枚举与Sized 数据
一般数据类型的布局是其大小(size)、对齐方式(align)及其字段的相对偏移量。
1. 枚举(Enum)的布局:
枚举类型在内存中的布局通常是由编译器来确定的。不同的编译器可能有不同的实现方式。一般来说,枚举的大小通常与其底层表示的整数类型相同,例如 enum 定义为 int 类型的大小。对于不同的枚举成员,编译器会分配不同的整数值。但是具体如何进行编码和布局是由编译器实现规定的。
在某些情况下,编译器可能会优化枚举类型的大小,特别是当枚举类型的取值在一个较小的范围内时,编译器可能会选择使用较小的整数类型来表示。
2. Sized 数据类型:
在 Rust 编程语言中,Sized 是一个特性(trait),用于表示大小在编译时是已知的类型。所有 Rust 中的类型默认都是 Sized 的,除非使用特殊的语法标记为 ?Sized,表示可能是动态大小的类型。
Rust 中的 size_of 和 align_of 函数可以用于获取类型的大小和对齐方式:
数字类型
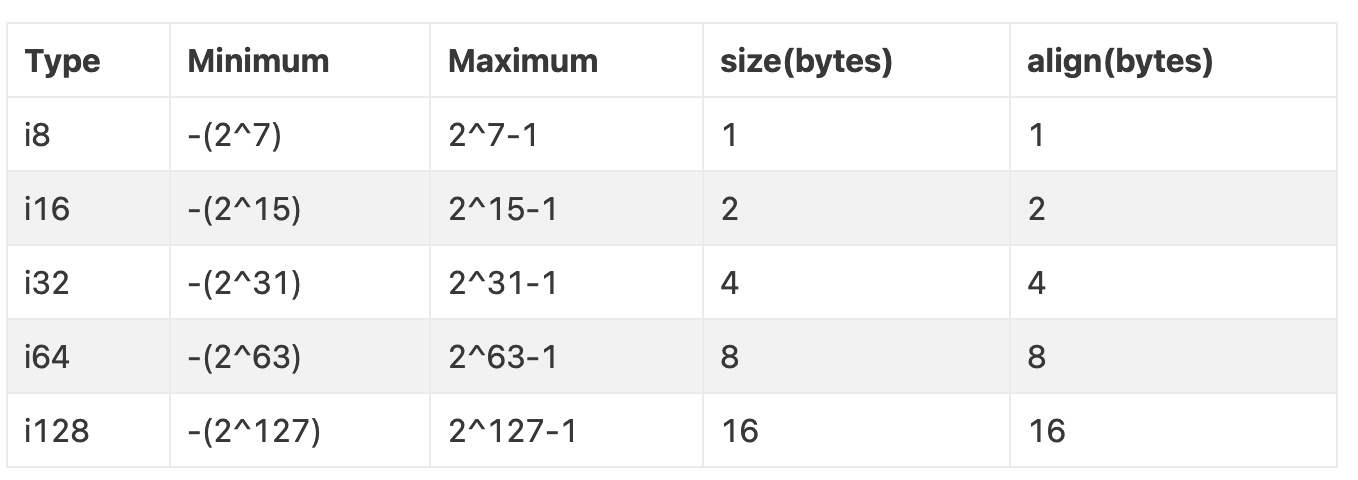
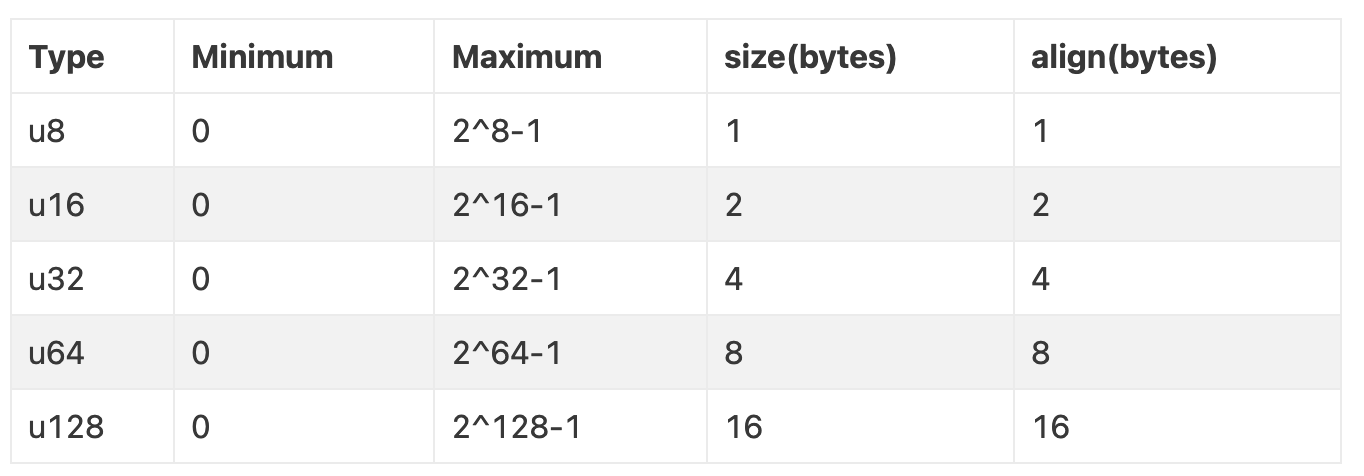
整数类型(Integer Types):
浮点数类型(Floating-Point Types):
 这些数字类型在内存中以固定大小进行
这些数字类型在内存中以固定大小进行usized 、isized
bool
数组
内存布局:
示例:
str类型
1. char 类型:
2. str 类型:
3. slice:
4. String 类型:
struct
tuple
元组的内存布局:
closure
union
#[repr(C)] 和 union 的声明:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。