本文介绍: 本文研究 zero–shot 指代图像分割,旨在没有训练标注的情况下,识别出与指代表达式最相关的目标。之前的方法利用预训练的模型,例如 CLIP,来对齐实例级别的 masks。然而 CLIP 仅考虑了图文对间的全局水平上的对齐,忽视了细粒度的匹配。于是本文引入 Text Augmented Spatial-aware (TAS) zero–shot 指代图像分割框架,无须训练且对任意的视觉编码器鲁棒。
写在前面
好久没看到有做 Zero-shot RIS 的文章了,看到 arxiv 上面更新了这篇,特意拿出来学习一下。
一、Abstract
本文研究 zero–shot 指代图像分割,旨在没有训练标注的情况下,识别出与指代表达式最相关的目标。之前的方法利用预训练的模型,例如 CLIP,来对齐实例级别的 masks。然而 CLIP 仅考虑了图文对间的全局水平上的对齐,忽视了细粒度的匹配。于是本文引入 Text Augmented Spatial-aware (TAS) zero–shot 指代图像分割框架,无须训练且对任意的视觉编码器鲁棒。TAS 整合了一个 mask proposal 网络用于实例级别的 mask 提取,一个文本增强的视觉–文本匹配得分用于挖掘图文间的关联,一个空间校正器用于 mask 后处理。除了常规的视觉–文本匹配得分外,增强文本的匹配得分包含了 P-score 和 N-score。P-score 通过一个字幕模型弥补视觉–文本鸿沟;N-score 通过负短语挖掘,实现区域–文本对的细粒度对齐。大量实验表明方法的效果很好。

二、引言
首先介绍下 referring expression segmentation 指代表达分割的定义,应用,手工标注的不易。于是本文研究 zero–shot 指代图像分割来减少成本。接下来是一些方法的介绍,主要是指出直接应用 CLIP 效果不太好。
三、相关工作
3.1 Zero-shot 分割
3.2 Referring Image Segmentation
3.3 Image Captioning
四、方法
4.1 总体框架
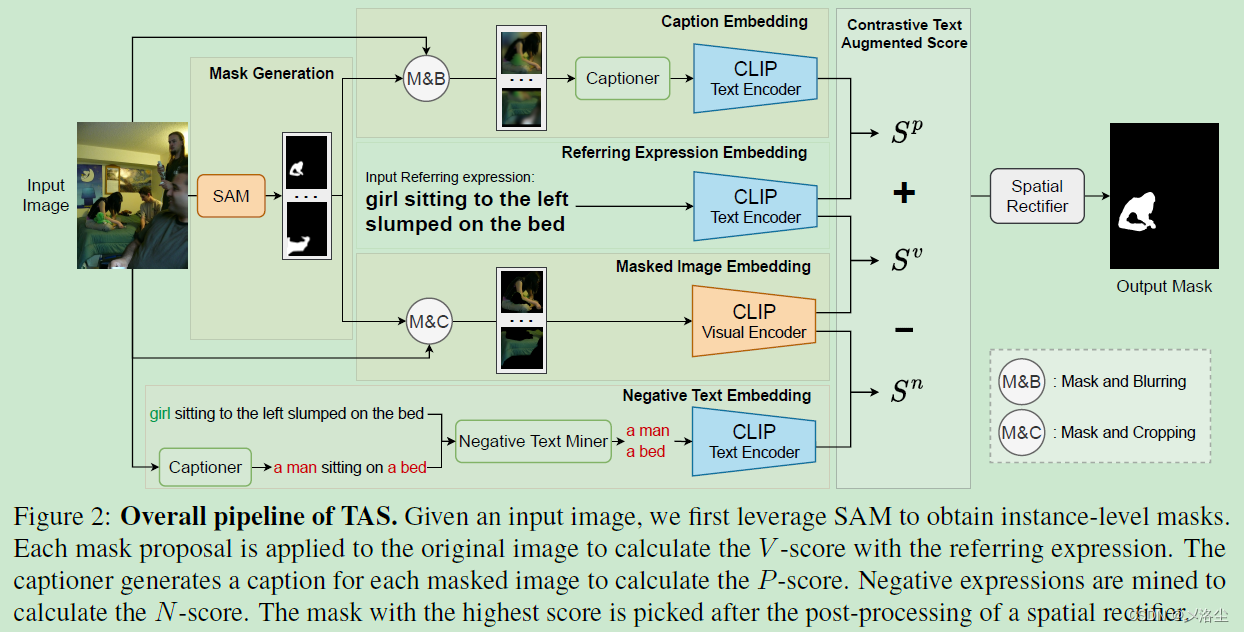
4.2 Mask Proposal 网络
FreeSOLO vs. SAM

4.3 文本增强的视觉-文本匹配得分
V-score
P-score
N-score
The text-augmented visual–text matching score
4.4 空间校正器
方向描述鉴定
位置计算
空间校正
五、实验
5.1 数据集和指标
5.2 实施细节
5.3 Baseline
5.4 结果
不同数据集的性能


定性分析

5.5 消融实验
超参数
α
alpha
α 和
β
beta
β 的敏感性

提出模块的重要性

masked images 输入格式的影响

image captioning 模型的重要性

TAS 能够泛化到其它的图像-文本对比模型吗?

TAS 能够应用于实际场景吗?
六、结论
七、限制
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)