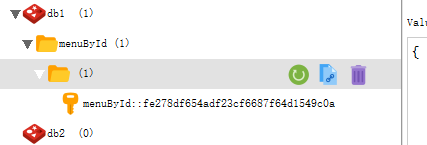
5. cacheManager & cacheResolver
6. sync
7. condition

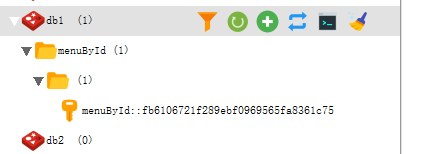



8. unless


9. condition VS unless ?



声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。