numpy与pandas各种功能及其对比(超全)_numpy和pandas的区别_阿丢是丢心心的博客-CSDN博客
一、简介
1、numpy的核心数据结构是ndarray
支持任意维数的数组,但要求单个数组内所有数据是同质的,即类型必须相同;pandas是基于numpy数组构建的,它的核心数据结构是series和dataframe,仅支持一维和二维数据,但数据内部可以是异构数据,仅要求同列数据类型一致即可。
numpy的数据结构仅支持数字索引,而pandas数据结构则同时支持数字索引和标签索引。
2、numpy用于数值计算,pandas主要用于数据处理与分析。
numpy虽然也支持字符串等其他数据类型,但仍然主要是用于数值计算,尤其是内部集成了大量矩阵计算模块,例如基本的矩阵运算、线性代数、fft、生成随机数等,支持灵活的广播机制。
pandas主要用于数据处理与分析,支持包括数据读写、数值计算、数据处理、数据分析和数据可视化全套流程操作。
二、基础属性
1.数据结构
在开始创建数据之前,再说明一下两种方法创建的数据结构形式
numpy:是通用的同构数据多维容器,其中的所有元素必须是相同类型的
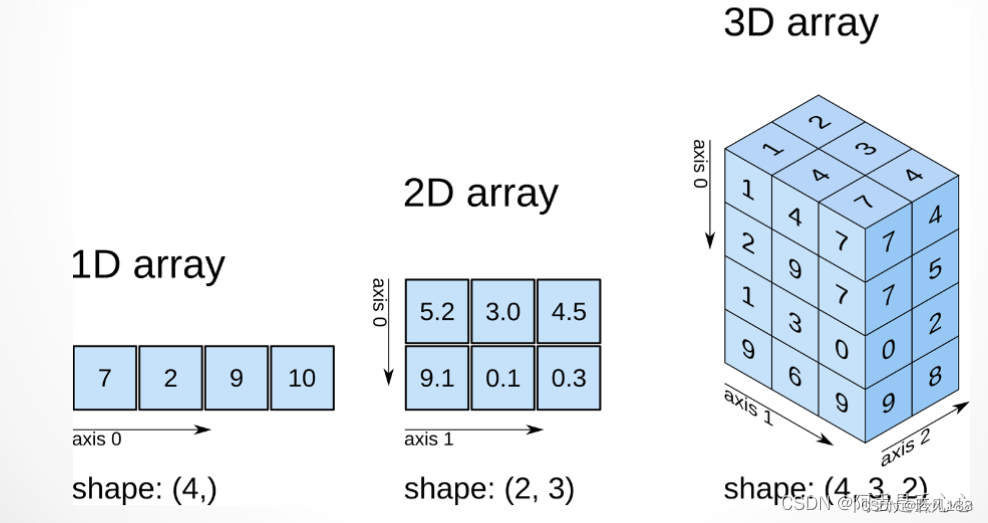
pandas:一维数据结构为series,多维是dataframe

其中:
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,索引在左边,值在右边。

DataFrame是一个表格型的数据结构,既有行索引(index)也有列索引(columns),它可以被看做由Series组成的字典(共用同一个索引)。
2、对象常用属性
(1)ndarray
data. shape 数组的形状
data.ndim 维度的数量
data.size 数组的总大小
data.dtype 数组中的数据类型(int8, uint8, float32, complex64, bool, object, string.
data.astype 数据类型转换
(2)Series
obj.values 获取数组的值
obj.index 获取数组的索引对象
obj.name 获取数组的名称
obj.index.name 获取索引的名称
(3) DateFrame
frame.index 获取表格的行索引
frame.columns 获取表格的列索引
frame.values 获取表格中的数据
frame.col_name 获取指定列的数据
frame.index.name 获取索引的名称
frame.columns.name 获取列的名称
三、 一维数据(numpy和pandas.Series对比)
1、新增Create
#列表转化
list1 = [4, 7, -5, 3]
arr1 = np.array(list1)
s1 = pd.Series(list1)
arr1
s1
输出:
array([ 4, 7, -5, 3])
0 4
1 7
2 -5
3 3
dtype: int64
## 直接创建
arr2 = np.array([4, 7, -5, 3])
obj = Series([4, 7, -5, 3], dtype=np.int32)
obj2 = Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
arr2
obj
obj2
输出:
array([ 4, 7, -5, 3])
0 4
1 7
2 -5
3 3
dtype: int32
d 4
b 7
a -5
c 3
dtype: int64
#字典转换
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = Series(sdata)
obj3
输出:
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = Series(sdata, index=states)
obj4
输出:
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64#创建连续数值数组
arr3 = np.arange(5)
s3 = pd.Series(np.arange(5))
s3_1 = pd.Series(range(5)) #输出与s3相同
#创建全为0的数组
arr4 = np.zeros(5)
s4 = pd.Series(0 ,index = ['a','b','c','d'])
s4_1 = pd.Series(np.zeros(5))
#创建随机数数组
arr5 = np.random.rand(5)
arr_1 = np.random.random_sample(size=5)
s5 = pd.Series(np.random.rand(5))2、查找Read
obj2
输出:
d 4
b 7
a -5
c 3
dtype: int64
obj2[['c', 'a', 'd']]
输出:
c 3
a -5
d 4
dtype: int64
obj2[1:3] # [1, 3)
输出:
b 7
a -5
dtype: int64
obj2['b':'c'] # []
输出:
b 7
a -5
c 3
dtype: int64
obj
输出:
0 4
1 7
2 -5
3 3
dtype: int32
obj[1:3]
输出:
1 7
2 -5
dtype: int32
obj.index
输出:
RangeIndex(start=0, stop=4, step=1)
obj2.index
输出:
Index(['d', 'b', 'a', 'c'], dtype='object')
obj2.values
输出:
array([ 4, 7, -5, 3])
obj[1], obj2['a']
输出:
(7, -5)
3、修改update
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
obj2['d'] = 6
obj2
输出为:
d 6
b 7
a -5
c 3
dtype: int64
obj2[['a', 'b', 'c']] = [1, 2, 3]
obj2
输出为:
d 6
b 2
a 1
c 3
dtype: int64
obj4
输出为:
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
dtype: float64
obj4.name = 'population'
obj4.index.name = 'state'
obj4
输出为:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
obj
输出为:
0 4
1 7
2 -5
3 3
dtype: int32
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
obj
输出为:
Bob 4
Steve 7
Jeff -5
Ryan 3
dtype: int32
4、删除 Delete
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
del obj2['a']
输出为:
此次无输出
obj2.drop('c') # drop操作返回新的对象,原对象不变
输出为:
d 4
b 7
dtype: int64
obj2
输出为:
d 4
b 7
c 3
dtype: int64
obj2.drop(['b', 'd'])
输出为:
c 3
dtype: int64
obj2
输出为:
d 4
b 7
c 3
dtype: int64
5、运算
5.1、标量运算
不同大小的数组之间的算术运算的执行方式叫做广播(broadcasting)
广播中较小数组的‘广播维’必须为1, 广播会在缺失和(或)长度为1的维度上进行。较小的数组会在较大的数组上沿着该维度广播,并在经过的地方做相应的算术运算。最简单的广播就是标量值跟数组合并的运算。
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
obj2 * 2
输出为:
d 8
b 14
a -10
c 6
dtype: int64
obj2 > 4
输出为:
d False
b True
a False
c False
dtype: bool
obj2 / 2
输出为:
d 2.0
b 3.5
a -2.5
c 1.5
dtype: float64
obj2[obj2 > 4]
输出为:
b 7
dtype: int64
'b' in obj2
输出为:
True
'e' in obj2
输出为:
False
5.2、向量运算
# 根据运算的索引标签自动对齐数据,对不同索引的对象进行算术运算。
obj3
输出为:
Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
obj4
输出为:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
obj3 + obj4
输出为:
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
obj3 * obj4
输出为:
California NaN
Ohio 1.225000e+09
Oregon 2.560000e+08
Texas 5.041000e+09
Utah NaN
dtype: float64
obj3 > obj4 # 会报错,无法匹配
ser1 = pd.Series(np.arange(1, 6), index = list('abcde'))
ser2 = pd.Series(np.arange(2, 7), index = list('abcde'))
ser1 > ser2
输出为:
a False
b False
c False
d False
e False
dtype: bool
5.3、函数运算
(1)通用函数
通用函数(ufunc): 一种对ndarray中的数据执行元素级运算的函数。对pandas中的Series和DataFrame也适用。
一元ufunc: abs, sqrt, square, exp, log, sign, isnan, ceil, floor, rint, modf, isfinit, isinf, cos, cosh, sin, sinh, tan, tanh,….
二元ufunc:add, substract, multiply, divide, floor_divide, power, maximum, minimum, mod, copysign, greater, greater_equal, less, less_equal, equal, not_equal, logical_and, logical_or
(2)numpy
sum, mean, std, var, min, max, argmin, argmax, cumsum, cumprod
arr = np.random.randn(3,4)
print(arr)
print(arr.mean())
print(arr.sum())
print(arr.mean(axis = 1))
print(arr.sum(axis = 0))
输出为:
[[ 0.32032819 1.26761265 -2.39961199 0.97646207]
[-0.23177368 -0.31558693 -0.82149254 -1.63021035]
[-0.84288386 -0.01973655 -0.96049732 1.73198541]]
-0.2437837416655606
-2.9254048999867273
[ 0.04119773 -0.74976587 -0.02278308]
[-0.75432935 0.93228917 -4.18160185 1.07823713](3)pandas
pandas对象拥有的数学和统计方法:count, describe, min, max, argmin, argmax, idxmin, idxmax, quantile, sum, mean, median, mad, var, std, skew, kurt, cumsum, cummin, cummax, cumprod, diff, pct_change
obj2
输出为:
d 4
b 7
a -5
c 3
dtype: int64
np.exp(obj2)
输出为:
d 403.428793
b 7.389056
c 20.085537
dtype: float64
obj4
输出为:
state
California NaN
Ohio 35000.0
Oregon 16000.0
Texas 71000.0
Name: population, dtype: float64
pd.isnull(obj4)
输出为:
state
California True
Ohio False
Oregon False
Texas False
Name: population, dtype: bool
pd.notnull(obj4)
输出为:
state
California False
Ohio True
Oregon True
Texas True
Name: population, dtype: bool
obj4.isnull()
输出为:
state
California True
Ohio False
Oregon False
Texas False
Name: population, dtype: bool
obj4.notnull()
输出为:
state
California False
Ohio True
Oregon True
Texas True
Name: population, dtype: bool
#顺便对比一下numpy
arr = np.array([[1, 2, 3, 4, 5], [6, 4, 3, 2, 1]])
print(arr)
print(arr.argmax(axis=0))
输出为:
[[1 2 3 4 5]
[6 4 3 2 1]]
[1 1 0 0 0]
ser = pd.Series([1,3,2,5,7])
print(ser)
print(ser.argmax)
输出为:
0 1
1 3
2 2
3 5
4 7
dtype: int64
<bound method IndexOpsMixin.argmax of 0 1
1 3
2 2
3 5
4 7
dtype: int64>
四、多维数据
1、新增Create
#外层字典的键作为列索引,dataframe自动加上行索引
data = {'one': [0, 1],
'two': [2, 3]}
s3 = pd.DataFrame(data)
输出为:
one two
0 0 2
1 1 3
#对于嵌套字典,外层字典作为列索引,内层键作为行索引
data = {'one': {'a':0, 'b':1},
'two': {'a':2, 'b':3}}
s4 = pd.DataFrame(data)
输出为:
one two
a 0 2
b 1 3#自定义列和索引标签
s4 = pd.DataFrame(data, columns=['one', 'two', 'three', 'four'])
输出为:
one two three four
a 0 2 NaN NaN
b 1 3 NaN NaN
s5 = pd.DataFrame(data, columns=['three', 'two', 'one', 'four'])
输出为:
three two one four
a NaN 2 0 NaN
b NaN 3 1 NaNdata = {
'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9]
}
frame = DataFrame(data)
frame
输出为:
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
frame2 = DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five'])
frame2
输出为:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
obj = Series([4, 7, -5, 3, 10], index=['d', 'b', 'a', 'c', 'e'])
obj2 = Series([8, 1, 2, -21], index=['d', 'b', 'a', 'c'])
DataFrame({'col1': obj, 'col2': obj2})
输出为:
col1 col2
a -5 2.0
b 7 1.0
c 3 -21.0
d 4 8.0
e 10 NaN
frame3 = DataFrame({'year': {'one': 2000, 'two': 2001, 'three': 2002, 'four': 2001, 'five': 2002},
'state': {'one': 'Ohio', 'two': 'Ohio', 'three': 'Ohio', 'four': 'Nevada', 'five': 'Nevada'},
'pop': {'one': 1.5, 'two': 1.7, 'three': 3.6, 'four': 2.4, 'five': 2.9}})
输出为:
year state pop
one 2000 Ohio 1.5
two 2001 Ohio 1.7
three 2002 Ohio 3.6
four 2001 Nevada 2.4
five 2002 Nevada 2.9
原文地址:https://blog.csdn.net/u011937496/article/details/134487410
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_43840.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!