得益于一种名为潜在一致性模型(LCM)的新技术,文本转换成图像的AI即将迎来重大飞跃。潜在扩散模型(LDM)等传统方法在使用文本提示生成详细、创造性的图像方面令人印象深刻,然而它们的致命弱点是速度慢。使用LDM生成单单一个图像可能需要数百个步骤,这对于许多实际应用来说实在太慢了。
LCM通过大幅减少生成图像所需的步骤数量来改变游戏规则。LDM需要数百步才能费劲地生成图像,LCM只需1到4步就能获得质量相似的结果。这种效率是通过将预训练的LDM提炼成更精简的形式来实现的,所需的算力和时间大大减少。我们将剖析一篇介绍LDM模型的近期论文,看看它是如何工作的。
本文还介绍了一种名为LCM-LoRA的创新,这是一种通用的Stable-Diffusion加速模块。该模块可以插入到各种Stable–Diffusion微调模型,无需任何额外的训练。它是一种普遍适用的工具,可以加速各种图像生成任务,使其成为利用AI创建图像的潜在利器。我们还将剖析论文的这个部分。
1、高效训练LCM
神经网络领域的一大挑战是需要绝对庞大的算力,尤其在训练它们以解决复杂方程时。这篇论文背后的团队用一种名为提炼的巧妙方法正面解决了这个问题。
研究团队是这么做的:他们先使用一个文本与图像配对的数据集训练一个标准的潜在扩散模型(LDM)。一旦这个LDM启动并运行起来,他们把它用作一种导师,以生成新的训练数据。这些新数据随后被用于训练潜在一致性模型(LCM))。这里最吸引人的部分是LCM学会从LDM的能力中学习,不需要使用庞大数据集从头开始训练。
真正重要的是这个过程的效率。研究人员仅使用单个GPU就在大约32小时内完成了高质量LCM的训练。这很重要,因为它比以前的方法快得多、实用得多。这意味着现在更多的人和项目都可以创建这种先进的模型,而不是只有享有超级计算资源的人才能创建。
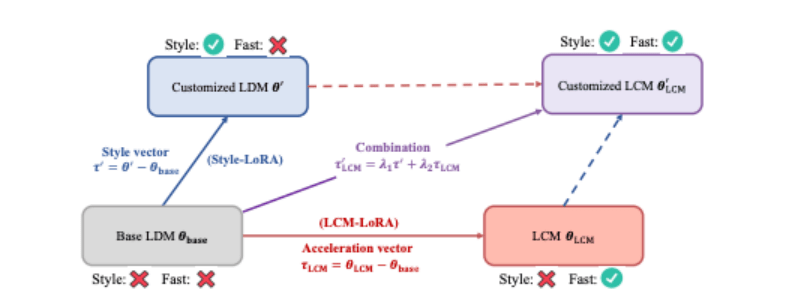 图1、LCM-L
图1、LCM-L通过将LoRA引入到LCM的提炼过程中,我们显著降低了提炼的内存开销,这使得我们可以用有限的资源训练更庞大的模型,比如SDXL和SSD-1B。更重要的是,通过LCM-LoRA训练获得的LoRA参数(“加速向量”)可以直接与通过针对特定样式的数据集进行微调获得的其他LoRA参数(“样式向量”)结合起来。无需任何训练,由加速向量和样式向量的线性组合获得的模型获得了以最少的采样步骤生成特定绘画样式的图像这种能力。
2、结果
该研究展示了基于潜在一致性模型(LCM)利用AI生成图像方面的重大进展。LCM擅长仅用四个步骤就能创建高质量的512x512图像,与潜在扩散模型(LDM)等传统模型所需的数百个步骤相比有了显著改进。这些图像拥有清晰的细节和逼真的纹理,这个优点在下面的例子中尤为明显。

图2、论文声称:“使用从不同的预训练扩散模型中提取的潜在一致性模型生成的图像。我们使用LCM-LoRA-SD-V1.5生成512×512分辨率的图像,使用LCM-LoRA-SDXL和LCM-LoRA-SSD-1B生成1024×1024分辨率的图像。”
这些模型不仅可以轻松处理较小的图像,还擅长生成更庞大的1024x1024图像。它们展示了一种扩展到比以前大得多的神经网络模型的能力,展示了其适应能力。论文中的示例(比如LCM-LoRA-SD-V1.5和LCM-LoRA-SSD-1B版本的示例)阐明了该模型在各种数据集和实际场景中的广泛适用性。
3、局限性
LCM的当前版本存在几处局限性。最重要的是两个阶段的训练过程:首先训练LDM,然后用它来训练LCM。在未来的研究中,可能会探索一种更直接的LDM训练方法,因而可能不需要LDM。论文主要讨论无条件图像生成,条件生成任务(比如文本到图像的合成)可能需要做更多的工作。
4、主要的启示
潜在一致性模型在快速生成高质量的图像方面迈出了一大步。这些模型只需1到4步就能生成与较慢的LDM相媲美的结果,这可能会彻底改变文本到图像模型的实际应用。虽然目前存在一些局限性,特别是在训练过程和生成任务的范围方面,但LCM标志着在基于神经网络的实用图像生成方面取得了重大进展。提供的示例强调了这些模型具有的潜力。
5、LCM-LoRA作为通用加速模块
正如我在引言中提到,该论文分为两部分。论文的第二部分讨论了LCM-LoRA,这种技术允许使用少得多的内存对预训练模型进行微调,使其更高效。
这里的关键创新是将LoRA参数集成到LCM中,从而生成结合两者优点的混合模型。这种集成对于创建特定样式的图像或响应特定任务特别有用。如果选择和组合不同的LoRA参数集,每个参数集又都针对独特的样式进行微调,研究人员创建了一个多功能模型,可以用最少的步骤生成图像,不需要额外的训练。
他们在研究中通过将针对特定绘画样式进行微调的LoRA参数与LCM-LoRA参数相结合的例子来证明这一点。这种组合允许在不同的采样步骤(比如2步、4步、8步、16步和32步)创建样式迥异的1024 × 1024分辨率图像。它们表明,这些组合的参数无需进一步训练即可生成高质量图像,强调了这种模型的效率和通用性。
这里值得关注的一个地方是使用所谓的“加速向量”(τLCM)和“样式向量”(τ),两者使用特定的数学公式(λ1和λ2是这些公式中的可调整因子)组合在一起。这种组合产生的模型可以快速地生成定制样式的图像。
论文中的图3(如下所示)通过展示特定样式LoRA参数与LCM-LoRA参数结合的结果,表明了这种方法的有效性。这证明了该模型能够快速高效地生成样式不同的图像。
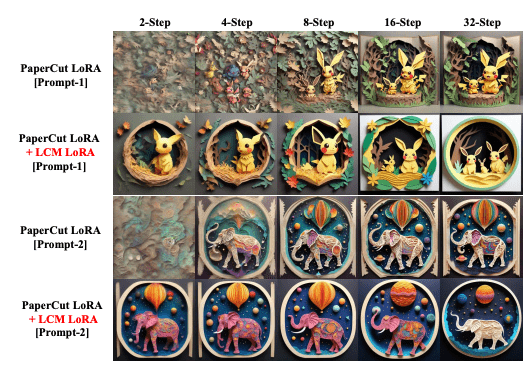 图3
图3
总之,本文的这部分强调了LCM-LoRA模型如何代表一种通用的、高效的解决方案,可用于快速生成高质量的特定样式的图像,只需使用极少的计算资源。这项技术的实际应用很广泛,有望彻底改变从数字艺术到自动化内容创作等各个领域生成图像的方式。
6、结论
我们研究了潜在一致性模型(LCM),这是一种显著加快从文本生成图像过程的新方法。不像传统的潜在扩散模型(LDM)需要数百个步骤来创建一个图像,LCM只需1到4个步骤就可以生成质量相似的图像。这种效率的大幅提升是通过提炼方法实现的,即使用预训练的LDM来训练LCM,因而不需要大量计算。
此外,我们还探索了LCM-LoRA,这是一种使用低秩自适应(LoRA)对预训练模型进行微调的增强技术,降低了内存需求。这种集成允许以最少的计算步骤创建特定样式的图像,而不需要额外的训练。
着重强调的关键结果包括LCM仅用几个步骤就能创建高质量的512x512和1024x1024图像,而LDM却需要数百个步骤。然而,目前存在的局限性是LDM依赖两步训练过程,因此你仍需要LDM开始入手!未来的研究可能会简化这个过程。
LCM特别是在提议的LCM-LoRA模型中与LoRA结合使用时,是一种非常巧妙的创新。它们提供了更快速、更高效地创建高质量图像这个优点,我认为它们在数字内容创建方面有着广泛的应用前景。
原文地址:https://blog.csdn.net/wangonik_l/article/details/134784016
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_44048.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!