本文介绍: Selenium可以驱动浏览器完成各种操作,比如模拟点击等。要想操作一个元素,首先应该识别这个元素。人有各种的特征(属性),我们可以通过其特征找到人,如通过身份证号、姓名、家庭住址。同理,一个元素会有各种的特征(属性),我们可以通过这个属性找到这对象。目录一、元素的概念(一)什么是元素?(二)查看元素信息二、元素定位方法(一)根据id定位(二)根据name定位(三)通过class name定位(四)根据tag定位(五)通过link text定位(六)通过parti
Selenium可以驱动浏览器完成各种操作,比如模拟点击等。要想操作一个元素,首先应该识别这个元素。人有各种的特征(属性),我们可以通过其特征找到人,如通过身份证号、姓名、家庭住址。同理,一个元素会有各种的特征(属性),我们可以通过这个属性找到这对象。
一、元素的概念
(一)什么是元素?
(二)查看元素信息

二、元素定位方法
(一)根据id定位

(二)根据name定位
(三)通过class name定位
(四)根据tag定位

(五)通过link text定位

(六)通过partial link text定位
(七)根据XPath定位
2.7.1绝对路径
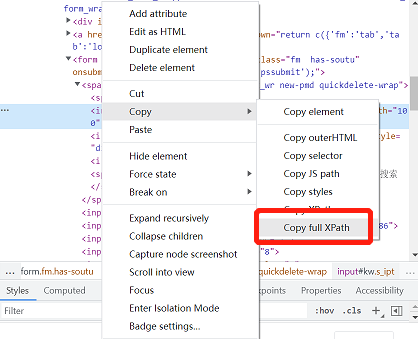
2.7.2相对路径
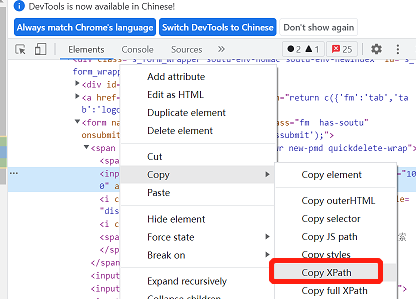
(八)通过css selector定位
2.8.1 id选择器
2.8.2 class选择器
2.8.3 标签选择器
2.8.4 属性选择器
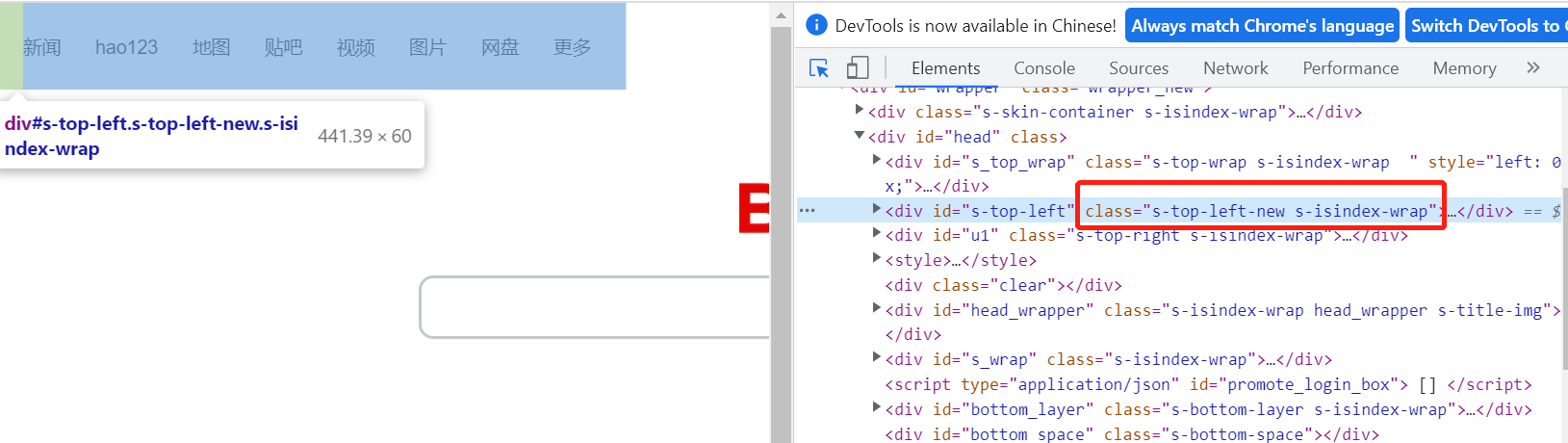
2.8.5 直接在浏览器复制
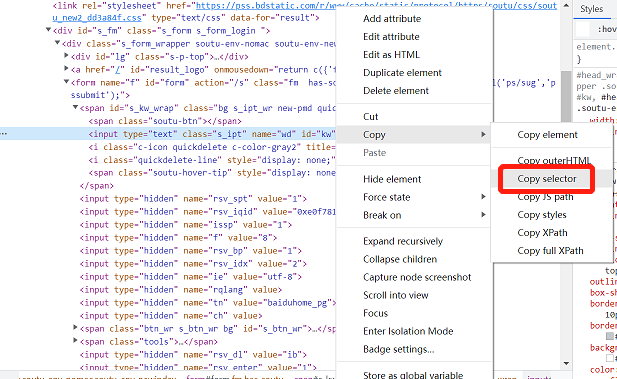
(九)定位方法的使用
2.9.1 定位方式选择
2.9.2 find_element和find_elements方法
三、元素定位的另一种写法
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。