本文介绍: Apache Sqoop 是在 Hadoop 生态体系和 RDBMS 体系之间传送数据的一种工具。Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现。在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。Hadoop 生态系统包括:HDFS、Hive、Hbase 等RDBMS 体系包括:MySQL、Oracle、DB2 等Sqoop 可以理解为:“SQL 到 Hadoop 和 Hadoop 到 SQL”。
1. Sqoop介绍
Apache Sqoop 是在 Hadoop 生态体系和 RDBMS 体系之间传送数据的一种工具。
Sqoop 工作机制是将导入或导出命令翻译成 mapreduce 程序来实现。在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。
Hadoop 生态系统包括:HDFS、Hive、Hbase 等
RDBMS 体系包括:MySQL、Oracle、DB2 等
Sqoop 可以理解为:“SQL 到 Hadoop 和 Hadoop 到 SQL”。
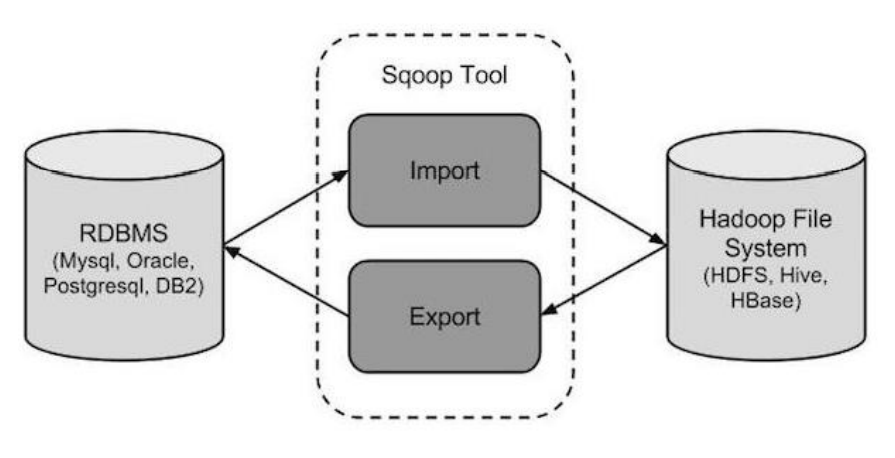
站在 Apache 立场看待数据流转问题,可以分为数据的导入导出:
Import:数据导入。RDBMS—–>Hadoop
Export:数据导出。Hadoop—->RDBMS
2. Sqoop导入——import
2.1 全量导入MySQL表数据到HDFS
从 MySQL 数据库服务器中的 userdb.emp 表导入到 HDFS。
bin/sqoop import
--connect jdbc:mysql://node-1:3306/userdb
--username root
--password 123456
--delete-target-dir
--target-dir /sqoopresult
--table emp
--m 1
–target–dir 用来指定导出数据存放至 HDFS 的目录;
–m 用来指定导入时使用几个map任务进行并行;
。。。。。。
。。。。。
。。。。
。。。
。。
。
更多用法请参考: Sqoop详细使用
原文地址:https://blog.csdn.net/CSDN1csdn1/article/details/134795227
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_42834.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。