本文介绍: 1/2也是为了求二次方的导数故意设计的,1/2或者2 只会改变函数形状的扁平还是高起,一般来说y=f(x) 值越大越高,值越小越扁平。如果f(x)=fθ(x1,x2,x3)=θ0*x0+θ1*x+θ2*x^2 =θ*X。如果f(x)=fθ(x1,x2,x3)=θ0+θ1*x+θ2*x^2 =θ*X。方法2 比如 f(x)=x^2+2x+1 导数 f(x)’=2x+2。比如 f(x)=x^2+2x+1这种往下凸出的,就是对应的最小值。x
1 AI ,ML,DL,NN 等等概念分类
1.1 人工智能、机器学习、深度学习、神经网络之间的关系:
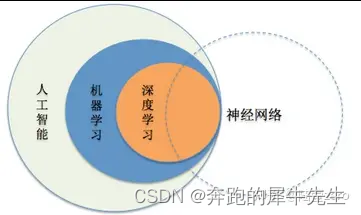
1.2 人工智能的发展
2 ML机器学习的分类:SL, USL,RL
2.1 机器学习的分类
2.2 具体的应用举例
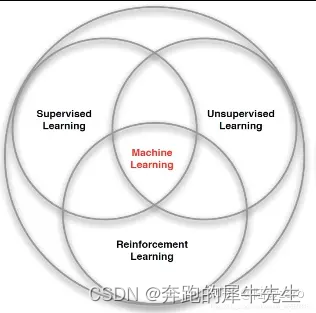
2.3 数据分类
3 关于阈值θ和偏移量b的由来
4 不同的激活函数
5 关于回归
6 关于分类
7 关于误差和梯度下降
8 最小二乘法修改θ
9 和矩阵计算,矩阵内积点乘的关系
10 深度学习
11 参考书籍
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






