本文介绍: Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(PatternSpace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。
一、sed简介(行编辑器)

二、基本用法


三、sed脚本格式(匹配地址 脚本命令)
1、不给地址,那么就是针对全文处理

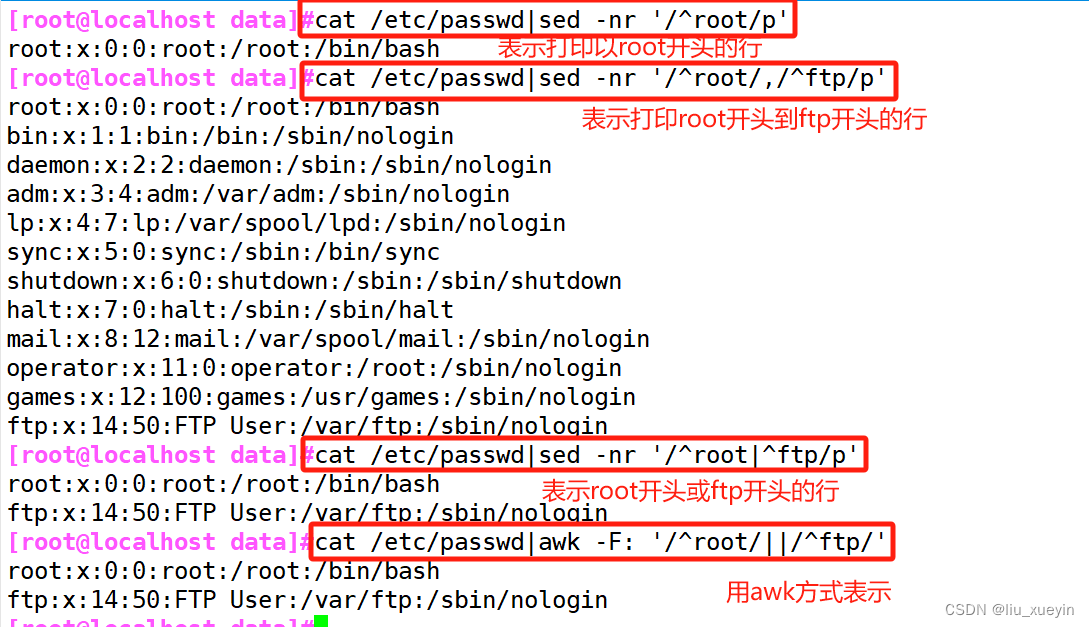
2、单地址,表示#,指定的行,$表示最后一行,/pattter/:表示该模式能匹配到的每一行,正则表达式
3、地址范围:
#,# 从第几行到第几行
#,+#从第几行开始,往后加4行
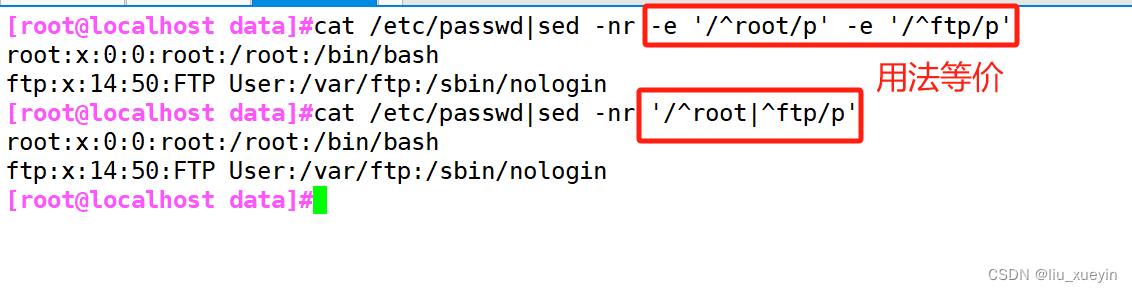
/patter1/,/patter2/ 表示从第一个开始找,到第二个结束


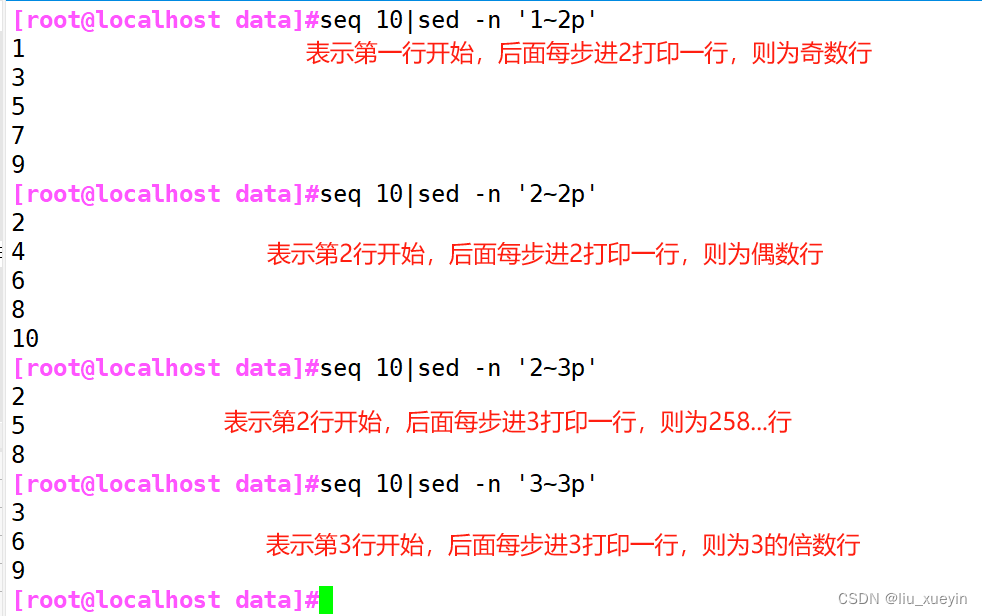
4、步进:~
1~2:表示奇数行
2~2:表示偶数行
3~3:表示可以3的倍数行
5、高级空间用法
sed -n ‘n;p’ 表示打印偶数行,表示从第一行开始,先放入高级空间,下一行打印,反复以往,表示打印偶数行
sed -n ‘2,${n;p}’ 表示奇数行,表示从第二行开始,先放入高级空间,下一行打印,反复以往,表示打印奇数行






四、搜索替代


五、分组后项引用
面试题一:可以自定义输出匹配内容的顺序
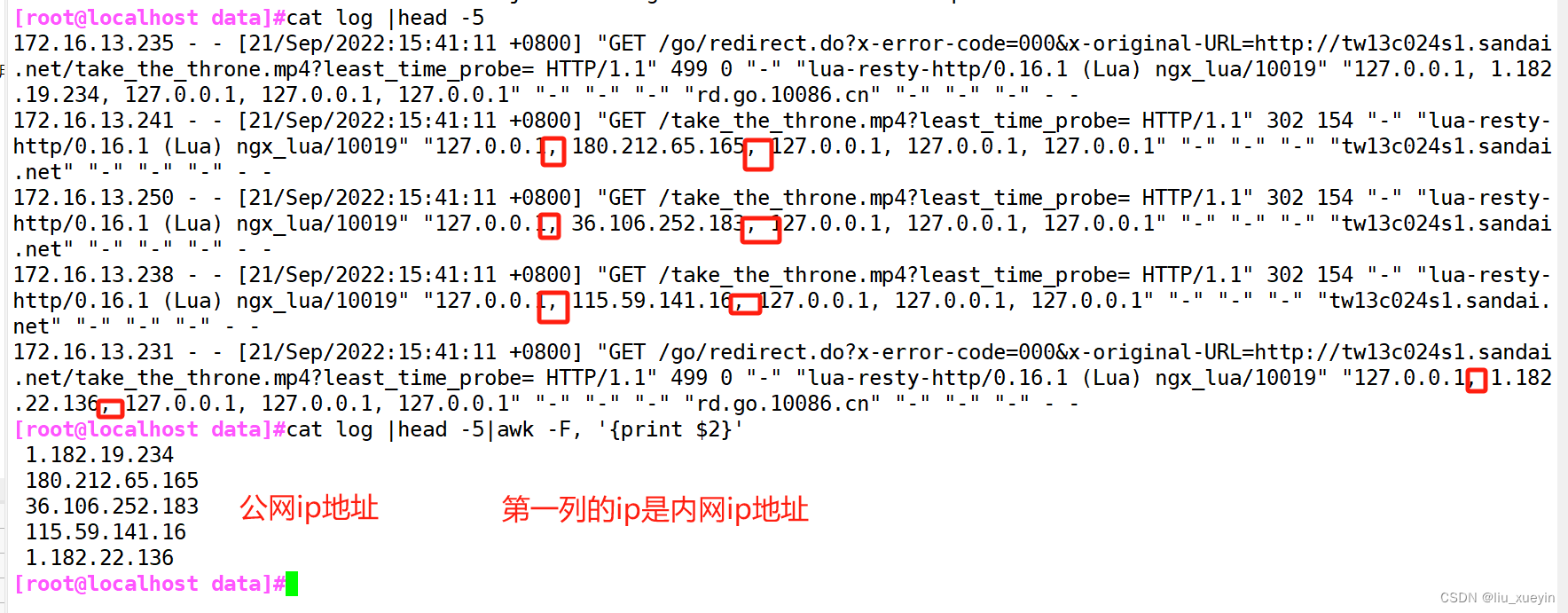
面试题二:使用sed的分组后项引用来提取ip地址
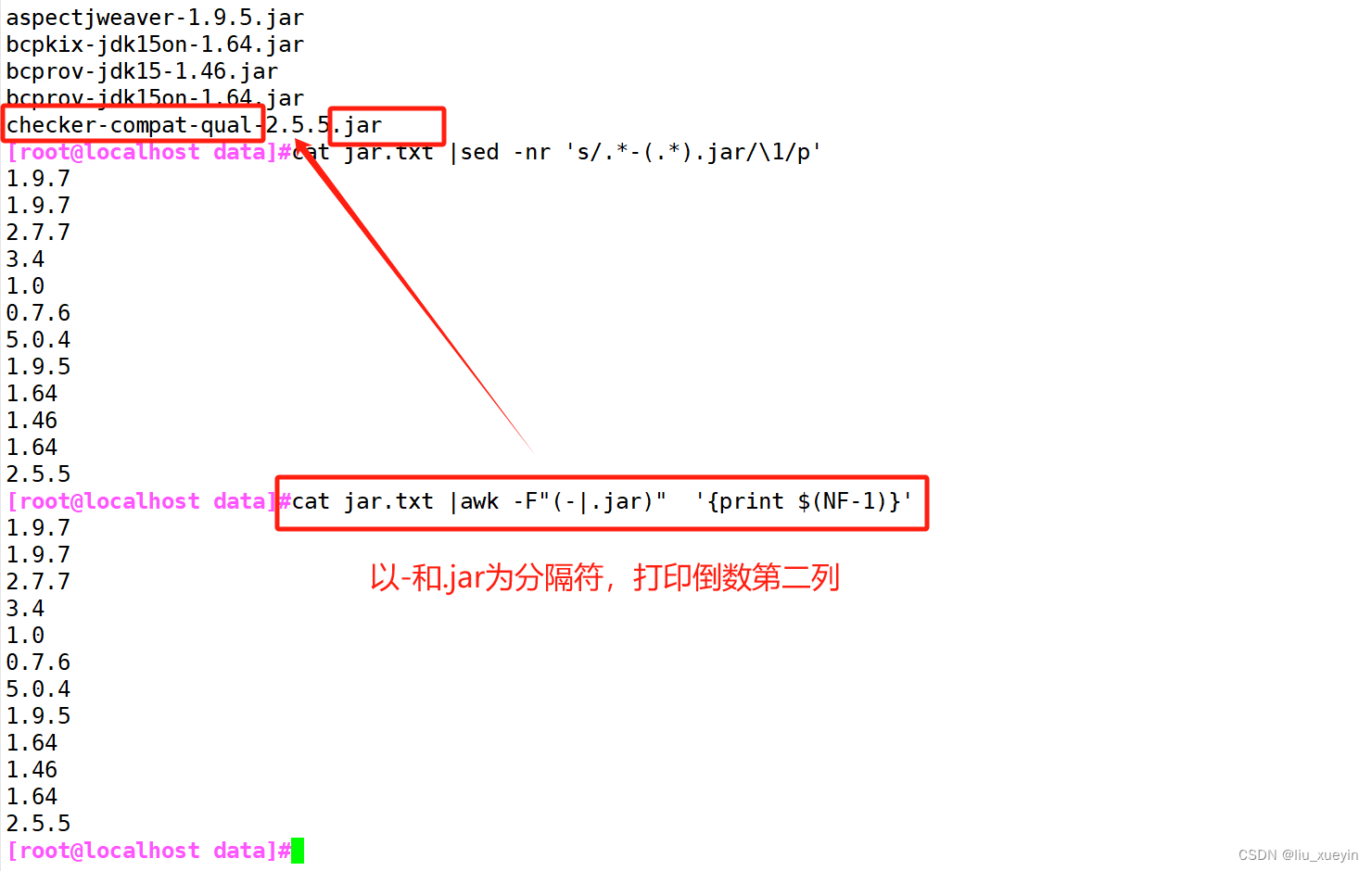
面试题三:提取版本号
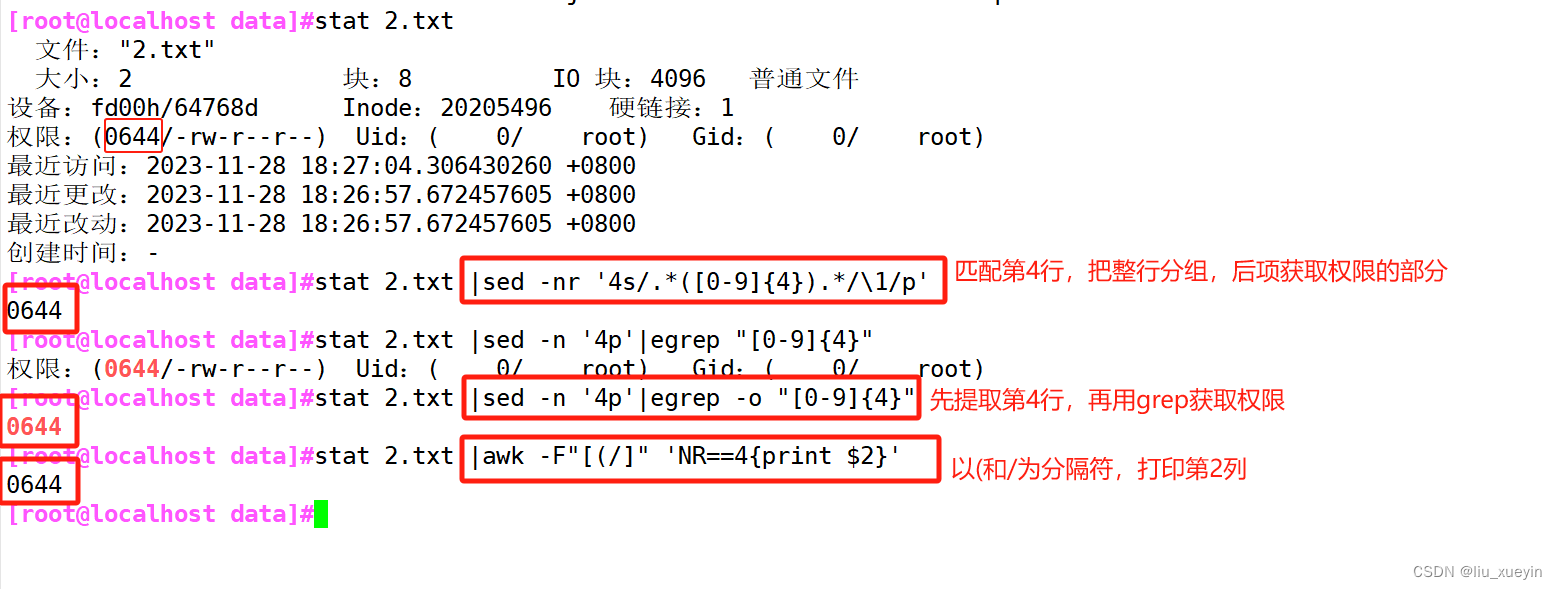
面试题四:提取文件的权限
面试题五:提取访问日志中的状态码
面试题六、提取日志的状态码
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。