一、Redis的入门介绍
1、入门概述
1、定义
Redis:REmote DIctionary Server(远程字典服务器),是完全开源免费的,用C语言编写的,遵守BSD协议,是一个高性能的(key–value)分布式内存数据库,基于内存运行并支持持久化的NoSql数据库,是当前最热门的NoSQL数据库之一,也被人们称之为数据库结构服务器。
- Redis支持数据化的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key–value类型的数据,同时还提供list,set,zset,hash等数据结构的储存
- Redis支持数据的备份,即master–slave模式的数据备份
2、能干嘛
- 内存存储和持久化:redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务,取最新N个数据的操作,如:可以将最近的10条评论的ID放在Redis的List集合里面模拟类似于HttpSession这种需要设定过期时间的功能。
- 定时、订阅消息系统
- 定时器、计数器
3、去哪下
4、怎么玩
持久化和复制、RDB/AOF
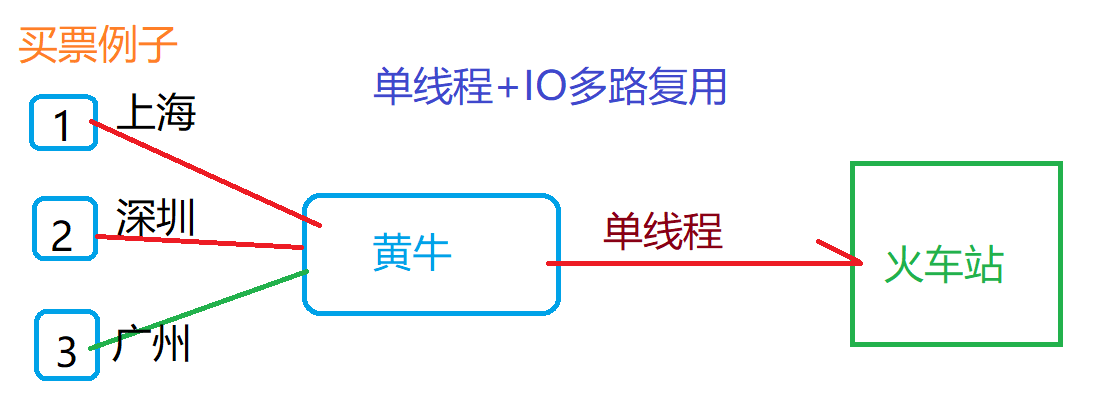
(与Memcache三点不同: 支持多数据类型,支持持久化,单线程+多路IO复用)
2、Redis的安装
tar -zxvf redis-6.2.7.tar.gz
cd redis-6.2.7
修改配置文件redis.conf
daemonize no修改成daemonize yes //这是开启后端运行
设置连接端口
redis-cli -h 127.0.0.1 -p 6379
禁用bind 127.0.0.1或者将bind 127.0.0.1改为0.0.0.0
将protected-mode yes 改为 protected-mode no
cd /usr/local/bin
ps -ef|grep redis
redis-server /opt/redis-6.2.7/redis.conf
redis-cli shutdown
3、Redis启动后杂项基础知识讲解
- 单进程:单进程模型来处理客户端的请求,对读写等时间的响应是通过对epoll函数的包装来做到的。Redis的实际处理速度完全依靠主进程的执行效率。Epoll是Linux内核为处理大批量文件描述而作了改进的epoll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU的利用率。
- 默认16个数据库,类似数组下标从零开始,初始默认使用零号库。
- Select命令切换数据库
- DBsize查看当前数据库的key的数量
- Flushdb:清空当前库
- Flushall:通杀全部库
- 统一密码管理:16个库都是同样的密码;要么都OK要么一个也连不上
- Redis索引都是从零开始
- 为什么默认端口是6379
二、Redis数据类型
1、Redis五大数据类型介绍
-
String(字符串):是Redis最基本的数据类型,一个key对应一个value,一个redis中字符串value最多可是512M。String类型是二进制安全的,意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小 于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。
-
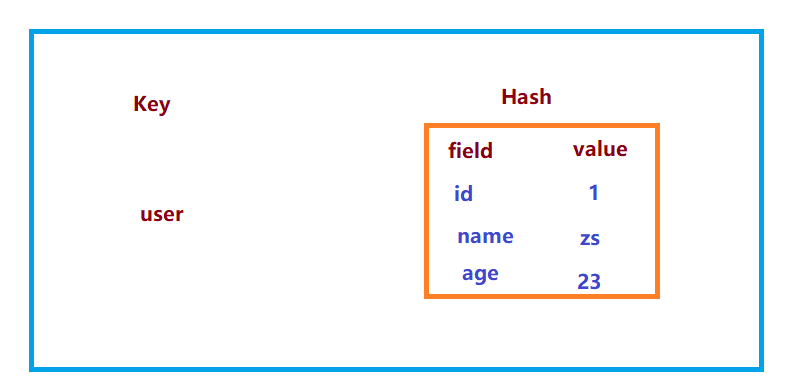
Hash(哈希,类似Java里的Map):是一个键值对集合,是一个string类型的field和value的映射表,hash特别适合用于存储对象。类似于Java中的Map<String,Object>。通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
-
List(列表):Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。他的底层实际是个双向链表
-
Set(集合):Redis的Set是string类型的无序集合。他是通过HashTable实现的。与List相似,但特殊之处在可以自动排重。当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
-
Zset(sorted set 有序集合):Redis的Zset和set一样也是string类型元素的集合,且不允许有重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。Zset的成员是唯一的,但分数(score)却可以重复。
-
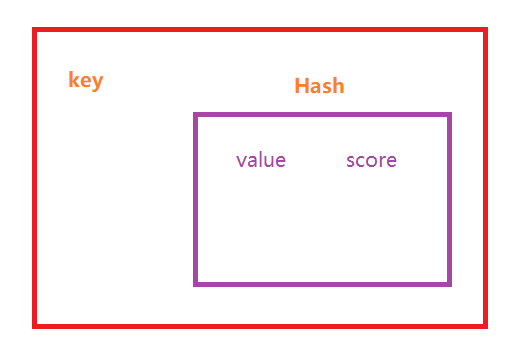
底层数据据结构:
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。

要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
(2) 跳跃表
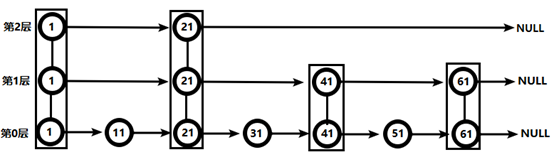
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下
-

2、哪里去获得redis常见数据类型操作命令
3、Redis 键(key)
常用命令:
- keys *
- exists key的名字 判断某个key是否存在
- move key db 当前库就没有了,被移除了
- expire key 秒钟 为给定的key设置过期时间
- ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
- type key 查看你的key是什么类型
4、Redis字符串(String)
常用命令:
- set/get/del/append/strlen
- Incr/decr/Incrby/decrby,一定要是数字才能进行加减(原子性操作)
- getrange/setrange
- setex(set with expire)键秒值/setnx(set if not exist)
- mset/mget/msetnx
- getset(先get再set)
5、Redis列表(List)【单键多value】
-
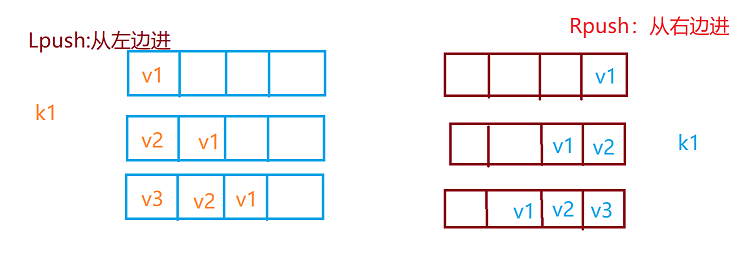
-
llen
性能总结:
他是一个字符串链表,left、right都可以插入添加;果键不存在,创建新的链 表;如果键已存在,新增内容;如果值全部移除,对应的键也就消失了。
链表的操作无论是头还是尾效率都极高,但假如对中间元素操作,效率就很惨淡了。
6、Redis集合(Set)【单键多value】
- ```markdown
scard <key> 获取集合里面元素的个数
-
srem <key> <value> 删除集合中某个元素 -
srandmember <key> <N> 随机从该集合中取出N个值,但不会删除 -
spop <key> 从该集合key中随机出栈一个元素 -
smove <key1> <key2> key1中某个值 作用是将key1里的某个值移到key2 -
数学集合类: 差集:sdiff <key1> <key2> 返回两个集合的差集元素(key1中有key2中没有) 交集:sinter <key1> <key2> 返回两个集合的交际元素 并集:sunion <key1> <key2> 返回两个集合的并集元素
7、Redis哈希(Hash)【KV模式不变,但V是一个键值对】
hmset … 批量设置hash的值
hmget
hgetall
hedl
- ```shell
hlen
-
hexists <key><field> 查看Hash表key中给定域field是否存在 -
hincrby <key><field><increment> 为Hash表key中的域field的值加上增量increment hincrbyfloat
- ```markdown
hsetnx <key><field><value> 将Hash表中key中的域field的值设置为value,当且仅当域field不存在
8、Redis有序集合Zset(sorted set)
在set基础上,加一个score值。之前set是k1 v1 v2 v3,现在zset是k1 score1 v1 score2 v2
-
zadd <key><score1><value1><score2><value>... 将一个或多个member元素及其score值加入到有序 集key当中 zrange <key><start><stop> [withScore] 返回有序集key中,下标在<start><stop>之间的元素 -
zrangebyscore <key><开始score><结束score> 按从小到大返回key介于 开始score<=score<=结束score的成员 zrevrangebyscore <key><结束score><开始score> 同上,顺序是从大到校 -
zrem <key> 某score下对应的value值,作用是删除元素 -
zcard/zcount <key><score区间> 统计该集合分数区间内的元素个数 zrank <key><values值> 作用是获得下标值,从0开始 zscore <key> 对应值,获得分 -
zrevrank <key><values>值,作用是逆序获得下标值 -
zrevrange -
zincrby <key><increment><value> 为元素的score加上增量increment
三、解析配置文件redis.conf
1、他在哪
2、#########Units单位#########
配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit
3、########INCLUDE包含#######
4、####网络相关配置####
-
bind
5、######GENERAL#######:
-
databases 16
6、########SNAPSHOTTING快照########
save 秒钟 写操作的次数
RDB是整个内存的压缩过的Snapshot,RDB的数据结构,可以配置复合的快照触发条件
默认:
是一分钟内改了1万次
或5分钟内改了10万次
或15分钟内改了1次
禁用:如果想禁用RDB持久化的策略,只要不设置任何save指令,或者给save传入一个空字符串参数也可以
Stop-writes-on-bgsave-error
默认值为yes,如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制
rdbcompression
rdbcompression:对于存rdb储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。【推荐压缩】
rdbchecksum
默认为yes;在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。【推荐yes】
7、PEPLICATION复制
8、############SECURITY安全33############
在命令中设置密码,只是临时的。重启redis服务器,密码就还原了。
永久设置,需要再配置文件中进行设置。
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) ""
设置密码验证
127.0.0.1:6379> config set requirepass "123456"
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> config set requirepass ""
OK
9、######LIMITS限制########
-
Maxclients: 设置redis同时可以与多少个客户端进行连接,默认情况下为10000个客户端。如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应。 -
Maxmemory: 建议必须设置,否则,将内存占满,造成服务器宕机 设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。 如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。 但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明你的redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。 -
Maxmemory-policy:缓存过期清洁策略 - volatile:使用LRU算法移除key,只对设置了过期时间的键 - allkeys-lru:使用LRU算法移除key - volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键 - allkeys-random:移除随机的key - volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key - noeviction:不进行移除。针对写操作,知识返回错误信息 -
Maxmemory-samples:设置样本数量,LRU算法和最小TTL算法都并非是精确地算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个。一般设置3到7的数字,数值越小样本越不准确,但性能消耗越小。
10、#######APPEND ONLY MODE追加######
-
appendonly no (默认是no,yes就打开aof持久化) -
appendfilename appendonly.aof -
appendfsync: Always:同步持久化 每次发生数据变更会被礼记记录到磁盘 性能较差但数据完整性比较好 Everysec:出厂默认推荐,异步操作,每秒记录 如果一秒内宕机,有数据丢失 No -
No-appendfsync-on-rewrite:重写时是否可以运用Appendfsync,用默认no即可,保证数据安全性。 -
Auto-aof-rewrite-min-size:设置重写的基准值 -
Auto-aof-rewrite-percentage:设置重写的基准值
11、常见配置redis.conf介绍
1.Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
deanonize no
2.当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定。
pidfile /var/run/redis.pid
3.指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中揭示了为什么选用6379作为默认端口,因为6379在手机上按键上MERZ对应的号码,而NERZ取自意大利女Alessia Merz的名字
port 6379
4.绑定的主机地址
bind 127.0.0.1
5.当前客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
6.指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
7.日志记录方式,默认为表准输出,如果配置Redis为守护进程方式运行,而这里有配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
8.设置数据库的数量,默认数据库为0,可以使用SELECT<dbid>命令在连接上指定数据库id
database 16
9.指定在多长时间内,有多少次更新操作,将数据同步到数据文件,可以多个条件配合
save<seconds><changes>
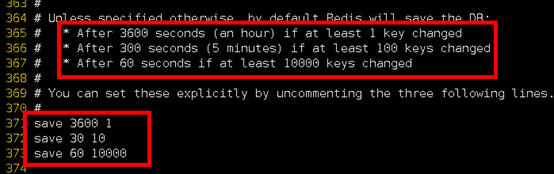
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
注:每当FLUSHALL或者SHUTDOWN时,dump.rdb都会被清空,所以在SHUTDOWN前备份一下 dump.rdb文件到别的电脑。如果没到规定时间也想保存,可以使用save命令。
10.指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据文件变的巨大
rdbcompression yes
11.指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
12.指定本地数据库存放目录
dir ./
13.设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,他会自动从master进行数据同步
slaveof <masterip> <masterport>
14.当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
15.设置Redis连接密码,如果配置了连接密码,客户端在连接Redis是需要通过AUTH<password>命令提供密码,默认关闭
requirepass foobared
16.设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置maxclients 0,表示不作限制。当客户端连接数到大限制时,Redis会关闭新的连接并向客户端返回max number of client reached错误信息
maxclients 128
17.指定Redis最大内存限制,Redis在启动时会把数据加载到内存文件中,达到最大内存后,Redis会显尝试清除已到期或即将到期的Key,当此方法处理后,仍然到大最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
18.指定是否在每次更新操作进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为redis本身同步数据文件是按上面的save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
19.指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
20.指定更新日志文件,共有3个可选值
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(这种是默认值)
appendfsync everysec
21. 指定是否用虚拟内存机制,默认值为no,简单介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页面即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中
vm-enable no
22.虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
23.将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据,就是keys)也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
24.Redis.swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大对象,则可以使用更大的page,如果不确定,就是用默认值
vm-page-size 32
25.设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是存放在内存中的,在磁盘上每8个pages将消耗1byte的内存。
vm-page 134217728
26.设置访问swap文件的线程数最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
27.设置在向客户端应答时,是否把较小的包合并为一个包发送,默认开启
glueoutputbuf yes
28.指定在超过一定数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
29.指定是否激活重置哈希,默认为开启
activerehashing yes
30.指定包含其他的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例有拥有自己的特定配置文件
include /path/to/local.conf
四、Redis的持久化
1、RDB(Redis DataBase)
1、是什么:
在指定的时间间隔内将内存中的数据集快照写入磁盘,,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
2、备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
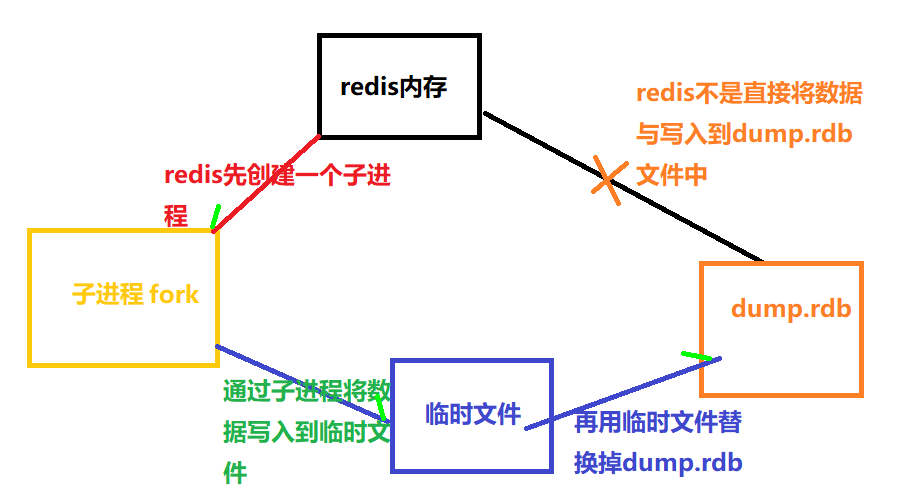
3、Fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
4、dump.rdb
RDB保存的是dump.rdb文件,文件名默认为dump.rdb

5、配置文件位置
6、如何触发RDB快照
-
配置文件中默认的快照配置
-


对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。
如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能。推荐yes.

7、如何恢复RDB快照
8、优势&劣势
- 优势:适合大规模的数据恢复;对数据完整性和一致性要求不高;节省磁盘空间;恢复速度快;
- 劣势:在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后所有的修改;Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
9、如何停止
动态所有停止RDB保存规则的方法:redis-cli config set save “ ”
10、总结:
- RDB是一个非常紧凑的文件
- RDB在保存RDB文件时父进程唯一要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些
- 数据丢失风险大
- RDB需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级不能响应客户端请求
2、AOF(Append Only FIle)
1、是什么:
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取改文件重新构建数据,换言之,redis重启的话就跟据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
2、AOF保存的是appendonly.aof文件
3、配置位置
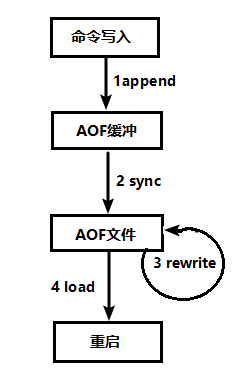
4、AOF持久化流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;
(2)AOF缓冲区根据AOF持久化策略[always、everysec、no]将操作sync同步到磁盘的AOF文件中;
(3)AOF文件大小超过重写策略或手动重写时,会对AOF文件进行rewrite重写,压缩AOF文件容量
(4)Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的;
5、AOF和RDB同时开启,redis听谁的?
AOF和RDB同时开启,系统默认读取AOF的数据(数据不会存在丢失)
6、AOF启动/修复/恢复
- 正常恢复:
- 异常恢复:
7、AOF同步频率设置
appendfsync always
始终同步,每次Redis的写入都会立刻计入日志;性能较差但数据完整性比较好
appendfsync everysec(默认)
每秒同步,每秒计入日志一次,如果宕机,本秒的数据可能丢失
appendfsync no
redis不主动进行同步,把同步时机交给操作系统。
8、Rewrite压缩
-
是什么:
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof
-
重写原则:
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
如果 no-appendfsync-on-rewrite=yes ,不写入aof文件只写入缓存,用户请求不会阻塞,但是在这段时间如果宕机会丢失这段时间的缓存数据。(降低数据安全性,提高性能)
如果 no-appendfsync-on-rewrite=no, 还是会把数据往磁盘里刷,但是遇到重写操作,可能会发生阻塞。(数据安全,但是性能降低)
-
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。
auto-aof-rewrite–percentage:设置重写的基准值,文件达到100%时开始重写(文件是原来重写后文件的2倍时触发)
auto-aof-rewrite–min–size:设置重写的基准值,最小文件64MB。达到这个值开始重写。
例如:文件达到70MB开始重写,降到50MB,下次什么时候开始重写?100MB
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,
如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
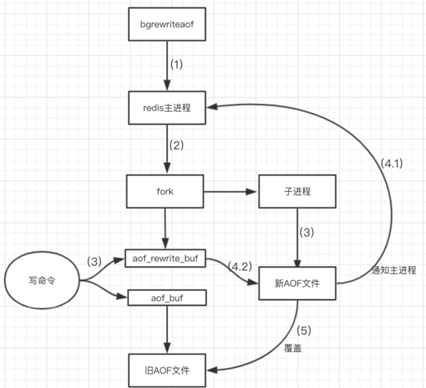
9、重写流程
(1)bgrewriteaof触发重写,判断是否当前有bgsave或bgrewriteaof在运行,如果有,则等待该命令结束后再继续执行。
(2)主进程fork出子进程执行重写操作,保证主进程不会阻塞。
(3)子进程遍历redis内存中数据到临时文件,客户端的写请求同时写入aof_buf缓冲区和aof_rewrite_buf重写缓冲区保证原AOF文件完整以及新AOF文件生成期间的新的数据修改动作不会丢失。
(4)1).子进程写完新的AOF文件后,向主进程发信号,父进程更新统计信息。2).主进程把aof_rewrite_buf中的数据写入到新的AOF文件。
(5)使用新的AOF文件覆盖旧的AOF文件,完成AOF重写。
10、优势/劣势
-
优势

-
劣势
7、总结:
- AOF文件是一个只进行追加的日志文件
- Redis可以在AOF文件体积变得过大时,自动的在后台对AOF进行重写
- AOF文件有序的保存了对数据库执行的所有写入操作,这些写入操作以Redis协议的格式保存,因此AOF文件的内容非常容易被人读懂,对文件进行分析也很轻松
- 对于相同的数据来说,AOF文件的体积通常要大于RDB文件的体积
- 根据所使用的的fsync策略,AOF的速度可能会慢于RDB
Redis默认先加载appendonly.aop文件,如果appendonly.aop文件报错了,则去加载dump.rdb文件;如果appendonly.aof没有报错就加载appendonly.aof文件
11、Which One
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储。
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候回重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
如果对数据不敏感,可以选单独用RDB。
只做缓存:如果你只希望你的数据在服务器运行的时候存在,可以都不用。
- 在通常情况下,当redis重启的时候会优先加载AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只是用AOF呢?作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
性能建议:
- 因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1 这条规则
- 如果Enable AOF ,好处是在最恶劣情况下也只会丢失不超过两秒的数据,启动脚本简单只load自己的AOF文件就可以了,代价一是带来了持续的IO,而是AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大小100%大小时重写可以改到适当的数值。
- 如果不Enable AOF,仅靠Master-Slave Replication 实现高可用性也可以。能生一大笔IO也减少了rewrite时带来的系统波动。代价是如果Master/Slave同时倒掉,会丢失十几分钟的数据启动脚本也要比较两个Master/Slave中的RDB文件,载入较新的那个。比如新浪微博就选用这种架构。
五、Redis的事务
1、定义:
Redis事务可以一次执行多个命令,本质是一组命令的集合。
两个重要保证:
一个事物从开始到执行会经历三个阶段:开始事务—>命令入队—>执行事务
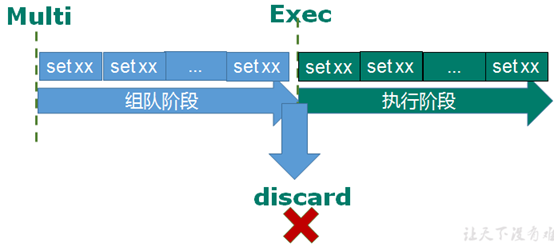
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。
2、Redis事务命令:
| 命令 | 描述 |
|---|---|
| DISCARD | 取消事务,放弃执行事务快内的所有命令。 |
| EXEC | 执行所有事务快内的命令。 |
| MULTI | 标记一个事务块的开始。 |
| UNWATCH | 取消WATCH命令对所有key的监事。 |
| WATCH key [key…] | 监视一个(或多个)key,如果在事务执行前这个(或这些)key被其他命令所改动,那么事务将会被打断。 |
补充:
WATCH 用于为 Redis 事务提供检查和设置 (CAS) 行为。 监视 WATCHed 键以检测针对它们的更改。如果在执行 EXEC 命令之前至少修改了一个监视键,则整个事务中止,并且 EXEC 返回 Null 回复以通知事务失败。
3、事务的错误处理
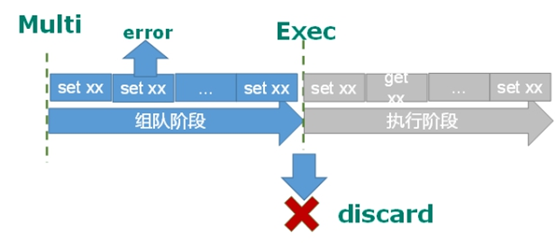
②:执行阶段某个命令出现错误,则仅报错的命令不被执行,其他命令全被执行,不会回滚。
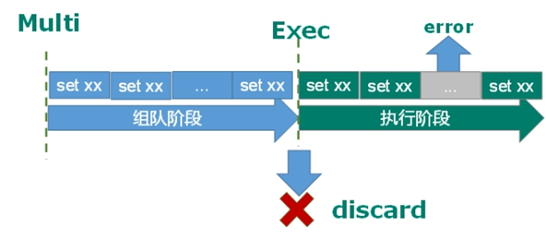
综上,exec前报错所有命令都不执行;exec后报错,仅报错的命令不被执行。
4、事务冲突的问题
例子:
一个请求想给金额减8000
一个请求想给金额减5000
一个请求想给金额减1000
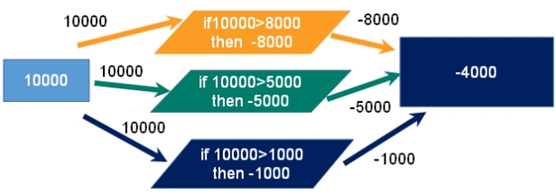
悲观锁:
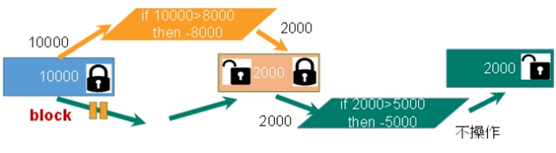
悲观锁,顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库就用到了很多这种锁机制,如:行锁、表锁、读锁、写锁等,都在在操作前先上锁。
乐观锁:
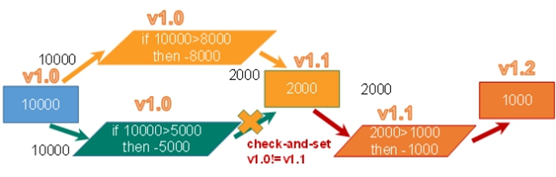
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check–and-set机制实现事务的。
5、Redis事务的三大特性
6、模拟秒杀案例
①代码:
<body>
<h1>iPhone 13 Pro !!! 一元抢购!!!</h1>
<form id="msform" action="SeckillController" method="POST">
<input type="hidden" name="prodid" value="0101">
<input type="button" id="ms_btn" value="点我秒杀">
</form>
</body>
<script type="text/javascript" src="js/jquery-3.1.1.js"></script>
<script type="text/javascript">
$(function() {
$("#ms_btn").click(function() {
var url = $("#msform").attr("action");
$.post(url,$("#msform").serialize(),function(data){
if(data == "false"){
alert("抢光了");
$("#ms_btn").attr("disable",true);
}
})
})
})
</script>
@WebServlet("/SeckillController")
public class SeckillController extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String userId = new Random().nextInt(50000) + "";
String prodid = request.getParameter("prodid");
boolean sk = Seckill_redis.doSeckill(userId, prodid);
response.getWriter().print(sk);;
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
public class Seckill_redis {
public static void main(String[] args) {
}
public static boolean doSeckill(String uid,String prodid) {
//1、uid和prodid非空判断
if(null == uid || null == prodid) {
return false;
}
//2、连接redis
Jedis jedis = new Jedis("192.168.2.138",6379);
//3、拼接key 1)库存key 2)秒杀成功用户key
String kcKey = "sk:"+prodid+":qt";
String userKey = "sk:"+prodid+":user";
//4、获取库存,如果库存为null,秒杀还未开始
String kc = jedis.get(kcKey);
if(null == kc) {
System.out.println("秒杀还未开始,请等待");
jedis.quit();
return false;
}
//5、判断用户是否重复秒杀操作
if(jedis.sismember(userKey, uid)) {
System.out.println("你已秒杀成功,不能重复秒杀");
jedis.quit();
return false;
}
//6、判断如果商品库存数量小于1,秒杀结束
int i = Integer.parseInt(kc);
if(i<=0) {
System.out.println("商品已被秒杀完");
jedis.quit();
return false;
}
; //7、秒杀过程 1)库存-1 2)把秒杀成功用户添加清单里面
jedis.decr(kcKey);
jedis.sadd(userKey, uid);
System.out.println("秒杀成功");
jedis.quit();
return true;
}
}
②模拟秒杀并发:
使用工具ab模拟测试,CentOS6 默认安装,CentOS7需要手动安装。
yum install httpd-tools
进入cd /run/media/root/CentOS 7 x86_64/Packages(路径跟centos6不同)
apr-1.4.8-3.el7.x86_64.rpm
apr-util-1.5.2-6.el7.x86_64.rpm
httpd-tools-2.4.6-67.el7.centos.x86_64.rpm
③通过ab工具测试:
创建文件postfile内容:prodid=0101&
ab -n 1000 -c 300 -k -p ~/postfile -T application/x-www–form–urlencoded http://192.168.2.2:8080/Seckill/SeckillController
④:连接超时问题
⑤:超卖问题
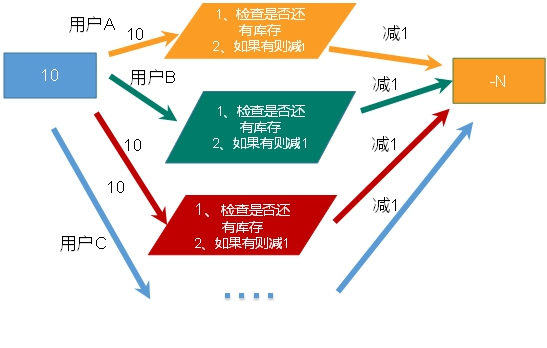
public static boolean doSeckill(String uid,String prodid) {
//1、uid和prodid非空判断
if(null == uid || null == prodid) {
return false;
}
//2、连接redis
JedisPool jedisPool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = jedisPool.getResource();
//3、拼接key 1)库存key 2)秒杀成功用户key
String kcKey = "sk:"+prodid+":qt";
String userKey = "sk:"+prodid+":user";
//监事事务
jedis.watch(kcKey);
//4、获取库存,如果库存为null,秒杀还未开始
String kc = jedis.get(kcKey);
if(null == kc) {
System.out.println("秒杀还未开始,请等待");
jedis.quit();
return false;
}
//5、判断用户是否重复秒杀操作
if(jedis.sismember(userKey, uid)) {
System.out.println("你已秒杀成功,不能重复秒杀");
jedis.quit();
return false;
}
//6、判断如果商品库存数量小于1,秒杀结束
int i = Integer.parseInt(kc);
if(i<=0) {
System.out.println("商品已被秒杀完");
jedis.quit();
return false;
}
//开启事务
Transaction multi = jedis.multi();
; //7、秒杀过程 1)库存-1 2)把秒杀成功用户添加清单里面
multi.decr(kcKey);
multi.sadd(userKey, uid);
//执行事务
List<Object> results = multi.exec();
if(results == null || results.size() == 0) {
System.out.println("秒杀失败");
jedis.quit();
return false;
}
System.out.println("秒杀成功");
jedis.quit();
return true;
}
⑥:库存遗留问题
由乐观锁造成。由于乐观锁的存在导致修改数据时版本号不一致。所以修改失败。
解决:
通过lua脚本淘汰用户解决争抢问题,实际上是redis 利用其单线程的特性,用任务队列的方式解决多任务并发问题
package com.atcpl.controller;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
import com.atcpl.utils.JedisPoolUtil;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
public class SecKill_redisByScript {
static String secKillScript ="local userid=KEYS[1];rn" +
"local prodid=KEYS[2];rn" +
"local qtkey='Seckill:'..prodid..":kc";rn" +
"local usersKey='Seckill:'..prodid..":user";rn" +
"local userExists=redis.call("sismember",usersKey,userid);rn" +
"if tonumber(userExists)==1 then rn" +
" return 2;rn" +
"endrn" +
"local num= redis.call("get" ,qtkey);rn" +
"if tonumber(num)<=0 then rn" +
" return 0;rn" +
"else rn" +
" redis.call("decr",qtkey);rn" +
" redis.call("sadd",usersKey,userid);rn" +
"endrn" +
"return 1" ;
public static boolean doSecKill(String uid,String prodid) throws IOException {
JedisPool jedisPool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = jedisPool.getResource();
String sha1= jedis.scriptLoad(secKillScript);
Object result= jedis.evalsha(sha1, 2, uid,prodid);
String reString=String.valueOf(result);
if ("0".equals( reString ) ) {
System.err.println("已抢空!!");
}else if("1".equals( reString ) ) {
System.out.println("抢购成功!!!!");
}else if("2".equals( reString ) ) {
System.err.println("该用户已抢过!!");
}else{
System.err.println("抢购异常!!");
}
jedis.close();
return true;
}
}
六、Redis的订阅与发布
1、定义:
Redis发布订阅(pub/sub)是一种消息通信模式:发布者(pub)发送消息,订阅者(sub)接收消息。
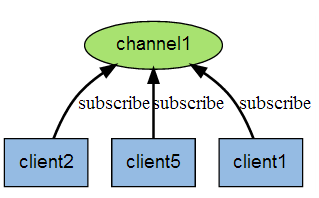
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
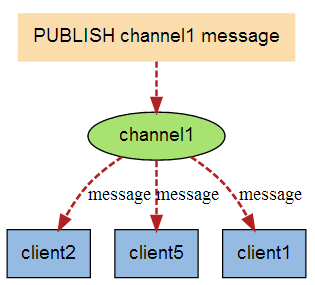
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
2、Redis发布订阅命令
| 命令 | 描述 |
|---|---|
| PSUBSCRIBE pattern [patter…] | 订阅一个或多个符合给定模式的频道 |
| PUBSUB subcommand [argument [argument…]] | 查看订阅与发布系统状态 |
| PUBLISH channel message | 将信息发送到指定的频道 |
| PUNSUBSCRIBE [pattern [pattern…]] | 退订所有给定模式的频道 |
| SUBSCRIBE channel [channel…] | 订阅给定的一个或多个频道的信息 |
| UNSUBSCRIBE [channel [channel…]] | 指退订给定的频道 |
3、案例
1、可以一次性订阅多个,SUBSCRIBE c1 c2 c3
2、消息发布,PUBLISH c2 hello-redis
4、收取消息,PUBLISH new1 redis2015
七、Redis的主从复制
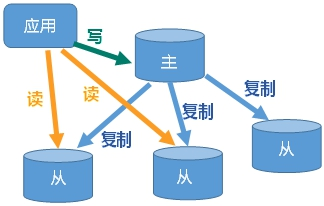
1、是什么
也是就我们所说的主从复制,主机数据跟新后根据配置和策略,自动同步到备机的master/slave机制,Master以写为主,Slave以读为主。
2、怎么玩
1、配从(库)不配主(主)
2、从库配置:
slaveof <主机IP> <主机端口>
info replication 查看主从复制相关信息
3、修改配置文件细节操作
拷贝多个redis.conf文件
开启deamonize yes
Pid文件名字
指定端口
Log文件名字
Dump.rdb名字

4、常用3招
-一主二从
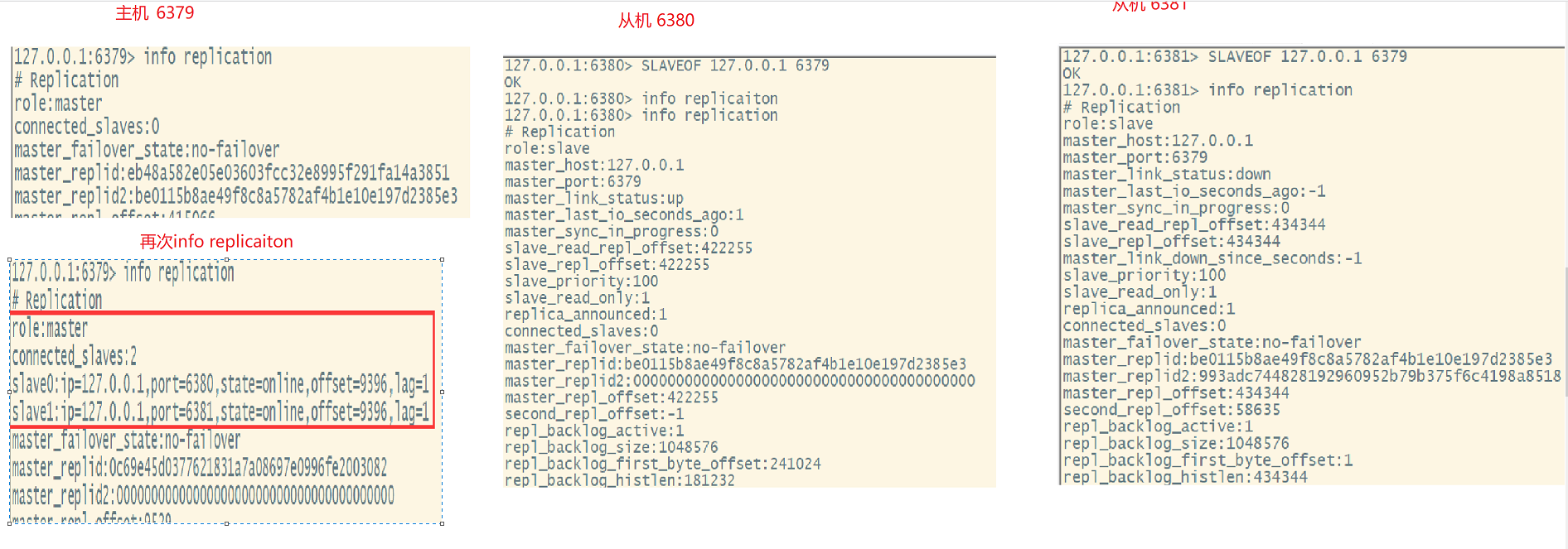
-薪火相传
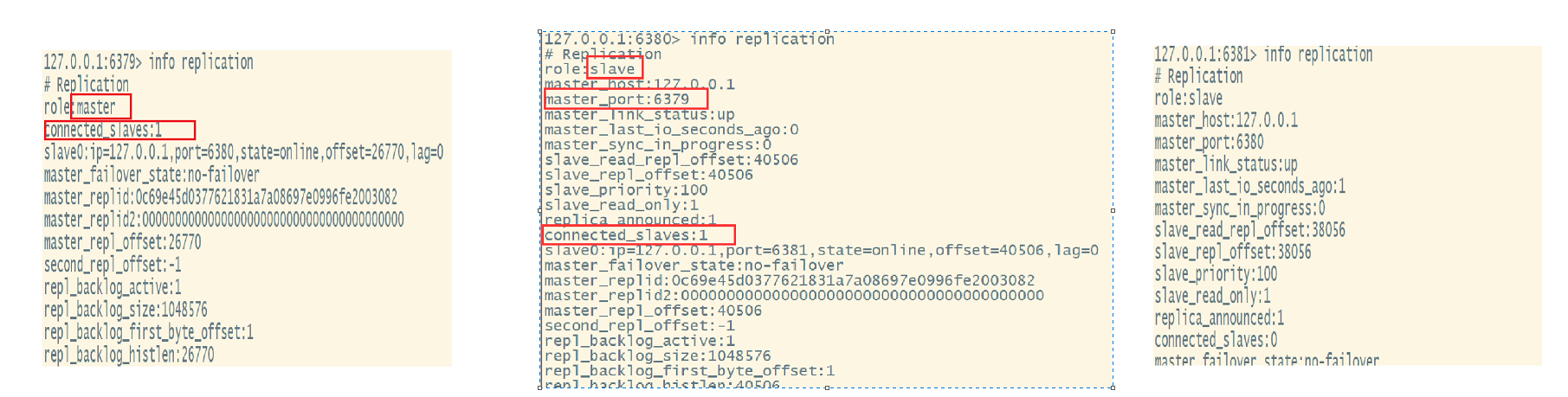
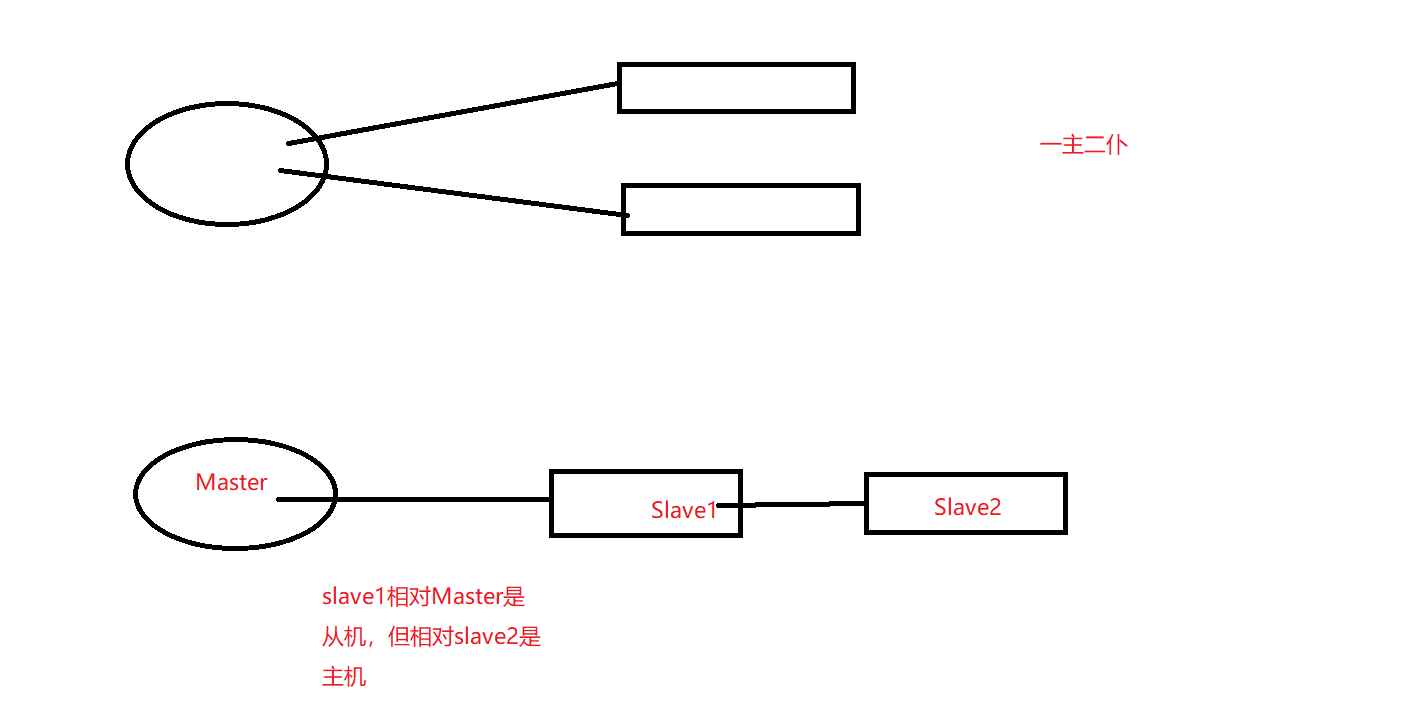
-反客为主
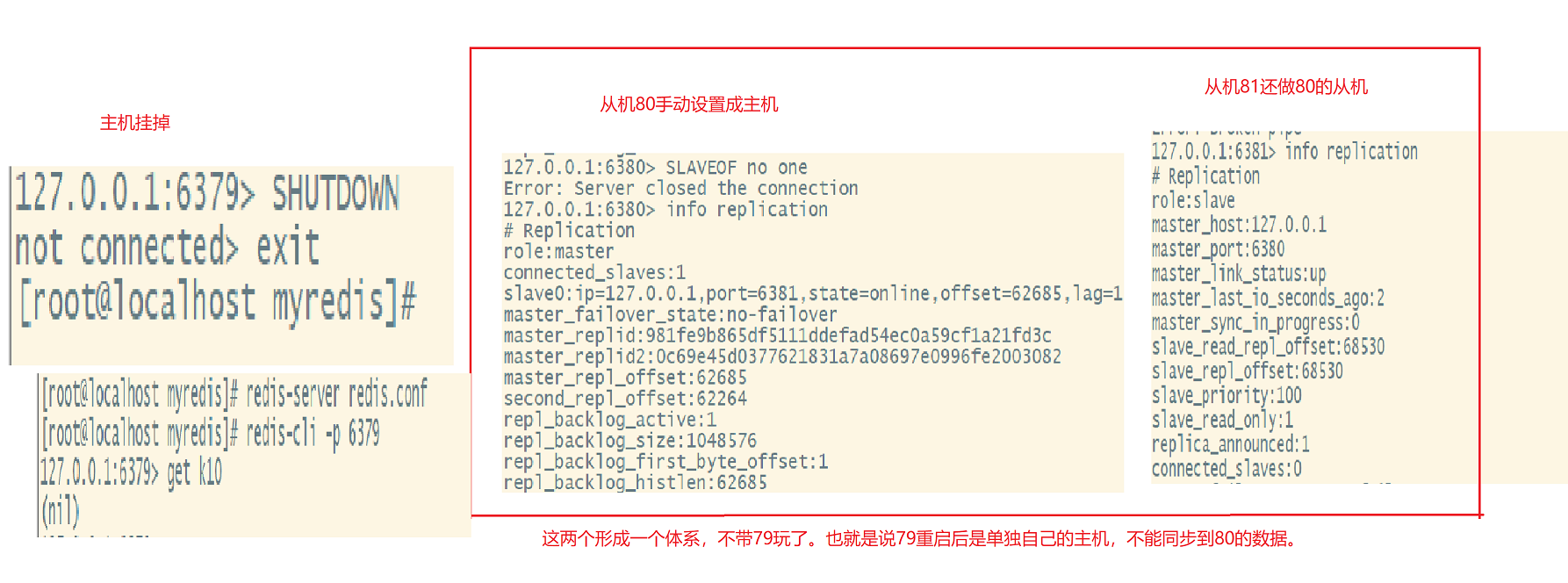
SLAVEOF no one 是当前数据库停止与其他数据库的同步,将从机变为主机
3、复制原理
Slave启动成功连接到Master后会发送一个sync(同步)命令,Master接收到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕后,master将传送整个数据文件到slave,以完成一次完全同步。
但是只要是重新连接Master,一次完全同步(全量复制)将被自动执行。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HH0WhhpJ-1687078790855)(C:Users蜡笔小新AppDataRoamingTyporatypora-user-imagesimage-20220727220215088.png)]
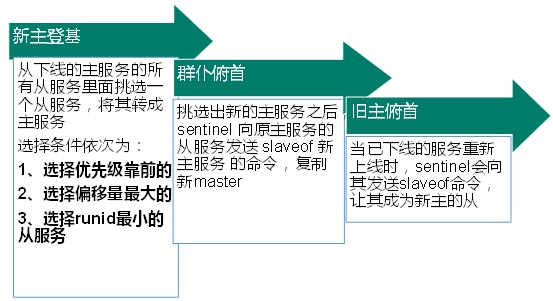
4、哨兵模式(sentinel)
-
是什么?
-
步骤:
-
private static JedisSentinelPool jedisSentinelPool=null; public static Jedis getJedisFromSentinel(){ if(jedisSentinelPool==null){ Set<String> sentinelSet=new HashSet<>(); sentinelSet.add("192.168.11.103:26379"); JedisPoolConfig jedisPoolConfig =new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(10); //最大可用连接数 jedisPoolConfig.setMaxIdle(5); //最大闲置连接数 jedisPoolConfig.setMinIdle(5); //最小闲置连接数 jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待 jedisPoolConfig.setMaxWaitMillis(2000); //等待时间 jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pong jedisSentinelPool=new JedisSentinelPool("mymaster",sentinelSet,jedisPoolConfig); return jedisSentinelPool.getResource(); }else{ return jedisSentinelPool.getResource(); } }
5、复制的缺点
复制延迟:
由于所有的写操作都是在Master上,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
八、Redis的Java客户端Jedis
1、测试Jedis的联通性
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.1.0</version>
</dependency>
- 测试联通
public class TestPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.2.138",6379);
System.out.println(jedis.ping());
}
}
2、Jedis常用API
package com.redis;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import redis.clients.jedis.Jedis;
public class TestPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.2.138",6379);
//String
// jedis.set("k1", "v1");
// jedis.set("k2", "v2");
// jedis.set("k3", "v3");
System.out.println(jedis.get("k1"));
jedis.set("k4","v4");
System.out.println("============================");
System.out.println(jedis.mset("k5","v5","k6","v6"));
System.out.println(jedis.mget("k5","k6"));
//key
System.out.println("------------------------------------------------key");
Set<String> keys = jedis.keys("*");
System.out.println(keys.size());
for (Iterator iterator = keys.iterator(); iterator.hasNext();) {
String key = (String) iterator.next();
System.out.println(key);
}
System.out.println("jedis.exists===>"+jedis.exists("k2"));
System.out.println(jedis.ttl("k1"));
//List
System.out.println("------------------------------------------------list");
// jedis.lpush("mylist", "v1","v2","v3","v4","v5");//将一个或多个值插入到列表头部
List<String> list = jedis.lrange("mylist", 0, -1);//获取列表指定范围内的元素
System.out.println(list);
for(String element : list) {
System.out.println(element);
}
System.out.println("-----------------------------------------------set");
jedis.sadd("ords", "set01");//将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略。
jedis.sadd("ords", "set02");
jedis.sadd("ords", "set03");
Set<String> smembers = jedis.smembers("ords");//返回集合中的所有的成员。 不存在的集合 key 被视为空集合。
System.out.println(smembers);
for(Iterator<String> iterator = smembers.iterator();iterator.hasNext();) {
String element = iterator.next();
System.out.println(element);
}
jedis.srem("ords", "set02");//移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略
System.out.println(jedis.smembers("ords").size());
System.out.println("-----------------------------------------------hash");
jedis.hset("hash1","userName", "lisi");// 将哈希表 key 中的字段 field 的值设为 value 。此命令会覆盖哈希表中已存在的字段。如果哈希表不存在,会创建一个空哈希表,并执行 HMSET 操作。
String hget = jedis.hget("hash1","userName");
System.out.println(hget);
HashMap<String,String> map = new HashMap<String,String>();
map.put("phone","110");
map.put("addr","中国");
map.put("email","123@gmail.com");
jedis.hmset("hash2",map);//同时将多个 field-value (字段-值)对设置到哈希表中。
List<String> hmget = jedis.hmget("hash2", "phone","addr","email");//返回哈希表中,一个或多个给定字段的值。
System.out.println(hmget);
for(String element : hmget) {
System.out.println(element);
}
System.out.println("------------------------------------------------zset");
jedis.zadd("zset01", 60d,"v1");//向有序集合添加一个或多个成员,或者更新已存在成员的分数
jedis.zadd("zset01", 70d,"v2");
jedis.zadd("zset01", 80d,"v3");
jedis.zadd("zset01", 90d,"v4");
Set<String> zrange = jedis.zrange("zset01", 0, -1);//通过索引区间返回有序集合成指定区间内的成员
System.out.println(zrange);
}
}
3、Jedis事务
package com.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Transaction;
public class TestTx {
/**
* 通俗点讲,watch命令就是标记一个键,如果标记的该建在提交事务之前被别人修改过,那事务就会失败,这种情况通常可以在程序中重新在尝试一次。
* 首先标记了键balance,然后检查余额是否足够,不足就取消标记,并不作扣减
* 足够的话,就启动事务进行更新操作,
* 如果在此期间键balance被其他人修改,那在提交事务(执行exec)时就会报错,
* 程序中通常可以捕获这类错误再重新执行一次,直到成功
* @return
* @throws InterruptedException
*/
private boolean transMethod() throws InterruptedException {
Jedis jedis = new Jedis("192.168.2.138",6379);
int balance ;//可用余额
int debt ;//欠额
int amtToSubtract = 10 ;//实刷额度
jedis.watch("balance");
Thread.sleep(7000);//用线程模拟加塞
//jedis.set("balance","5");//此句不该出现,讲课方便。模拟其他程序已经修改了该条目
balance = Integer.parseInt(jedis.get("balance"));
if(balance < amtToSubtract) {
jedis.unwatch();//放弃监控
System.out.println("余额不足");
return false;
}else {
Transaction transaction = jedis.multi();//开启事务
transaction.decrBy("balance", amtToSubtract);
transaction.incrBy("debt",amtToSubtract);
transaction.exec();//执行事务
balance = Integer.parseInt(jedis.get("balance"));
debt = Integer.parseInt(jedis.get("debt"));
System.out.println("可用余额:"+balance);
System.out.println("支出:"+debt);
return true;
}
}
public static void main(String[] args) throws InterruptedException {
TestTx test = new TestTx();
boolean retValue = test.transMethod();
System.out.println(retValue);
}
}
正常情况执行结果:

事务在未执行前(exec),其他线程改动了balance导致事务不能正常执行,支出为0,结果如图:

重新再执行一次可以发现事务正常执行了(其他线程没有操作balance)。
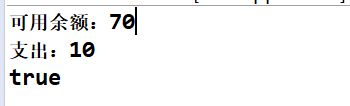
4、Jedis主从复制
package com.redis;
import java.io.Serializable;
import redis.clients.jedis.Jedis;
public class TestMS {
public static void main(String[] args) {
Jedis jedis_M = new Jedis("192.168.2.138",6379);//主机 写
Jedis jedis_S = new Jedis("192.168.2.138",6380);//从机 读
jedis_S.slaveof("192.168.2.138", 6379);//配置从机
jedis_M.set("master", "this is comment");
//内存中读写太快,防止读在写之前先完成而出现null的情况,这里做一下延迟
Thread.sleep(2000);
String val = jedis_S.get("master");
System.out.println(val);
}
}
第一次控制台打印的是null,再次执行即可。原因是内存数据库读写太快,读在写之前文成了,可以手动延迟一下。

5、JedisPool连接池
获取Jedis实例需要从JedisPool中获取,用完Jedis实例需要返还给JedisPool,如果Jedis在使用过程中出错,则也许需要还给JedisPool。
JedisPoolUtil.class
package com.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPoolUtil {
private static volatile JedisPool jedispool = null;
private JedisPoolUtil() {}
public static JedisPool getJedisPoolInstance() {
if(null == jedispool) {
synchronized (JedisPoolUtil.class) {
if(null == jedispool) {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxActive(1000);
poolConfig.setMaxIdle(32);
poolConfig.setMaxWait(100 * 1000);
poolConfig.setTestOnBorrow(true);;
jedispool = new JedisPool(poolConfig,"192.168.2.138",6379);
}
}
}
return jedispool;
}
public static void release(JedisPool jedisPool,Jedis jedis) {
if(null != jedis) {
jedisPool.returnBrokenResource(jedis);
}
}
}
TestPool.class
package com.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
public class TestPool {
public static void main(String[] args) {
JedisPool jedisPool = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set("aa","bb");
System.out.println(jedis.get("aa"));
} catch (Exception e) {
e.printStackTrace();
}finally {
JedisPoolUtil.release(jedisPool, jedis);
}
}
}
配置总结:
JedisPool的配置参数大部分是由JedisPoolConfig的对应项来赋值的。
maxActive:控制一个pool可分配多少个jedis实例,通过pool.getResource()来获取;如果赋值为-1,则表示不限制;如果pool已经分配了maxActive个jedis实例,则此时pool的状态为exhausted。
maxIdle:控制一个pool最多有多少个状态为idle(空闲)的jedis实例;
whenExhaustedAction:表示当pool中的jedis实例都被allocated完时,pool要采取的操作;默认有三种。
WHEN_EXHAUSTED_FAIL --> 表示无jedis实例时,直接抛出NoSuchElementException;
WHEN_EXHAUSTED_BLOCK --> 则表示阻塞住,或者达到maxWait时抛出JedisConnectionException;
WHEN_EXHAUSTED_GROW --> 则表示新建一个jedis实例,也就说设置的maxActive无用;
maxWait:表示当borrow一个jedis实例时,最大的等待时间,如果超过等待时间,则直接抛JedisConnectionException;
testOnBorrow:获得一个jedis实例的时候是否检查连接可用性(ping());如果为true,则得到的jedis实例均是可用的;
testOnReturn:return 一个jedis实例给pool时,是否检查连接可用性(ping());
testWhileIdle:如果为true,表示有一个idle object evitor线程对idle object进行扫描,如果validate失败,此object会被从pool中drop掉;这一项只有在timeBetweenEvictionRunsMillis大于0时才有意义;
timeBetweenEvictionRunsMillis:表示idle object evitor两次扫描之间要sleep的毫秒数;
numTestsPerEvictionRun:表示idle object evitor每次扫描的最多的对象数;minEvictableIdleTimeMillis
minEvictableIdleTimeMillis:表示一个对象至少停留在idle状态的最短时间,然后才能被idle object evitor扫描并驱逐;这一项只有在timeBetweenEvictionRunsMillis大于0时才有意义;
softMinEvictableIdleTimeMillis:在minEvictableIdleTimeMillis基础上,加入了至少minIdle个对象已经在pool里面了。如果为-1,evicted不会根据idle time驱逐任何对象。如果minEvictableIdleTimeMillis>0,则此项设置无意义,且只有在timeBetweenEvictionRunsMillis大于0时才有意义;
lifo:borrowObject返回对象时,是采用DEFAULT_LIFO(last in first out,即类似cache的最频繁使用队列),如果为False,则表示FIFO队列;
其中JedisPoolConfig对一些参数的默认设置如下:
testWhileIdle=true
minEvictableIdleTimeMills=60000
timeBetweenEvictionRunsMillis=30000
numTestsPerEvictionRun=-1
6、Jedis实例-手机验证码
要求:
1、输入手机号,点击发送后随机生成6位数字码,2分钟有效
分析:

package com.redis;
import java.util.Random;
import redis.clients.jedis.Jedis;
public class PhoneCode {
public static void main(String[] args) {
chickCode("15661311412");
// getCheckCode("852113");
}
public static void getCheckCode(String code) {
Jedis jedis = new Jedis("192.168.2.138",6379);
String getCode = jedis.get("code");
if(getCode.equals(code)) {
System.out.println("成功!");
}else {
System.out.println("失败!");
}
jedis.quit();
}
//每个手机号每天只能发送三次,验证码写到redis中,设置过期时间
public static void chickCode(String phone) {
Jedis jedis = new Jedis("192.168.2.138",6379);
String countKey = "count"; //发送手机号次数的
String codeKey = "code"; //存取验证码的key
//从redis读取发送手机号的次数
String count = jedis.get(countKey);
System.out.println(count);
//判断手机号发送次数
if(null == count) {
//没有发送,第一次发送,redis中没有这个数据,就相当于set一个key
jedis.setex(countKey, 24*60*60,"1");
}else if(Integer.parseInt(count) <= 2) {
//发送次数+1
jedis.incr(countKey);
}else if(Integer.parseInt(count) > 2){
//发送了三次,禁止再发送
System.out.println("发送次数已超过3次");
jedis.quit();
return;
}
//调用生成验证码的方法
String code = getCode();
//将验证码写到redis中
jedis.setex(codeKey,120,code);
jedis.quit();
}
//生成随机6位验证码
public static String getCode() {
Random random_code = new Random();
String code = "";
for(int i = 0;i<6;i++) {
code += random_code.nextInt(10);
}
return code;
}
}
九、Spring Boot整合Redis
Spring Boot整合Redis非常简单,只需要按如下步骤整合即可
1、 添加缓存依赖
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- spring2.X集成redis所需common-pool2-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.0</version>
</dependency>
2、 配置application.properties
#Redis服务器地址
spring.redis.host=192.168.140.136
#Redis服务器连接端口
spring.redis.port=6379
#Redis数据库索引(默认为0)
spring.redis.database= 0
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
3、 添加配置类
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
十、Redis集群
1、问题
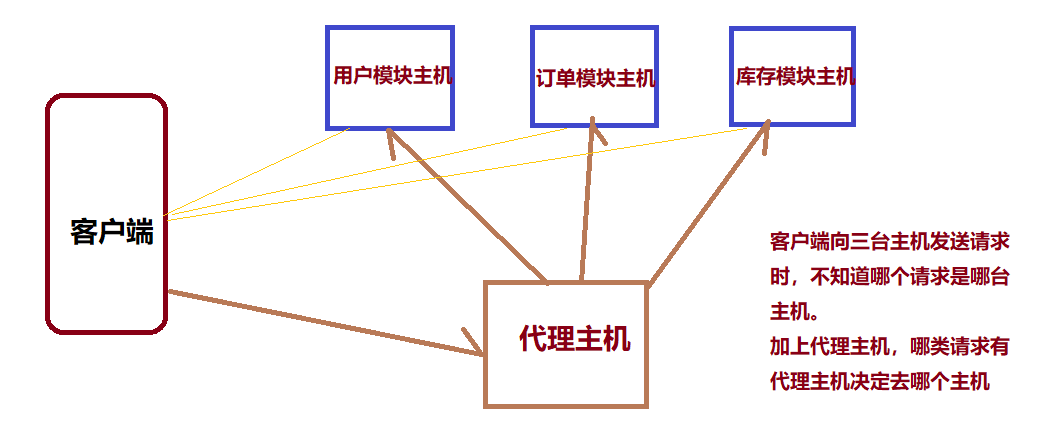
另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息
通过代理主机来解决,但是redis3.0中提供了解决方案。就是无中心化集群配置。
代理主机:
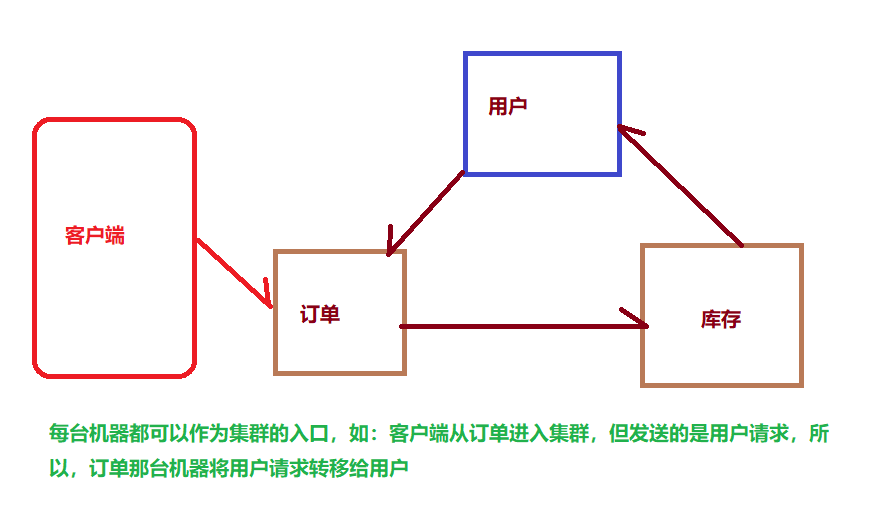
2、什么是集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
3、Redis集群搭建
-
删除持久化数据
将rdb,aof文件都删除掉 -
配置6实例
6379,6380,6381,6389,6390,6391 -
配置基本信息
开启daemonize yes
Pid文件名字
指定端口
Log文件名字
Dump.rdb名字
Appendonly 关掉或者换名字 -
配置集群文件
include /home/bigdata/redis.conf port 6379 pidfile "/var/run/redis_6379.pid" dbfilename "dump6379.rdb" # dir "/home/bigdata/redis_cluster" # logfile "/home/bigdata/redis_cluster/redis_err_6379.log" cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 15000 -
复制多个redis.conf文件
-
启动6个redis服务

-
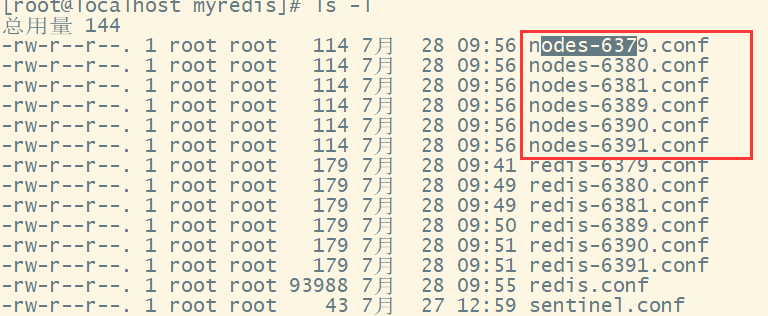
组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
- 合体
cd /opt/redis-6.2.7/src (下面的命令必须在该目录下)
redis-cli --cluster create --cluster-replicas 1 192.168.2.138:6379 192.168.2.138:6380 192.168.2.138:6381 192.168.2.138:6389 192.168.2.138:6390 192.168.2.138:6391此处不要用127.0.0.1,请用真实IP地址
–replicas 1 采用最简单的方式配置集群,一台主机,一台从机,正好三组。
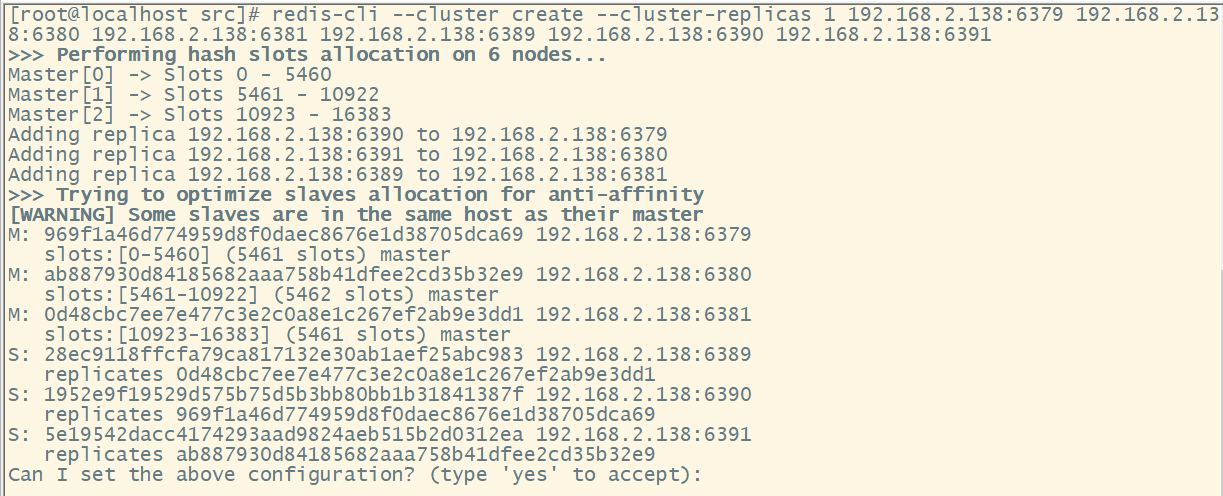
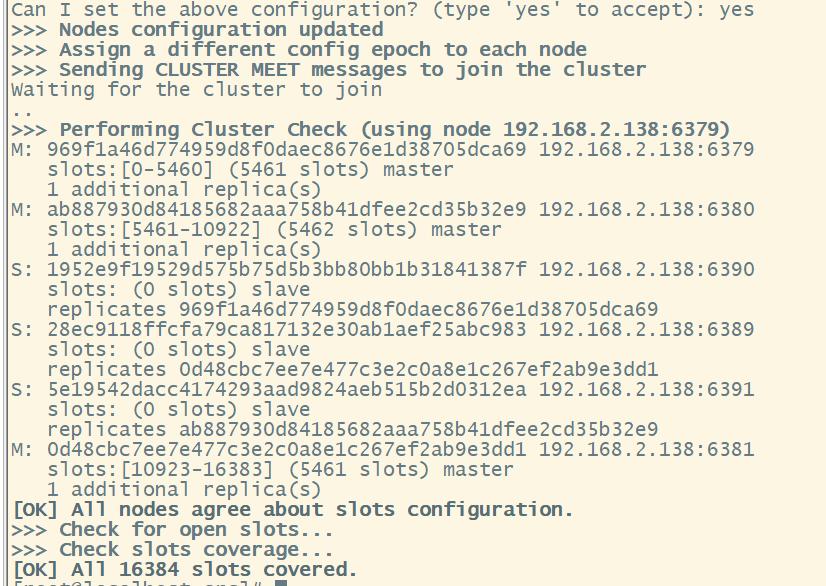
-
一个集群至少要有三个节点。
选项 –cluster-replicas 1 表示我们希望为集群中的每个结点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在同一个IP地址


4、什么是slots

一个Redis集群包含16384个插槽(hash slot),数据库中的每个键都属于这个16384个插槽的其中一个。
集群使用公式CRC16(key) % 16384来计算键key属于哪个槽,其中CRC16(key)语句用于计算键key的CRC16校验和。
集群中的每个节点负责处理一部分插槽。如:如果一个集群可以有主节点,其中:
节点A负责处理0~5460号插槽。

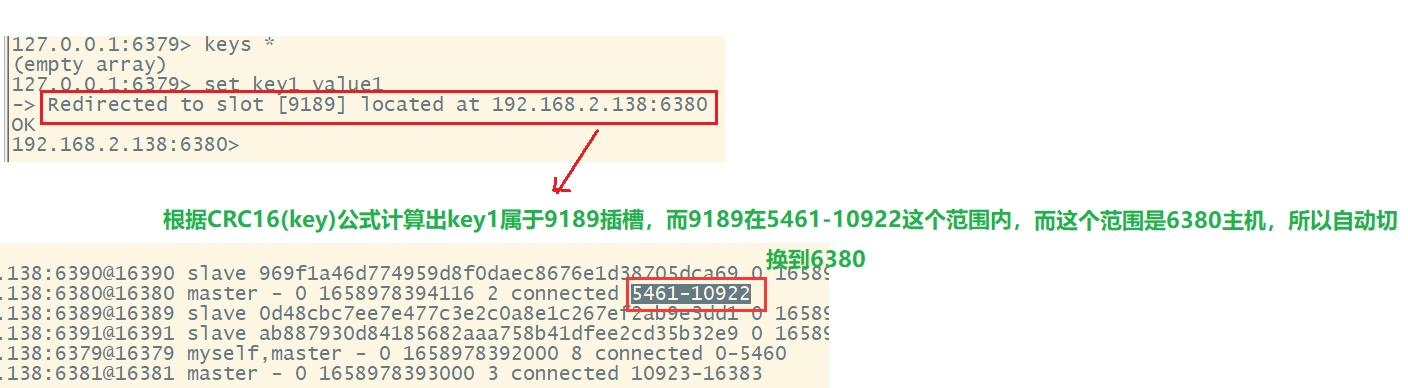
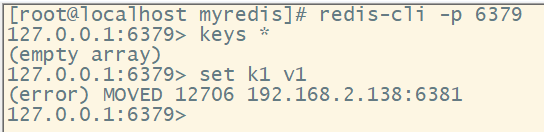
5、在集群中录入值
在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。
redis-cli客户端提供了 -c 参数实现自动重定向。
如:redis-cli -c -p 6379登录后,在录入、查询键值对可以自动重定向。
不在一个slot下的键值,是不能使用mget、mset等多键操作。

可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。

6、查询集群中的值
CLUSTER GETKEYSINSLOT 返回 count 个 slot 槽中的键。
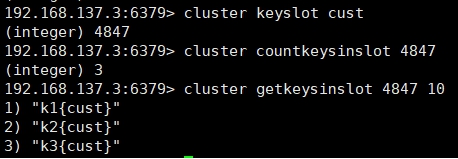
7、故障恢复
如果主节点下线?从节点能否自动升级为主节点?注意15秒超时


如果所有某一段插槽的主节点都宕掉,redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为yes,那么,整个集群都挂掉
如果某一段的插槽主从都挂掉,而cluster-require-full-coverage为no,那么,该插槽数据全都不能使用,也无法存储。
redis.conf中的参数 cluster-require-full-coverage
8、集群的Jedis开发
即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。
无中心化主从集群。无论从哪台主机写的数据,其他主机上都能读到数据。
public class JedisClusterTest {
public static void main(String[] args) {
Set<HostAndPort>set =new HashSet<HostAndPort>();
set.add(new HostAndPort("192.168.31.211",6379));
JedisCluster jedisCluster=new JedisCluster(set);
jedisCluster.set("k1", "v1");
System.out.println(jedisCluster.get("k1"));
}
}
9、集群的优势&劣势
-
优点
-
缺点
不支持多键操作;不支持多键的事务;不支持LUA脚本
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不知逐步过渡,复杂度较大。
十一、Redis应用问题解决
1、缓存穿透
1、问题描述
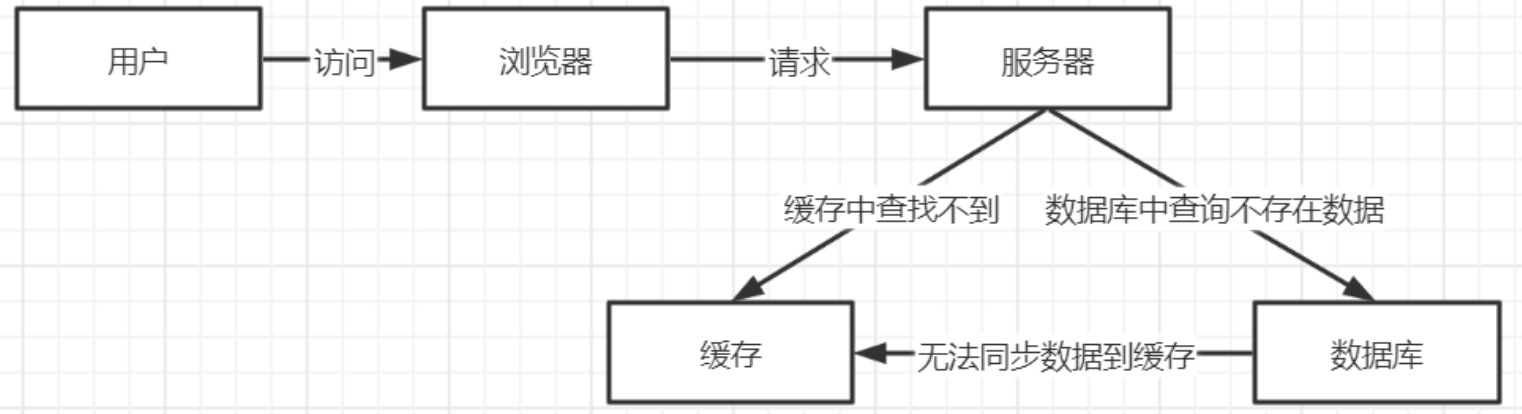
当用户在查询一条数据的时候,而此时数据库和缓存却没有关于这条数据的任何记录,而这条数据在缓存中没找到就会向数据库请求获取数据。用户拿不到数据时,就会一直发请求,查询数据库,这样会对数据库的访问造成很大的压力。
如:用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,当信息没有返回时,会一直向数据库查询从而给当前数据库的造成很大的访问压力。
缓存穿透的发生一般是受到 “黑客攻击” 所导致的,所以应该进行监控,如果真的是黑客攻击,及时添加黑名单。
2、解决方案
**(1)对控制缓存:**缓存空值 会让redis多了很多没用的键,会占用空间 可以设置一个过期时间 expiretime 去自动清除
**(2)设置白名单:**通过使用Bitmaps,将允许访问的id按偏移量存储到Bitmaps)每次访问和Bitmaps中的id进行比较,保证了安全性,牺牲了性能。
**(3)采用布隆过滤器:**它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被 这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
(4)实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
2、缓存击穿
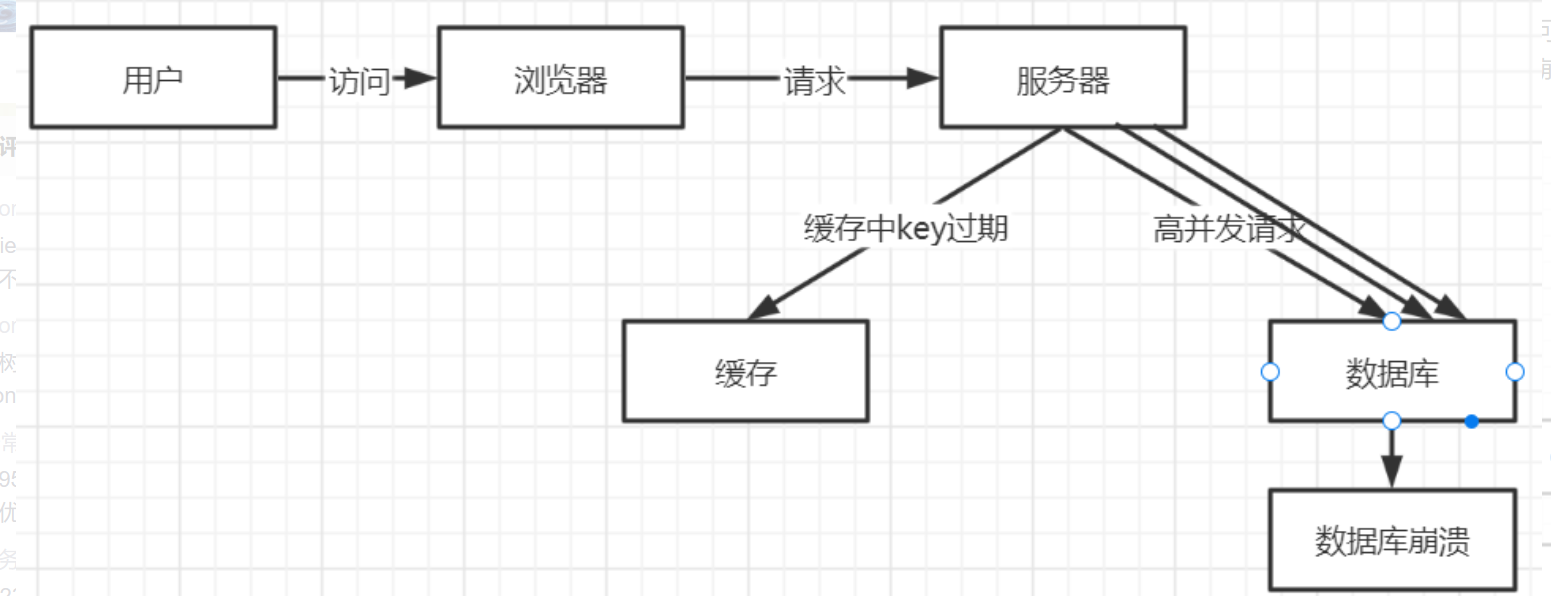
1、问题描述
key中对应数据存在,当key中对应的数据在缓存中过期,而此时又有大量请求访问该数据,缓存中过期了,请求会直接访问数据库并回设到缓存中,高并发访问数据库会导致数据库崩溃。
2、解决方案
(1)**预先设置热门数据:**在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
(2)实时调整:现场监控哪些数据热门,实时调整key的过期时长
(3)使用锁:
- 就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
- 先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key
- 当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key
- 当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
3、缓存雪崩
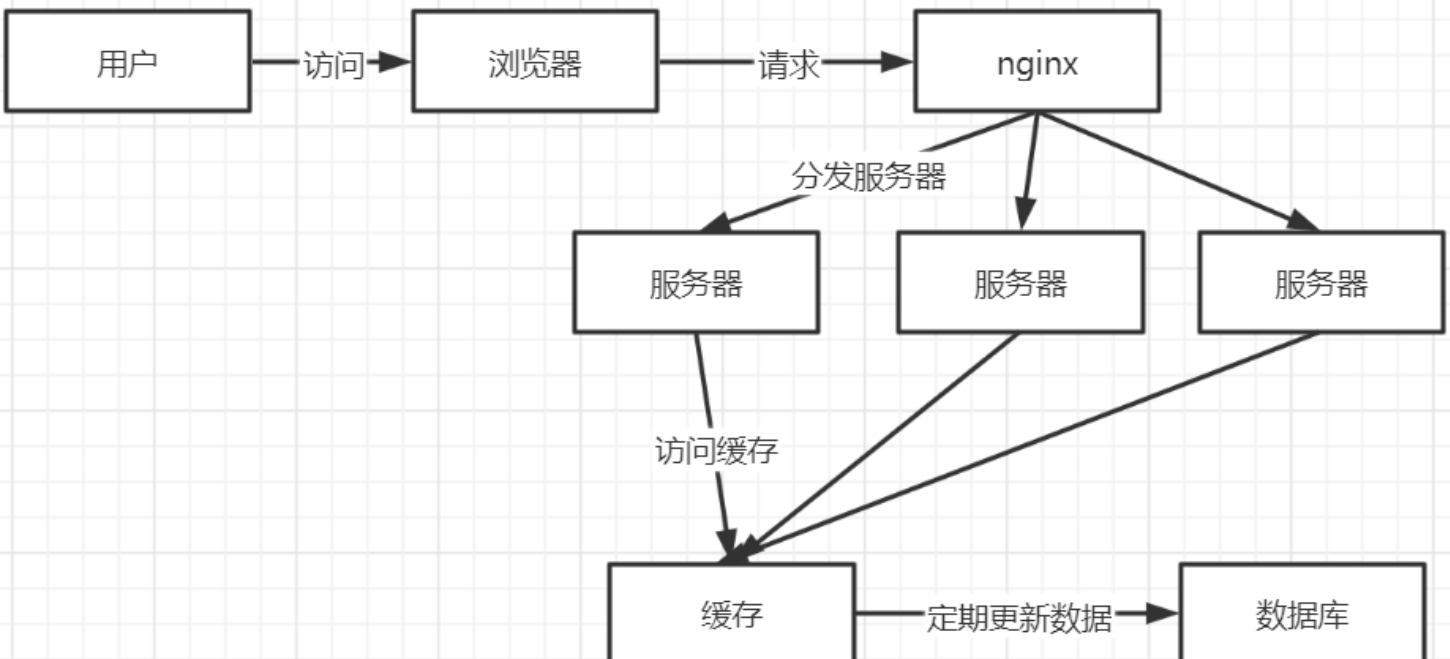
1、问题描述
key中对应数据存在,在某一时刻,缓存中大量key过期,而此时大量高并发请求访问,会直接访问后端数据库,导致数据库奔溃。
注意:缓存击穿是针对一个key对应在缓存中数据过期,缓存雪崩是大部分key对应缓存数据过期
正常访问:
缓存失效瞬间:
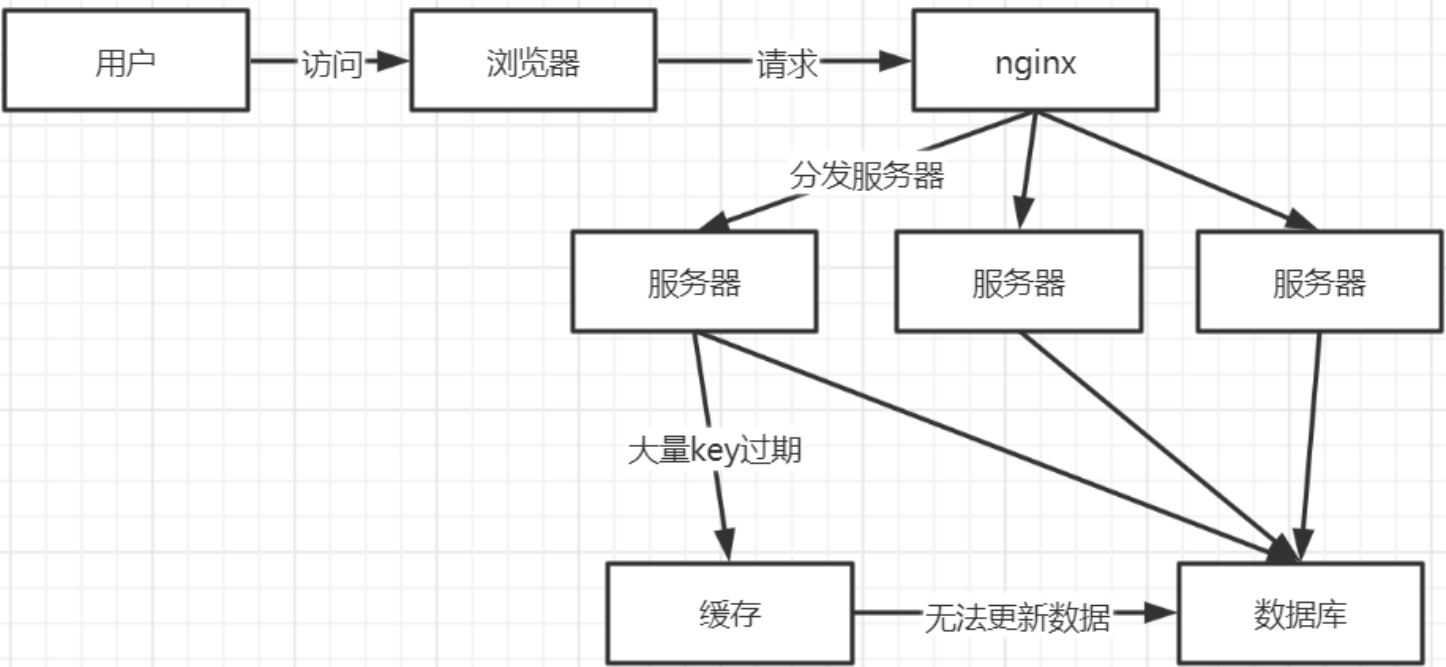
2、解决方案
(1) **构建多级缓存架构:**nginx缓存 + redis缓存 +其他缓存(ehcache等)
(2) 使用锁或队列:
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3) 设置过期标志更新缓存:
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4) 将缓存失效时间分散开:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
4、分布式锁
1、描述
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
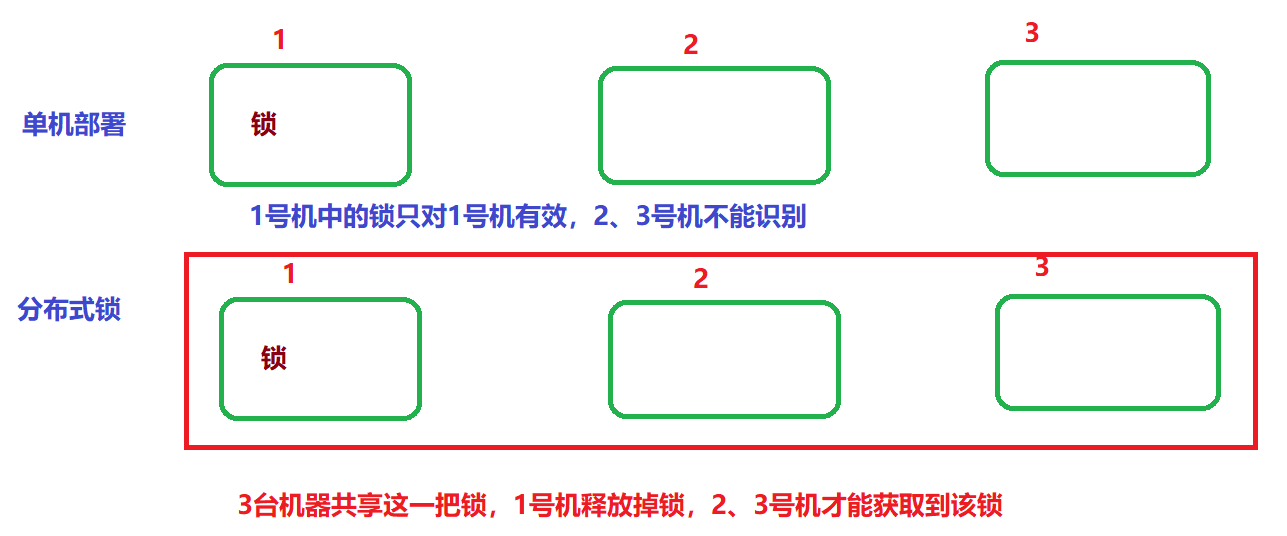
这里,我们就基于redis实现分布式锁。
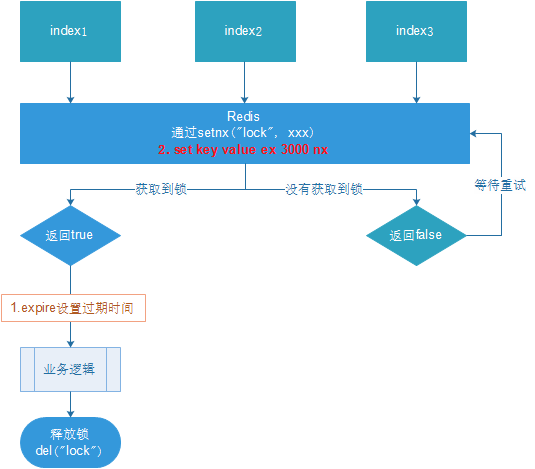
2、使用redis实现分布式锁
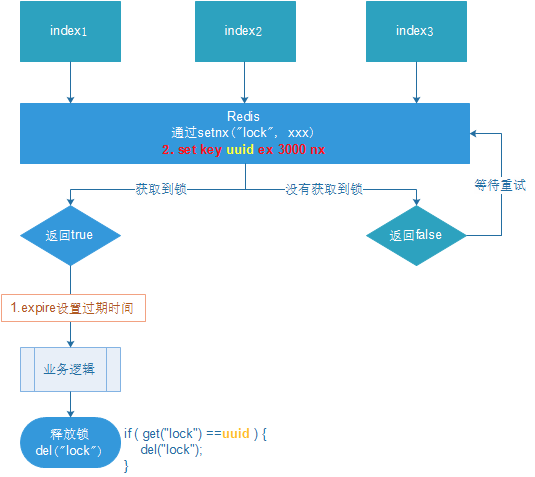
使用setnx 命令上锁,通过del 释放锁。
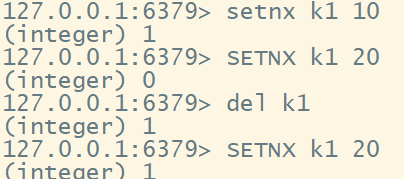
如果锁一直没有释放呢?设置key过期时间,自动释放。
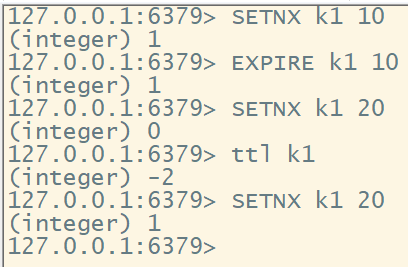
如果上锁时突然异常,来不及设置过期时间呢?上锁的同时设置过期时间(原子性操作)
使用命令: set nx ex
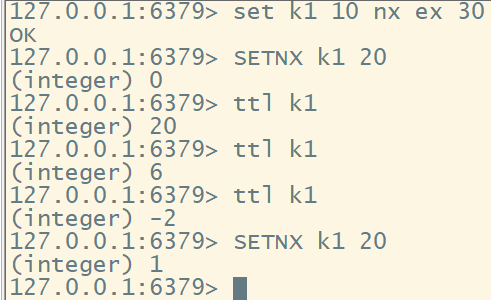
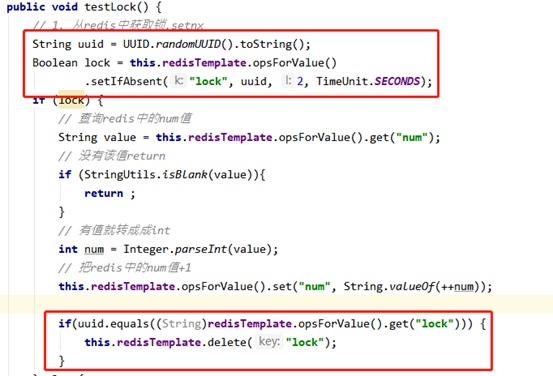
3、Java代码实现Redis分布式锁
redis中设置key num “0”
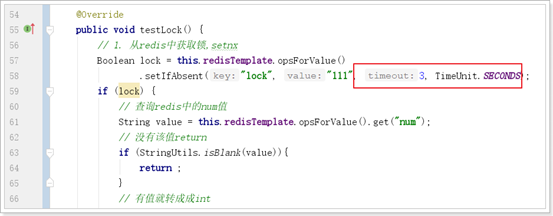
@GetMapping("testLock")
public void testLock(){
//1获取锁,setnx
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111");
//2获取锁成功、查询num的值
if(lock){
Object value = redisTemplate.opsForValue().get("num");
//2.1判断num为空return
if(StringUtils.isEmpty(value)){
return;
}
//2.2有值就转成成int
int num = Integer.parseInt(value+"");
//2.3把redis的num加1
redisTemplate.opsForValue().set("num", ++num);
//2.4释放锁,del
redisTemplate.delete("lock");
}else{
//3获取锁失败、每隔0.1秒再获取
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
问题:setnx刚好获取到锁,业务逻辑出现异常,导致锁无法释放
解决:设置过期时间,自动释放锁。
问题:可能释放其他服务器的锁(如图描述)
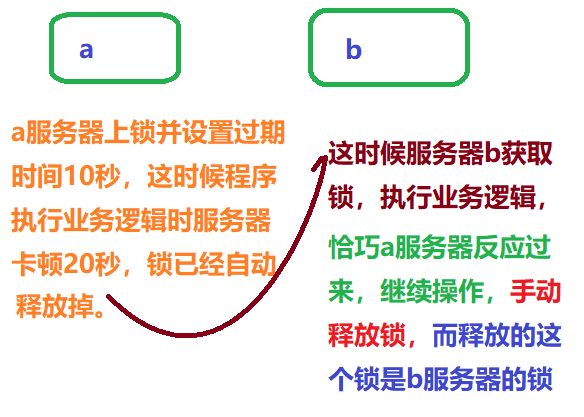
解决:setnx获取锁的同时,设置一个指定唯一值(uuid);释放前获取这个值,判断是否是自己的锁。
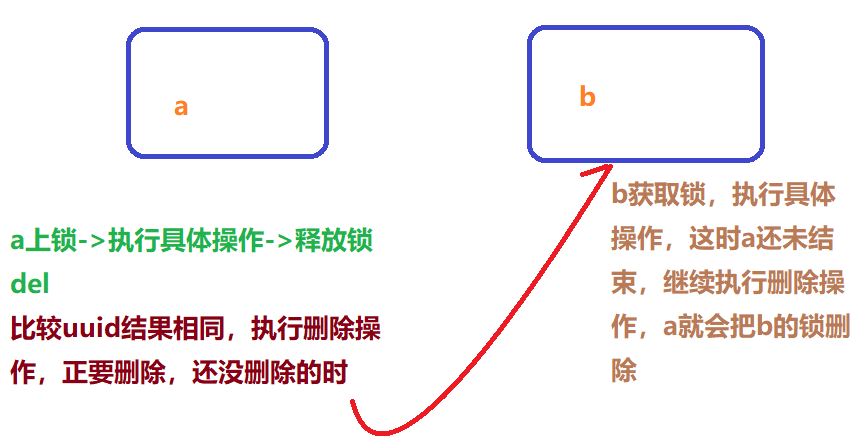
问题:删除缺乏原子性(问题描述如图)
@GetMapping("testLockLua")
public void testLockLua() {
//1 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
//2 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
// 3 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock) {
// 执行的业务逻辑开始
// 获取缓存中的num 数据
Object value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value + "");
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set("num", String.valueOf(++num));
/*使用lua脚本来锁*/
// 定义lua 脚本
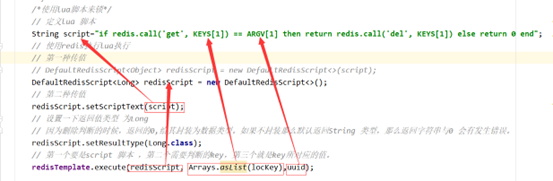
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,
// 那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Lua脚本详解:
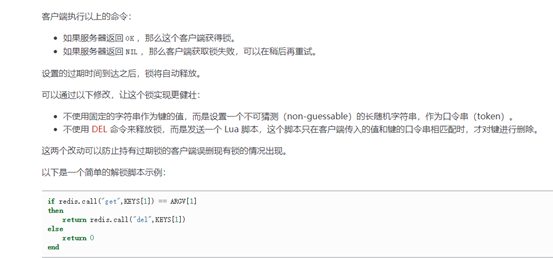
1. 定义key,key应该是为每个sku定义的,也就是每个sku有一把锁。
String locKey ="lock:"+skuId; // 锁住的是每个商品的数据
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid,3,TimeUnit.SECONDS);
总结:
(1)加锁:
// 1. 从redis中获取锁,set k1 v1 px 20000 nx
String uuid = UUID.randomUUID().toString();
Boolean lock = this.redisTemplate.opsForValue()
.setIfAbsent("lock", uuid, 2, TimeUnit.SECONDS);
(2)使用Lua释放锁:
// 2. 释放锁 del
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 设置lua脚本返回的数据类型
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
// 设置lua脚本返回类型为Long
redisScript.setResultType(Long.class);
redisScript.setScriptText(script);
redisTemplate.execute(redisScript, Arrays.asList("lock"),uuid);
(3)重试:
Thread.sleep(500);
testLock();
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
– 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
– 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
redisTemplate.opsForValue().get(“num”);
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value + “”);
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set(“num”, String.valueOf(++num));
/使用lua脚本来锁/
// 定义lua 脚本
String script = “if redis.call(‘get’, KEYS[1]) == ARGV[1] then return redis.call(‘del’, KEYS[1]) else return 0 end”;
// 使用redis执行lua执行
DefaultRedisScript redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,
// 那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Lua脚本详解:
[外链图片转存中...(img-AMGne8nP-1687078790901)]
项目中正确使用:
```java
1. 定义key,key应该是为每个sku定义的,也就是每个sku有一把锁。
String locKey ="lock:"+skuId; // 锁住的是每个商品的数据
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid,3,TimeUnit.SECONDS);
[外链图片转存中…(img-NeV4ub46-1687078790902)]
总结:
(1)加锁:
// 1. 从redis中获取锁,set k1 v1 px 20000 nx
String uuid = UUID.randomUUID().toString();
Boolean lock = this.redisTemplate.opsForValue()
.setIfAbsent("lock", uuid, 2, TimeUnit.SECONDS);
(2)使用Lua释放锁:
// 2. 释放锁 del
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 设置lua脚本返回的数据类型
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
// 设置lua脚本返回类型为Long
redisScript.setResultType(Long.class);
redisScript.setScriptText(script);
redisTemplate.execute(redisScript, Arrays.asList("lock"),uuid);
(3)重试:
Thread.sleep(500);
testLock();
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
– 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
– 解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
原文地址:https://blog.csdn.net/weixin_44900183/article/details/131273550
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_43654.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







