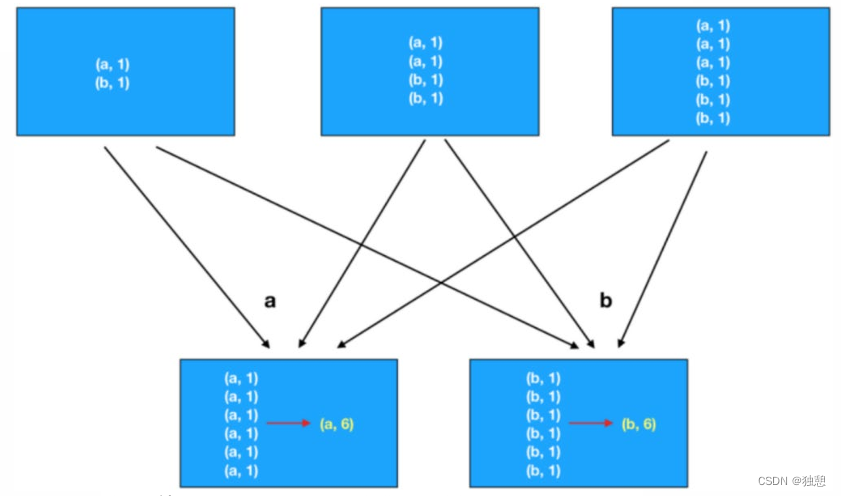
本文介绍: 简介map算子:map算子是将rdd中的数据一条一条传递给后面的函数,将函数的返回值构建成一个新的rdd。map算子是不会生成shuffle。后面的分区数等于map算子的分区数。//saprk代码的入口/*** 构建rdd的方法* 1.读取文件* 2.基于scala的集合构建rdd —- 用于测试*//*** map算子* 将rdd中的数据一条一条传递给后面的函数,将函数的返回值构建成一个新的rdd* map 不会产生shuffle,map之后的分区数等于map之前rdd的分区数。
Spark学习–spark算子介绍
1.基本概念
spark算子:为了提供方便的数据处理和计算,spark提供了一系列的算子来进行数据处理。
一般算子分为
action(执行算子)算子
Transformation(懒执行)算子。
2.Transformation算子基本介绍
简介:transformation被称为懒执行算子,如果没有action算子,则代码是不会执行的,一般分为:
object Demo2Map {
def main(args: Array[String]): Unit = {
//saprk代码的入口
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("map")
val sc = new SparkContext(conf)
/**
* 构建rdd的方法
* 1.读取文件
* 2.基于scala的集合构建rdd ---- 用于测试
*
*/
val listRDD: RDD[Int]= sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9),2)
/**
* map算子
* 将rdd中的数据一条一条传递给后面的函数,将函数的返回值构建成一个新的rdd
* map 不会产生shuffle,map之后的分区数等于map之前rdd的分区数
*
*如果一个算子是一个新的rdd,那么这个算子就是转换算子。
*/
val mapRDD: RDD[Int] = listRDD.map{i => i * 2}
//一次遍历整个分区的数据,将每一个分区的数据传递给后面的函数,函数需要返回一个迭代器,再构建一个新的rdd。
val mapPartitionRDD: RDD[Int] = listRDD.mapPartitions {
case iter: Iterator[Int] =>
iter
}
val mapPartitionRDD2: RDD[Int] = listRDD.mapPartitions {
case iter: Iterator[Int] =>
val iterator: Iterator[Int] = iter.map(i => i * 2)
//最后一行作为返回值
iterator
}
mapPartitionRDD2.foreach(println)
mapPartitionRDD.foreach(println)
val mapPartitionsWithIndexRDD: RDD[Int] = listRDD.mapPartitionsWithIndex((index: Int, iter: Iterator[Int]) => {
println(s"mapPartitionsWithIndexRDD的分区为:$index")
iter
})
mapPartitionsWithIndexRDD.foreach(println)
}
}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo4Filter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("filter")
val sc = new SparkContext(conf)
val ListRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 0), 2)
/**
* filter: 对RDD中的数据进行过滤,通过返回true保留数据,函数返回false过滤数据
*
* filter: 转换算子,懒执行
*/
val filterRDD: RDD[Int] = ListRDD.filter(i => {
i % 2 == 1
})
filterRDD.foreach(println)
}
}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo5Flatmap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("filter")
val sc = new SparkContext(conf)
val listRDD: RDD[String] = sc.parallelize(List("java,spark,java","spark,scala,hadoop"))
/**
* 将rdd的数据一条一条传递给后面的函数,函数的返回值是一个集合,
* 最后将这个集合拆分出来,构建成新的rdd
*/
val wordsRDD: RDD[String] = listRDD.flatMap(line => {
val arr: Array[String] = line.split(",")
//返回值可以是一个数组,list,set map,必须是scala中的集合
arr.toList
})
wordsRDD.foreach(println)
}
}
package com.zjl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo6Sample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("Demo6Sample")
val sc = new SparkContext(conf)
val listRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 45, 6, 7, 8, 9, 0))
val studentRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\data\students.txt")
/**
* sample:抽样。
* withReplacement:是否放回。
* fraction:抽样比例。
*/
val sampleRDD: RDD[String] = {
studentRDD.sample(false, 0.1)
}
}
}
- groupByKey算子:按照key进行分组,必须是kv格式的才能用,将同一个key的value放在迭代器中。相对比groupBy,指定一个分组的罗列,返回的RDD的value包含所有的列。shuffle过程中需要传输的数据量groupByKey要多,性能差一点
package com.zjl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo8GroupByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = {
new SparkConf()
}
conf.setMaster("local")
.setAppName("groupByKey")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\spark\data\words.txt")
val wordsRDD: RDD[String] = linesRDD.flatMap(i => i.split(","))
val mapWordRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
/**
* 按照key进行分组,必须是kv格式的才能用,将同一个key的value放在迭代器中
*/
val groupByKeyRDD: RDD[(String, Iterable[Int])] = mapWordRDD.groupByKey()
groupByKeyRDD.map({
case(words:String, ints:Iterable[Int]) =>
ints.sum
})
groupByKeyRDD.foreach(println)
/**
* groupBy:指定一个分组的罗列,返回的RDD的value包含所有的列
* shuffle过程中需要传输的数据量groupByKey要多,性能差一点
*/
val groupByRDD: RDD[(String, Iterable[(String, Int)])] = mapWordRDD.groupBy(kv => kv._1)
groupByRDD.foreach(println)
}
}
package com.zjl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo9ReduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("reduceByKey")
.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\spark\data\words.txt")
val wordsRDD: RDD[String] = linesRDD.flatMap(i => i.split(","))
val mapRDD: RDD[(String, Int)] = wordsRDD.map(i => (i, 1))
/**
* reduceByKey:按照key进行聚合计算,会在map端进行预聚合
* 只能做简单的聚合计算
*/
//统计单词数量
val reducrByKeyRDD: RDD[(String, Int)] = mapRDD.reduceByKey((x: Int, y: Int) => x + y)
reducrByKeyRDD.foreach(println)
}
}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo10Union {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("union")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9))
val rdd2: RDD[Int] = sc.parallelize(List( 4, 5, 6, 7, 8, 9,10))
/**
* union:合并两个rdd,两个rdd的数据类型要一致
* union只是代码层面的合并,底层没有合并
* union不会产生shuffle
*/
val unionRDD: RDD[Int] = rdd1.union(rdd2)
unionRDD.foreach(println)
/**
* distinctRDD去重,会产生shuffle
* distinct:会先在map端局部去重,再到reduce端全局去重
*/
val distinctRDD: RDD[Int] = unionRDD.distinct()
distinctRDD.foreach(println)
/**
* 所有会产生shuffle的算子都可以指定分区数。反过来也成立。
*/
/**
* intersection:取两个rdd的交集
*/
val interRDD: RDD[Int] = rdd1.intersection(rdd2)
interRDD.foreach(println)
}
}
- join算子:inner join:通过rdd的key进行关联,必须是kv格式的rdd;left join:以左表为主,如果右表没有数据,就会补一个null;right join和left join相反;full join:两边都可能没有关联上,如果是没关联上,补null
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo11Join {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("join")
val sc: SparkContext = new SparkContext(conf)
val nameRDD: RDD[(String, String)] = sc.makeRDD(List(("001", "张三"), ("002", "李四"), ("003", "王五")))
val ageRDD: RDD[(String, String)] = sc.makeRDD(List(("001", "23"), ("002", "35"), ("004", "19")))
/**
* inner join:通过rdd的key进行关联,必须是kv格式的rdd
*/
// //关联之后处理数据方法1--下划线方法
val innerJoinRDD: RDD[(String, (String, String))] = nameRDD.join(ageRDD)
// innerJoinRDD.map(i=>{
// val id: String = i._1
// val name: String = i._2._1
// val age: String = i._2._1
// })
//关联之后处理数据2--模式匹配
val rdd1: RDD[(String, String, Int)] = innerJoinRDD.map(i => {
case (id: String, (name: String, age: String)) =>
(id, name, age)
})
rdd1.foreach(println)
/**
* left join:以左表为主,如果右表没有数据,就会补一个null
* 数据中右表没有003,所有会补一个null
* Option[String]:没有值就是None
* right join:和left join相反
*/
val leftRDD: RDD[(String, (String, Option[Int]))] = nameRDD.leftOuterJoin(ageRDD)
leftRDD.foreach(println)
//整理数据
val rdd2: RDD[(String, String, Int)] = leftRDD.map({
//匹配关联成功的数据
case (id: String, (name: String, Some(age))) =>
(id, name, age)
//匹配未关联成功的数据
case (id: String, (name: String, None)) =>
(id, name, 0)
})
rdd2.foreach(println)
/**
* full join:两边都可能没有关联上,如果是没关联上,补null
*/
val fullRDD: RDD[(String, (Option[String], Option[Int]))] = nameRDD.fullOuterJoin(ageRDD)
//整理数据
val rdd3: RDD[(String, String, Int)] = fullRDD.map {
case (id: String, (Some(name), Some(age))) =>
(id, name, age)
case (id: String, (None, Some(age))) =>
(id, 0, age)
case (id: String, (Some(name), None)) =>
(id, name, 0)
case (id: String, (None, None)) =>
(id, 0, 0)
}
}
}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo12MapValues {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("mapValues")
val sc: SparkContext = new SparkContext()
//使用map
val ageRDD: RDD[(String, Int)] = sc.makeRDD(List(("001", 23), ("002", 35), ("004", 19)))
val linesRDD: RDD[(String, Int)] = ageRDD.map {
case (id: String, age: Int) =>
(id, age + 1)
}
/**
*mapValue:只对value进行处理,key不变
*/
//使用mapValue
val mapValuesRDD: RDD[(String, Int)] = ageRDD.mapValues(v => v + 1)
}
}
package com.zjl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo13Sort {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("sort")
val sc: SparkContext = new SparkContext(conf)
val studentsRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\data\students.txt")
/**
* sortBy:指定一个排序的列,默认是升序
* ascending:控制排序方式
*/
val sortByRDD: RDD[String] = studentsRDD.sortBy(student => {
val age: Int = student.split(",")(2).toInt
age
},false)
val ageRDD: RDD[(String, String)] = sc.makeRDD(List(("001", "23"), ("002", "35"), ("004", "19")))
val dataRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6))
val kvRDD: RDD[(Int, Int)] = dataRDD.map(i => (i, 1))
kvRDD.foreach(println)
/**
* 通过key排序,默认升序
*/
val sortByKeyRDD: RDD[(Int, Int)] = kvRDD.sortByKey()
sortByKeyRDD.foreach(println)
}
}
- .AGG算子
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo14Agg {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("Agg")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\spark\data\words.txt")
val wordsRDD: RDD[String] = linesRDD.flatMap(i => i.split(","))
val mapRDD: RDD[(String, Int)] = wordsRDD.map(i => (i, 1))
/**
* reduceByKey:在map端进行预聚合,聚合函数会应用在map端和reduce端(聚合函数会应用在分区内的聚合和分区间的聚合)
*/
val reduceByKeyRDD: RDD[(String, Int)] = mapRDD.reduceByKey((x, y) => x + y)
val aggRDD: RDD[(String, Int)] = mapRDD.aggregateByKey(0)( //初始值
(u: Int, i: Int) => u + i, //分区键的聚合函数(map端的聚合函数)
(u1: Int, u2: Int) => u1 + u2 //分区间的聚合(reduce的聚合函数)
)
aggRDD.foreach(println)
}
}
package com.zjl
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo15AggAvgAge {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("Agg")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\spark\data\students.txt")
/**
* 计算班级的平均年龄
*/
//val studentsRDD: RDD[String] = linesRDD.flatMap(i => i.split(","))
val classAndAge: RDD[(String,Double)] = linesRDD.map(student => {
val split: Array[String] = student.split(",")
( split(4),split(2).toDouble)
})
classAndAge.foreach(println)
/**
* 使用groupbykey
*/
val groupByKeyRDD: RDD[(String, Iterable[Double])] = classAndAge.groupByKey()
val avgAgeRDD: RDD[(String,Double)] = groupByKeyRDD.map({
case (clazz: String, age: Iterable[Double]) =>
val avgAge: Double = age.sum / age.size
(clazz, avgAge)
})
/**
* 大数据计算中,最耗时间的就是shuffle,shuffle过程中数据是落地到磁盘中的。
* aggregateByKey:会在map端做预聚合,性能高
* 1.初始值可以有多个
* 2.map端的聚合函数
* 3.reduce端的聚合函数
*/
val avgAge: RDD[(String, (Double, Int))] = classAndAge.aggregateByKey((0.0, 0))(
(u:(Double,Int), age:Double) => (u._1 + age, u._2 + 1),//map端的聚合函数
(u1:(Double,Int), u2:(Double,Int)) => (u1._1 + u2._1, u1._2 + u2._2)//reduce端的聚合函数
)
avgAge.foreach(println)
//计算平均年龄
val avgAgeMapRDD: RDD[(String, Double)] = avgAge.map({
case (clazz: String, (totalAge: Double, sumPerpon: Int)) =>
(clazz, totalAge / sumPerpon)
})
avgAgeMapRDD.foreach(println)
while(true){
}
}
}
- cartesian算子:笛卡尔积,很少使用。
package com.zjl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo16Cartesian {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("Agg")
val sc: SparkContext = new SparkContext(conf)
val nameRDD: RDD[(String, String)] = sc.makeRDD(List(("001", "张三"), ("002", "李四"), ("003", "王五")))
val ageRDD: RDD[(String, String)] = sc.makeRDD(List(("001", "23"), ("002", "35"), ("004", "19")))
/**
* 笛卡尔积
*/
val cartesianRDD: RDD[((String, String), (String, String))] = nameRDD.cartesian(ageRDD)
}
}
package com.zjl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo17Reduce {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("Agg")
val sc: SparkContext = new SparkContext(conf)
val LinesRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 0))
/**
* sum:求和,只能用于int或者double或者null类型的求和,action算子
*/
val sumRDD: Double = LinesRDD.sum()
/**
* reduce:全局聚合,action算子
* reduceByKey:通过key进行聚合
*/
val reducrRDD: Int = LinesRDD.reduce((x, y) => (x + y))
}
}
package com.zjl
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo18Take {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("Agg")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\spark\data\words.txt")
/**
* take:取top,是一个action算子
*/
val top100: Array[String] = linesRDD.take(100)
//获取第一条数据
val first: String = linesRDD.first()
}
}
package com.zjl
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo19Student1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
.setAppName("Agg")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\spark\data\score.txt")
/**
* 统计总分大于年级平均分的学生
*/
//1、计算学生的总分
val total: RDD[(String, Double)] = linesRDD.map(student => {
val splitRDD: Array[String] = student.split(",")
(splitRDD(0), splitRDD(2).toDouble)
})
total.foreach(println)
val totalScore: RDD[(String, Double)] = total.reduceByKey((x, y) => (x + y))
totalScore.foreach(println)
val totalAllRDD: RDD[Double] = totalScore.map(kv => kv._2)
val avgScore: Double = totalAllRDD.sum() / totalAllRDD.count()
//取出总分大于平均分
val endRDD: RDD[(String, Double)] = totalScore.filter {
case (id: String, score: Double) =>
score > avgScore
}
}
}
3.action算子基本介绍
action算子:在Spark中,action 算子是一类触发 Spark 作业执行的操作。action 算子会导致计算结果被返回到驱
动程序,或者将计算结果保存到外部存储系统。与 transformation 算子不同,action 算子会触发 Spark 作业的执
行,而不仅仅是定义计算逻辑。
object Demo7Action {
//spark代码的入口
def main(args: Array[String]): Unit = {
/**
* spark任务的层级关系:
* application ---> job ---> stages --->task
*/
val conf: SparkConf = {
new SparkConf()
}
conf.setMaster("local")
.setAppName("action")
val sc: SparkContext = new SparkContext(conf)
/**
* action 算子 --触发任务执行,每一个action算子都会触发一个job任务
* 1、foreach:遍历rdd
* 2、saveAsTextFile:保存数据
* 3、count:统计rdd的行数
* 4、sum:求和
* 5、collect:将rdd转换成scala的集合
*/
val studentRDD: RDD[String] = sc.textFile("D:\data\data\ideadata\idea-project\big_data\spark\data\students.txt")
//一次遍历一个数据
studentRDD.foreach(println)
//一次遍历一个分区
studentRDD.foreachPartition((iter:Iterator[String]) => println(iter.toList))
//保存数据
/**
* saveAsTextFile:将数据保存到hdfs中
* 1、输出的目录不能存在
* 2、rdd一个分区对应一个文件
*/
studentRDD.saveAsTextFile("D:\data\data\ideadata\idea-project\big_data\spark\data")
//统计行数
val count: Long = studentRDD.count()
println(s"studentRDD的行数:$count")
//将rdd的数据拉取到内存中,如果数据量很大会出现内存溢出
val studentArr: Array[String] = studentRDD.collect()
}
}
原文地址:https://blog.csdn.net/Kayleigh520/article/details/134559799
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_4427.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。