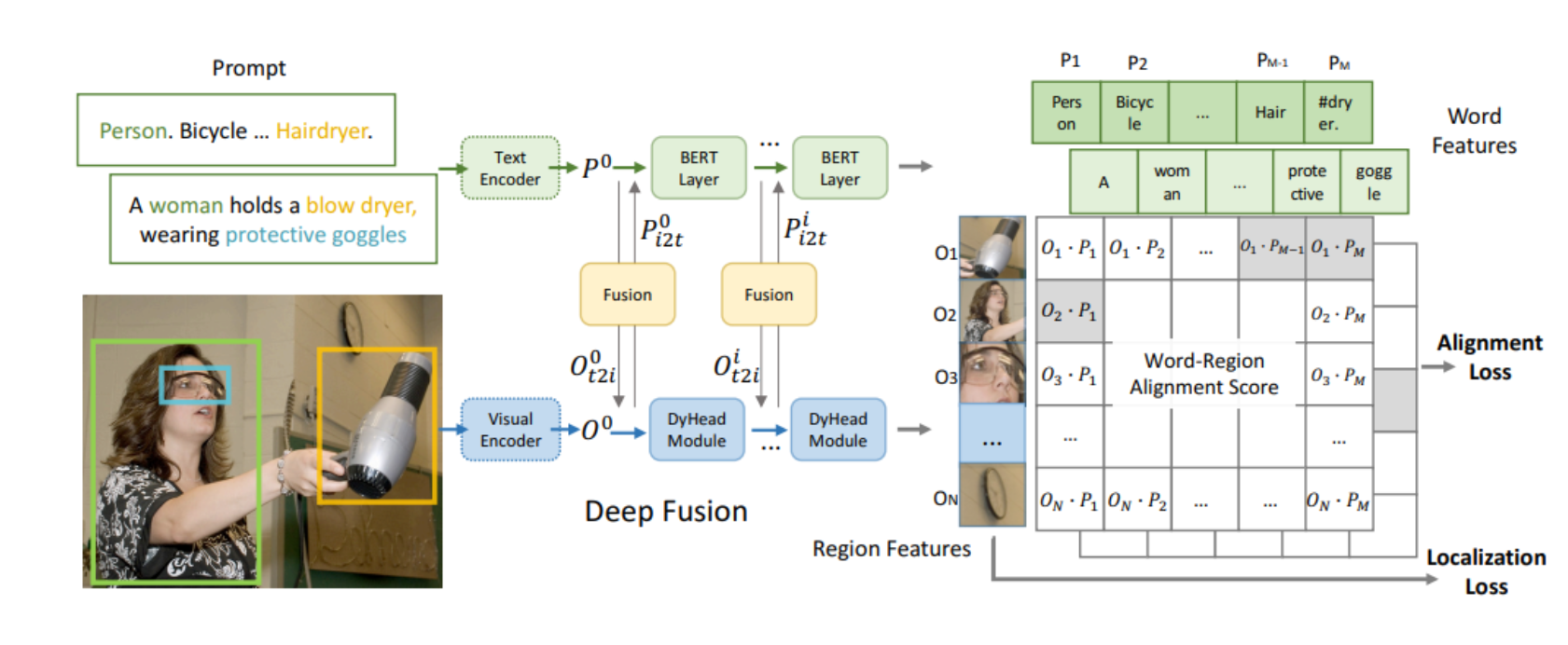
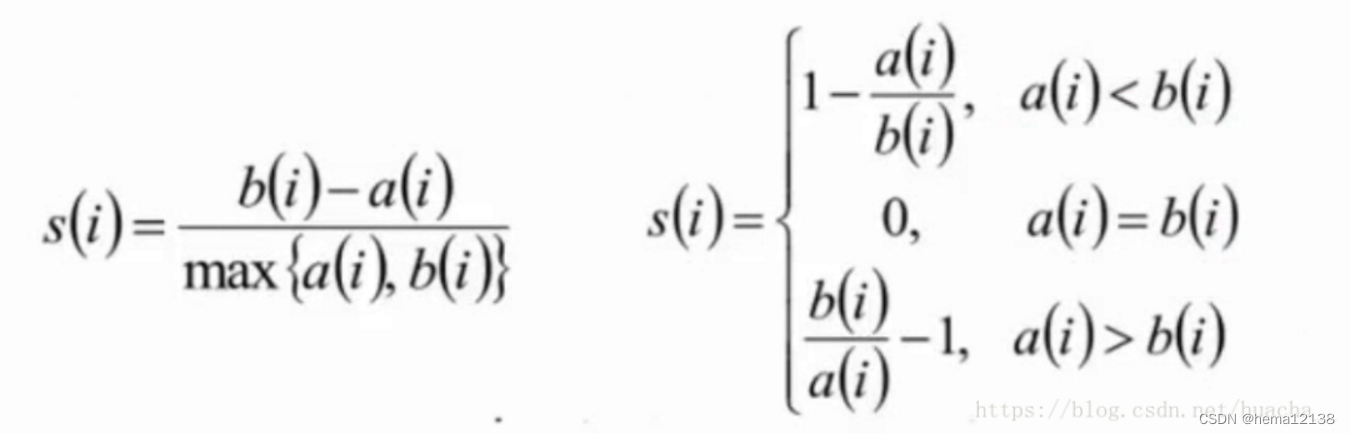本文介绍: 温度系数的作用是调节对困难样本的关注程度:越小的温度系数越关注于将本样本和最相似的困难样本分开,去得到更均匀的表示。在无监督无标注的情况下,这样的伪负例,其实是不可避免的,首先可以想到的方式是去扩大语料库,去加大batch size,以降低batch训练中采样到伪负例的概率,减少它的影响。可以把不同的负样本想像成同极点电荷在不同距离处的受力情况,距离越近的点电荷受到的库伦斥力更大,而距离越远的点电荷受到的斥力越小。对比损失中,越近的负例受到的斥力越大,具体的表现就是对应的负梯度值越大[4]。
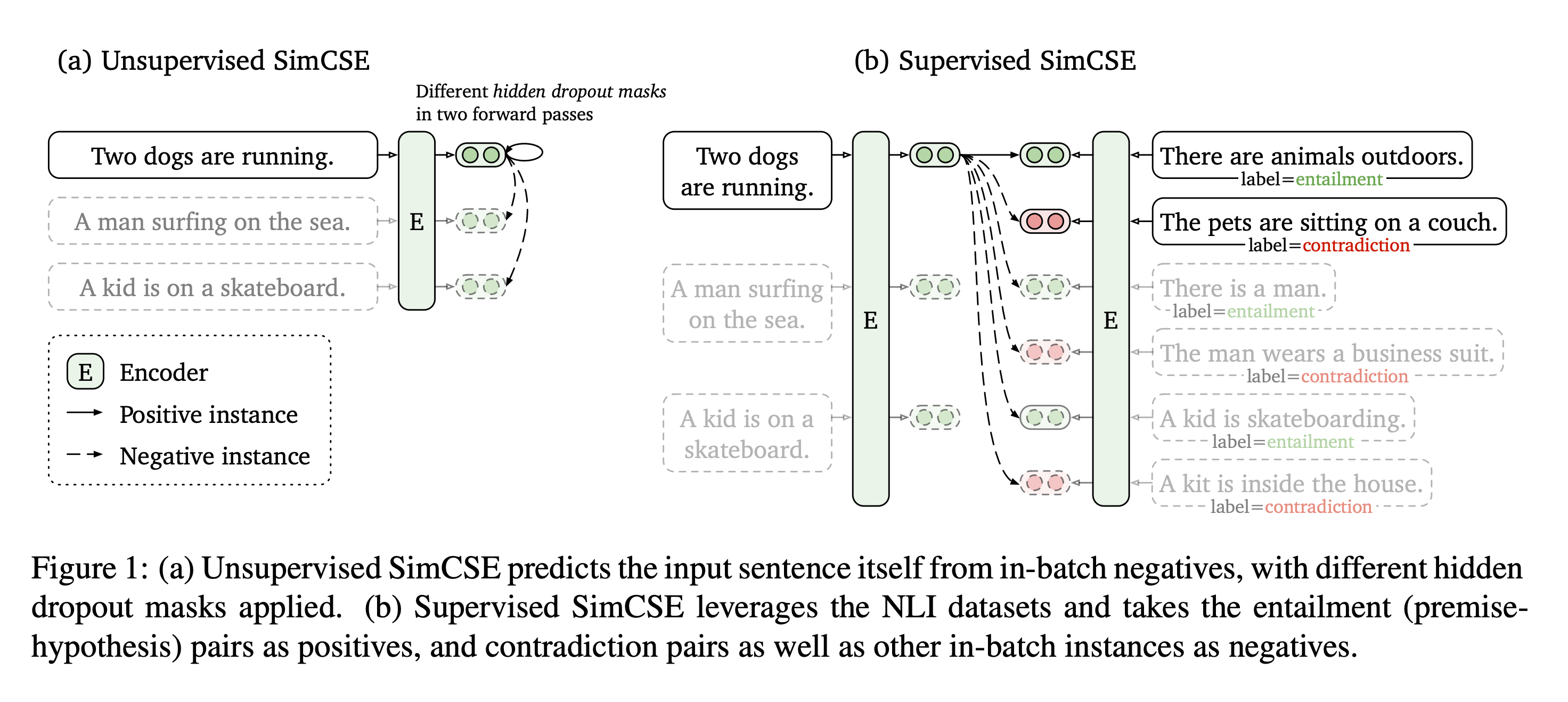
无监督pair构造:
其实一个batch,比如有N个句子对,那么就有2N个句子,其中正例是1个,负样本应该是总样本数目2N减去样本本身,也就是2N-1;

有监督的pair构造:
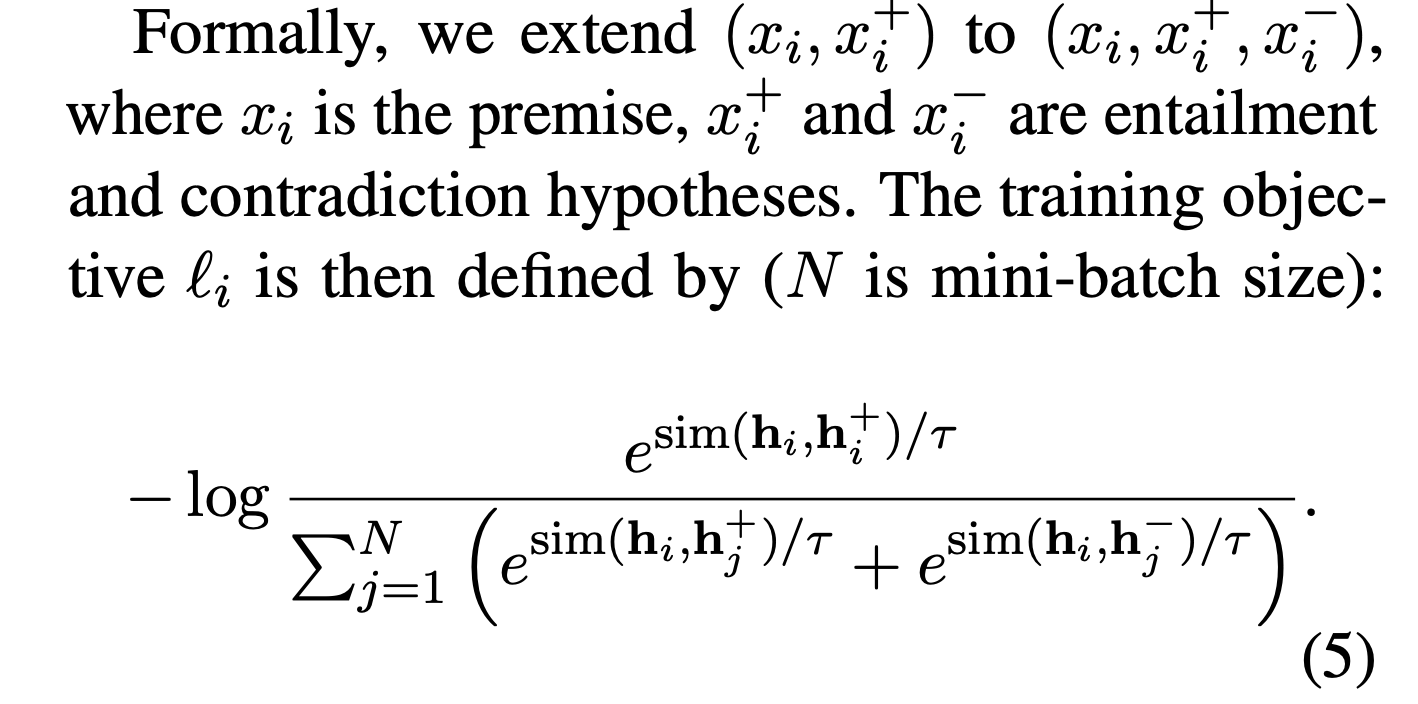
infoNCE Loss的理解:

构造案例:

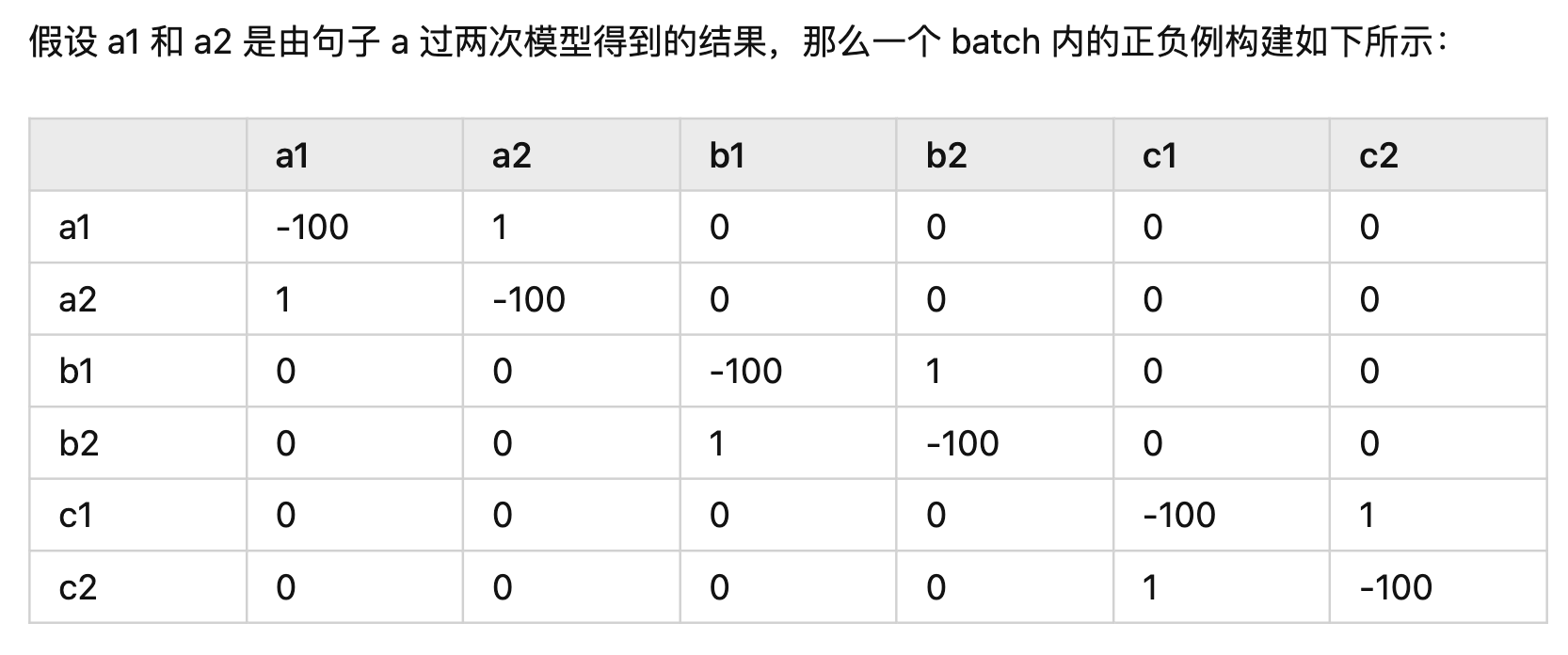
对比学习的loss:
度量学习的loss:
SimCSE的缺点
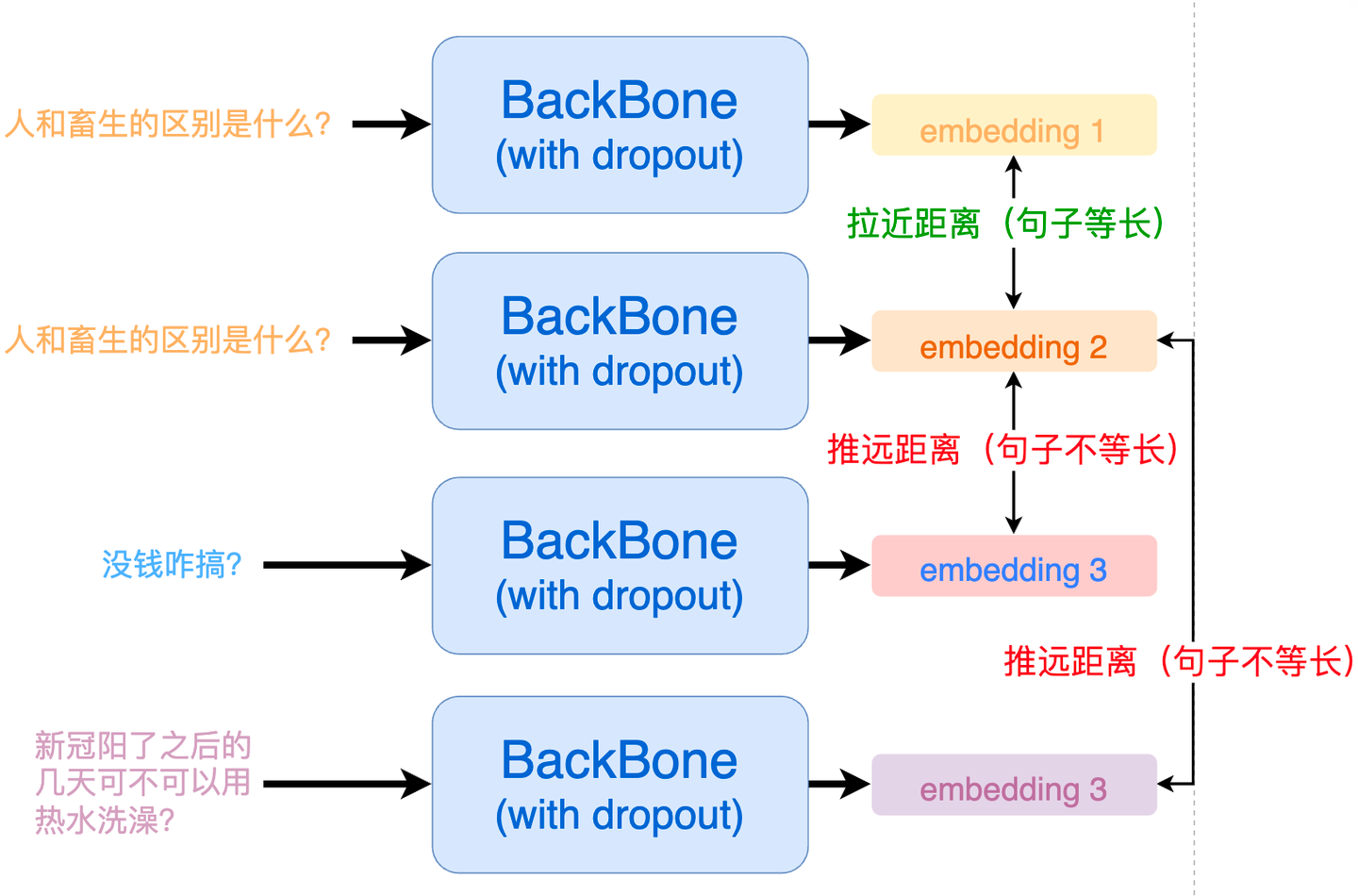
单/双塔
关于PromptPromptBert:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。