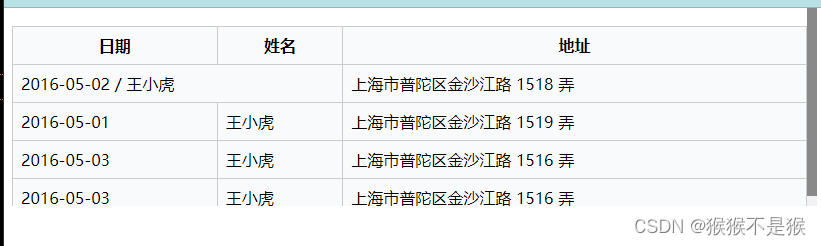
本文介绍: img2table是一个基于OpenCV 图像处理的用于 PDF 和图像的表识别和提取 Python库。由于其设计基于神经网络的解决方案,提供了一种实用且更轻便的替代方案,尤其是在 CPU 上使用时。该库的特点:识别图像和PDF文件中的表格,包括在表格单元级别的边界框。通过支持OCR服务/工具(Tesseract、PaddleOCR、AWS Textract、Google Vision和Azure OCR目前支持)来提取表格内容。处理复杂的表格结构,如合并单元格。实现纠正图像的倾斜和旋转的方法。
img2table是一个基于OpenCV 图像处理的用于 PDF 和图像的表识别和提取 Python库。由于其设计基于神经网络的解决方案,提供了一种实用且更轻便的替代方案,尤其是在 CPU 上使用时。
该库的特点:
支持的文件格式
图像
支持的图像格式,不支持多页图像。
PDF格式
一、安装
二、使用
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[office] excel怎么在表格中画斜线 #经验分享#知识分享#媒体](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)