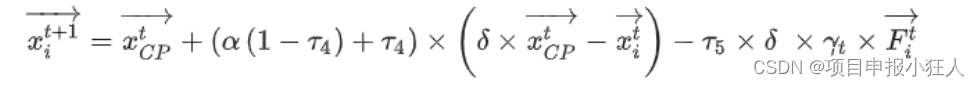本文介绍: 一、原理参数k的确定带权重的k近邻算法 与 模糊k近邻算法KNN算法用于回归问题在使用欧氏距离时应将特征向量归一化mahalanobis距离如何确定数据的协方差矩阵Bhattacharyya距离距离度量学习距离度量学习大边界最近邻分类二、示例代码1import numpy as np # 导入numpy库,用于进行数值计算import matplotlib.pyplot as plt # 导…









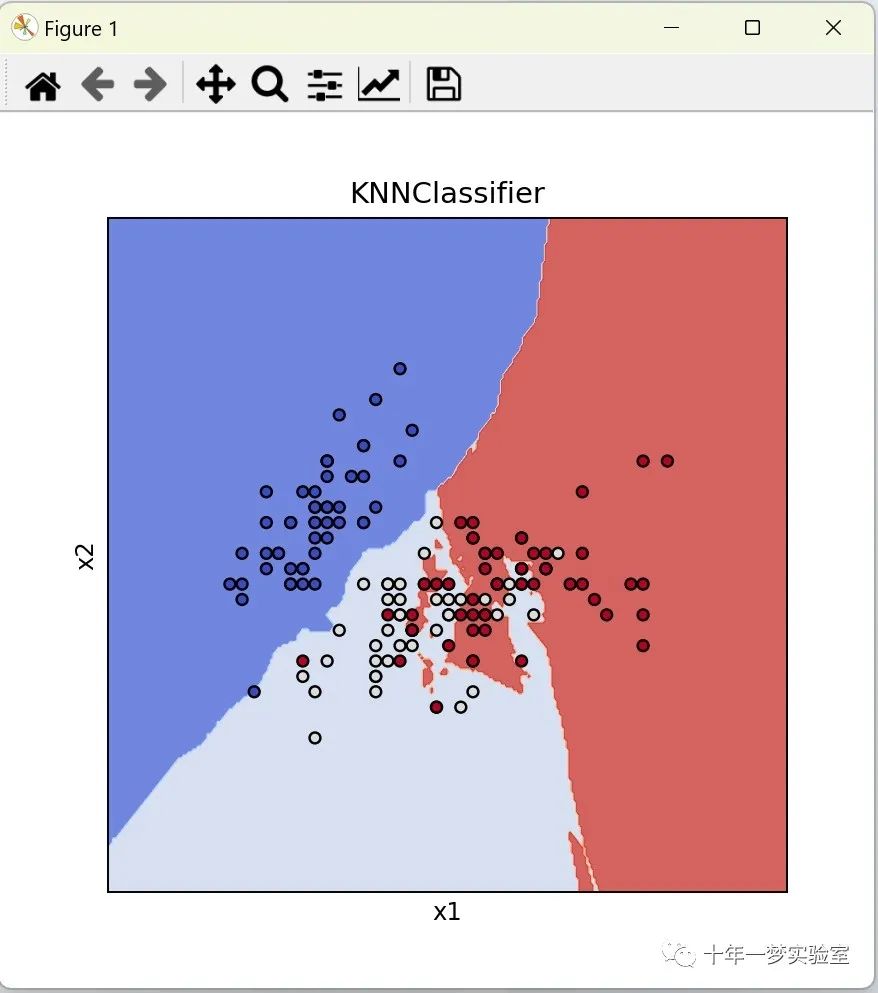
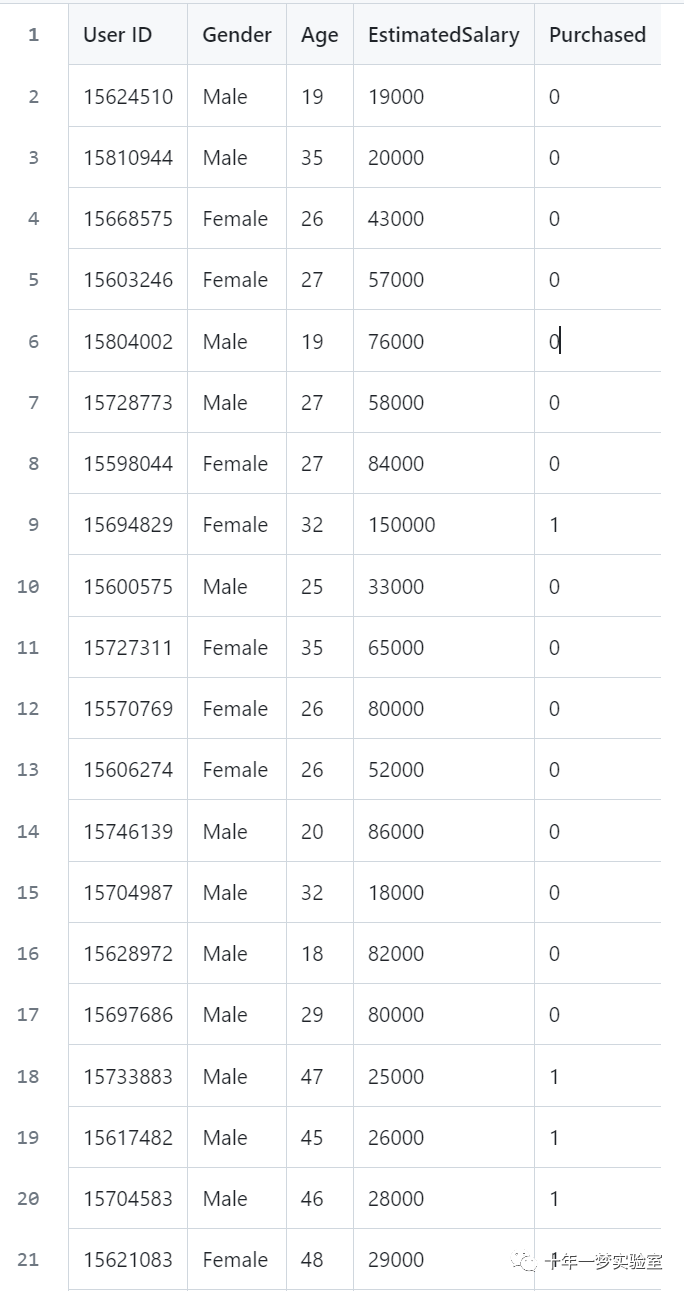


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。