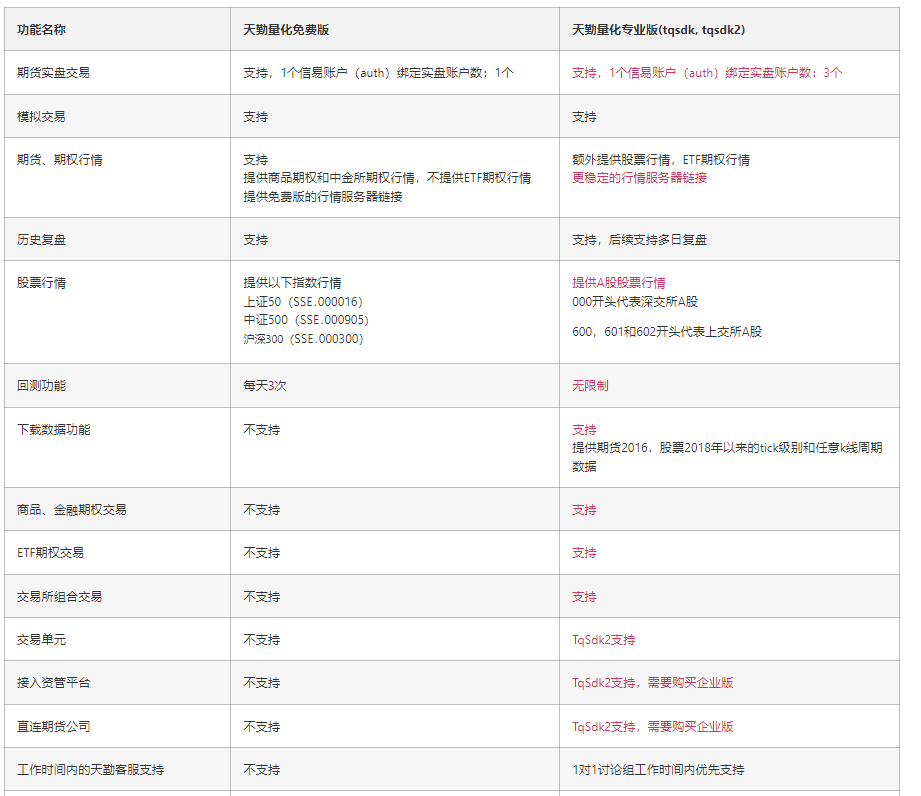
1. 天勤量化不同版本区别
为了获取所有期货分钟数据和股票日线数据,需要提前申请专业版账号,值得高兴的是每个账号有15天的试用期,官网地址。但是股票和期货数据只能获取2018年之后的,期货合约代码最久的是20年8月到期。
2. 多进程获取期货分钟数据和股票日线数据
import logging
import os.path
from datetime import datetime, timedelta
from typing import Union
import ray
import pandas as pd
from pandas import Series, Timestamp, DataFrame
from tqsdk import TqApi, TqAuth
SETTING = {"user": "your_user", "password": "your_password",
"FUTURE": "future_symbols.csv", "STOCK": "stock_symbols.csv"}
@ray.remote
class TraceData:
def __init__(self, account, password):
self.symbol = None
self.klines_flag = False
self.exchange = None
self.logger = None
self.api = TqApi(auth=TqAuth(account, password))
self.root_dir = os.path.abspath(os.path.curdir)
self.init()
def init(self, exchange: str = None, symbol: str = None) -> None:
# 订阅数据需要的字段
self.exchange = exchange
self.symbol = symbol
# 检查klines和log目录是否创建
klines_dir = os.path.join(self.root_dir, "klines")
if not os.path.exists(klines_dir):
os.mkdir(klines_dir)
log_dir = os.path.join(self.root_dir, "log")
if not os.path.exists(log_dir):
os.mkdir(log_dir)
# 准备日志记录工具
self.logger = logging.getLogger("loging")
self.logger.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(asctime)s [%(levelname)s] %(message)s")
logfile_path = os.path.join(os.path.join(self.root_dir, "log"),
(datetime.now().date().strftime('%Y%m%d')))
file_handler = logging.FileHandler(logfile_path, mode="a",
encoding="utf8")
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
self.logger.addHandler(file_handler)
# 获取所有交易标的合约
def get_all_symbols(self, ins_class, expired=False) -> list:
"""
ins_class (str): [可选] 合约类型
* FUTURE: 期货
* STOCK: 股票
"""
exchanges = []
all_symbols = []
if ins_class == "FUTURE":
exchanges = ["SHFE", "CFFEX", "DCE", "CZCE", "INE"]
elif ins_class == "STOCK":
exchanges = ["SSE", "SZSE"]
for exchange in exchanges:
symbol = self.api.query_quotes(ins_class=ins_class,
exchange_id=exchange,
expired=expired)
all_symbols.extend(symbol)
df: Series = pd.Series(all_symbols,
index=[i + 1 for i in range(len(all_symbols))])
filename = SETTING.get(ins_class)
filepath = os.path.join(self.root_dir, filename)
if not os.path.exists(filepath):
df.to_csv(filepath, index=True, header=False)
return all_symbols
def save_klines(self, symbols: list):
"""下载指定标的k线数据"""
klines_dir_path = os.path.join(os.path.join(self.root_dir, "klines"),
datetime.now().date().strftime('%Y%m%d'))
if not os.path.exists(klines_dir_path):
os.mkdir(klines_dir_path)
for symbol in symbols:
klines_file_path = os.path.join(klines_dir_path, f"{symbol}.csv")
if os.path.exists(klines_file_path):
continue
klines = pd.DataFrame()
try:
klines = self.api.get_kline_serial(symbol, 60, 600)
except Exception as e:
self.logger.log(logging.WARNING, f"{e}")
print(f"{datetime.now()}:{e}")
if not klines.empty:
klines_copy = klines.copy(deep=True)
klines_copy["new_datetime"]: datetime = klines_copy[
"datetime"].apply(
lambda x: Timestamp(x).to_pydatetime() + timedelta(hours=8))
local_time = datetime.now()
klines_copy = klines_copy[
(klines_copy.new_datetime >= datetime(local_time.year,
local_time.month,
local_time.day - 1,
15,
30)) & (
klines_copy.new_datetime < datetime(local_time.year,
local_time.month,
local_time.day,
15,
30))]
klines_copy["date"] = klines_copy["new_datetime"].apply(
lambda x: x.date().strftime("%Y%m%d"))
klines_copy["time"] = klines_copy["new_datetime"].apply(
lambda x: x.time().strftime("%H:%M:%S"))
klines_copy = klines_copy.drop(["new_datetime", "datetime"],
axis=1)
klines_copy.to_csv(klines_file_path, index=False)
# 输出日志
self.logger.log(logging.INFO, f"{symbol}.csv文件创建完成!")
print(f"{datetime.now()},{symbol}.csv文件创建完成!")
else:
# 输出日志
self.logger.log(logging.WARNING, f"{symbol}.csv文件为空!")
print(f"{datetime.now()},{symbol}.csv文件为空!")
def save_bars(self, symbols: list, duration_seconds: int, start: datetime,
end: datetime,
adj_type: Union[str, None] = None):
"""下载指定标的k线数据
adj_type (str/None): [可选]指定复权类型,默认为 None。adj_type 参数只对股票和基金类型合约有效。
"F" 表示前复权;"B" 表示后复权;None 表示不做处理。
"""
if adj_type == "F":
klines_dir_path = os.path.join(self.root_dir,
f"F_klines_{str(duration_seconds)}s")
elif adj_type == "B":
klines_dir_path = os.path.join(self.root_dir,
f"B_klines_{str(duration_seconds)}s")
else:
klines_dir_path = os.path.join(self.root_dir,
f"klines_{str(duration_seconds)}s")
if not os.path.exists(klines_dir_path):
os.mkdir(klines_dir_path)
klines = pd.DataFrame()
for symbol in symbols:
klines_file_path = os.path.join(klines_dir_path, f"{symbol}.csv")
if os.path.exists(klines_file_path):
continue
try:
klines = self.api.get_kline_data_series(symbol,
duration_seconds, start,
end, adj_type)
except Exception as e:
self.logger.log(logging.WARNING, f"{e}")
print(f"{datetime.now()}:{e}")
if not klines.empty:
klines_copy = klines.copy(deep=True)
klines_copy["new_datetime"]: datetime = klines_copy[
"datetime"].apply(
lambda x: Timestamp(x).to_pydatetime() + timedelta(hours=8))
klines_copy["date"] = klines_copy["new_datetime"].apply(
lambda x: x.date().strftime("%Y%m%d"))
klines_copy["time"] = klines_copy["new_datetime"].apply(
lambda x: x.time().strftime("%H:%M:%S"))
klines_copy = klines_copy.drop(["new_datetime", "datetime"],
axis=1)
klines_copy.to_csv(klines_file_path, index=False)
# 输出日志
self.logger.log(logging.INFO, f"{symbol}.csv文件创建完成!")
print(f"{datetime.now()},{symbol}.csv文件创建完成!")
else:
# 输出日志
self.logger.log(logging.WARNING, f"{symbol}.csv文件为空!")
print(f"{datetime.now()},{symbol}.csv文件为空!")
def download_today_klines(task_num, ins_class) -> None:
"""
task_num: 进程数
ins_class = FUTURE/STOCK
"""
symbols_filepath = SETTING.get(ins_class)
if not os.path.exists(symbols_filepath):
tq = TraceData.remote(SETTING.get("user"), SETTING.get("password"))
symbols = ray.get(tq.get_all_symbols.remote(ins_class=ins_class))
ray.shutdown()
else:
symbols = pd.read_csv(symbols_filepath)
symbols = list(symbols.iloc[:, 1].values)
start_time = datetime.now()
tqs = [TraceData.remote(SETTING.get("user"), SETTING.get("password")) for _
in range(task_num)]
length = len(symbols) // task_num
task_id = []
for i in range(task_num):
if i == task_num - 1:
symbols_part = symbols[i * length:]
else:
symbols_part = symbols[i * length:(i + 1) * length]
id_ = tqs[i].save_klines.remote(symbols_part)
task_id.append(id_)
ray.get(task_id)
end_time = datetime.now()
print(end_time - start_time)
def download_history_klines(task_num, ins_class, start, end,
adj_type: Union[str, None] = None) -> None:
"""
task_num: 进程数
ins_class = FUTURE/STOCK
start: 开始时间
end: 结束时间
"""
symbols_filepath = SETTING.get(ins_class)
expired = True if ins_class == "FUTURE" else False
if not os.path.exists(symbols_filepath):
tq = TraceData.remote(SETTING.get("user"), SETTING.get("password"))
symbols = ray.get(tq.get_all_symbols.remote(
ins_class=ins_class,
expired=expired))
ray.shutdown()
else:
symbols = pd.read_csv(symbols_filepath)
symbols = list(symbols.iloc[:, 1].values)
start_time = datetime.now()
tqs = [TraceData.remote(SETTING.get("user"), SETTING.get("password")) for _
in range(task_num)]
length = len(symbols) // task_num
task_id = []
for i in range(task_num):
if i == task_num - 1:
symbols_part = symbols[i * length:]
else:
symbols_part = symbols[i * length:(i + 1) * length]
duration_seconds = 60 if ins_class == "FUTURE" else 86400
id_ = tqs[i].save_bars.remote(symbols_part,
duration_seconds=duration_seconds,
start=start, end=end,
adj_type=adj_type) # 确保数据都可以下载到
task_id.append(id_)
ray.get(task_id)
end_time = datetime.now()
print(end_time - start_time)
if __name__ == '__main__':
download_history_klines(8, ins_class="FUTURE", start=datetime(2018, 1, 1),
end=datetime(2022, 10, 23))
download_history_klines(8, ins_class="STOCK", start=datetime(2018, 1, 1),
end=datetime(2022, 10, 23), adj_type="F")
download_history_klines(8, ins_class="STOCK", start=datetime(2018, 1, 1),
end=datetime(2022, 10, 23), adj_type="B")
download_history_klines(8, ins_class="STOCK", start=datetime(2018, 1, 1),
end=datetime(2022, 10, 23))
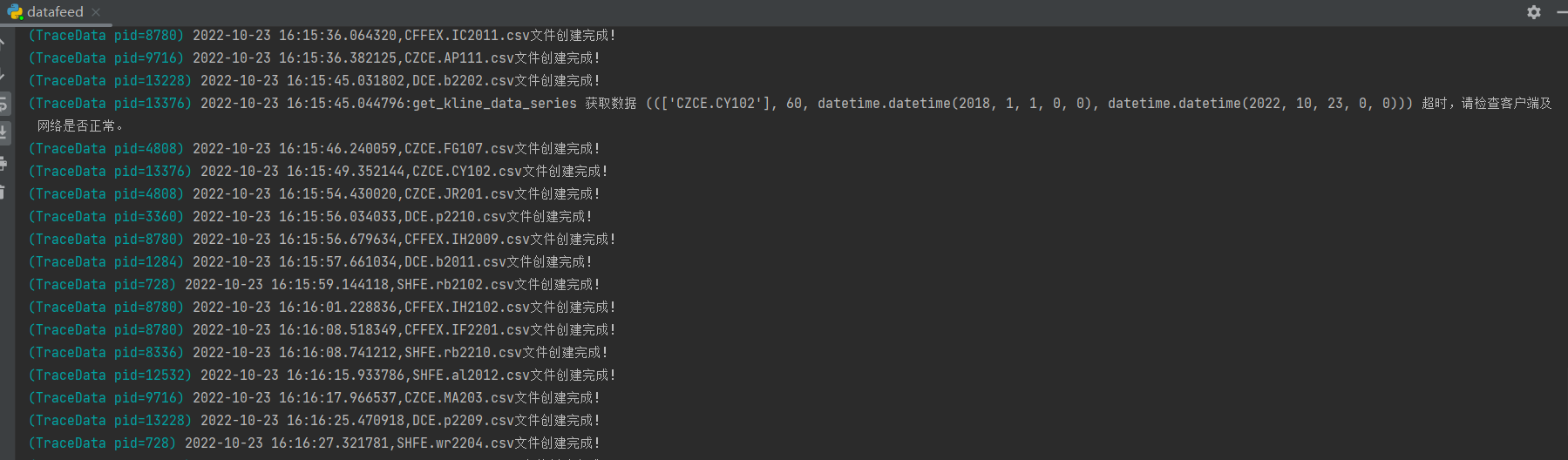

读者可以根据自己电脑cpu的数量选择合适的task_num,建议4核用户选择4个进程。
3. 多进程获取期货分钟数据并且每日实时更新历史数据
import logging
import os.path
from datetime import datetime, timedelta
import ray
import pandas as pd
from pandas import Series, Timestamp, DataFrame
from tqsdk import TqApi, TqAuth
SETTING = {"user": "your_user", "password": "your_passwrod",
"FUTURE": "future_symbols.csv"}
@ray.remote
class TraceData:
def __init__(self, account, password):
self.symbol = None
self.exchange = None
self.logger = None
self.api = TqApi(auth=TqAuth(account, password))
self.root_dir = r"D:MarketData" # 可以更改主路径位置
self.init()
def init(self) -> None:
# 检查目录是否创建
klines_dir = os.path.join(self.root_dir, "FutureData")
if not os.path.exists(klines_dir):
os.makedirs(klines_dir)
log_dir = os.path.join(self.root_dir, "log")
if not os.path.exists(log_dir):
os.makedirs(log_dir)
# 准备日志记录工具
self.logger = logging.getLogger("loging")
self.logger.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(asctime)s [%(levelname)s] %(message)s")
logfile_path = os.path.join(self.root_dir, "log", str(datetime.now().date().strftime('%Y%m%d')) + ".log")
file_handler = logging.FileHandler(logfile_path, mode="a",
encoding="utf8")
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
self.logger.addHandler(file_handler)
# 获取所有交易标的合约
def get_all_symbols(self, ins_class, expired=False) -> list:
"""
ins_class (str): [可选] 合约类型
* FUTURE: 期货
* STOCK: 股票
"""
exchanges = []
all_symbols = []
if ins_class == "FUTURE":
exchanges = ["SHFE", "CFFEX", "DCE", "CZCE", "INE"]
elif ins_class == "STOCK":
exchanges = ["SSE", "SZSE"]
for exchange in exchanges:
symbol = self.api.query_quotes(ins_class=ins_class,
exchange_id=exchange,
expired=expired)
all_symbols.extend(symbol)
df: Series = pd.Series(all_symbols, index=[i + 1 for i in range(len(all_symbols))])
filepath = os.path.join(self.root_dir, SETTING.get(ins_class))
if not os.path.exists(filepath):
df.to_csv(filepath, index=True, header=False)
return all_symbols
def save_klines(self, symbols: list):
"""下载指定标的k线数据"""
# 指定下载目录
klines_dir_path = os.path.join(self.root_dir, "FutureData", "1min", "tq")
if not os.path.exists(klines_dir_path):
os.makedirs(klines_dir_path)
for symbol in symbols:
klines_file_name: str = f"{symbol}.1min.csv"
klines_file_path = os.path.join(klines_dir_path, klines_file_name)
# 如果文件夹有文件,则更新
if not os.path.exists(klines_file_path):
continue
klines: DataFrame = pd.DataFrame()
try:
klines: DataFrame = self.api.get_kline_serial(symbol, 60, 600)
except Exception as e:
self.logger.log(logging.ERROR, f"{e}")
print(f"{datetime.now()}:{e}")
if not klines.empty:
# 合成指定格式的DataFrame
klines_copy = klines.copy(deep=True)
klines_copy["new_datetime"]: datetime = klines_copy[
"datetime"].apply(
lambda x: Timestamp(x).to_pydatetime() + timedelta(hours=8))
local_time = datetime.now()
klines_copy = klines_copy[
(klines_copy.new_datetime >= datetime(local_time.year,
local_time.month,
local_time.day - 1,
15,
30)) & (
klines_copy.new_datetime < datetime(local_time.year,
local_time.month,
local_time.day,
15,
30))]
klines_copy["date"] = klines_copy["new_datetime"].apply(
lambda x: x.date().strftime("%Y%m%d"))
klines_copy["time"] = klines_copy["new_datetime"].apply(
lambda x: x.time().strftime("%H:%M:%S"))
klines_copy: DataFrame = klines_copy.drop(["id", "new_datetime", "datetime", "duration"],
axis=1)
try:
# before_kines历史CSV文件 klines_copy 当前的数据 df合成后的数据
before_kines: DataFrame = pd.read_csv(klines_file_path)
df: DataFrame = pd.concat([before_kines, klines_copy])
# 根据date和time去重
df.drop_duplicates(
subset=['date', 'time'],
keep='first',
inplace=True)
df.to_csv(klines_file_path, index=False)
self.logger.log(logging.INFO, f"{klines_file_name}文件更新完成!")
print(f"{datetime.now()},{klines_file_name}文件更新完成!")
except Exception as e:
self.logger.log(logging.ERROR, e)
else:
# 输出日志
self.logger.log(logging.WARNING, f"{klines_file_name}下载当天数据为空")
print(f"{datetime.now()},{klines_file_name}下载当天数据为空")
def save_bars(self, symbols: list, duration_seconds: int, start: datetime,
end: datetime):
"""下载指定标的k线数据
adj_type (str/None): [可选]指定复权类型,默认为 None。adj_type 参数只对股票和基金类型合约有效。
"F" 表示前复权;"B" 表示后复权;None 表示不做处理。
"""
klines_dir_path = os.path.join(self.root_dir, "FutureData", f"{duration_seconds // 60}min", "tq")
if not os.path.exists(klines_dir_path):
os.makedirs(klines_dir_path)
klines = pd.DataFrame()
for symbol in symbols:
klines_file_name: str = f"{symbol}.{duration_seconds // 60}min.csv"
klines_file_path = os.path.join(klines_dir_path, klines_file_name)
if os.path.exists(klines_file_path):
continue
try:
klines = self.api.get_kline_data_series(symbol,
duration_seconds, start,
end)
except Exception as e:
self.logger.log(logging.ERROR, f"{e}")
print(f"{datetime.now()}:{e}")
if not klines.empty:
klines_copy = klines.copy(deep=True)
klines_copy["new_datetime"]: datetime = klines_copy[
"datetime"].apply(
lambda x: Timestamp(x).to_pydatetime() + timedelta(hours=8))
klines_copy["date"] = klines_copy["new_datetime"].apply(
lambda x: x.date().strftime("%Y%m%d"))
klines_copy["time"] = klines_copy["new_datetime"].apply(
lambda x: x.time().strftime("%H:%M:%S"))
klines_copy = klines_copy.drop(["new_datetime", "datetime", "id", "duration"],
axis=1)
klines_copy.to_csv(klines_file_path, index=False)
# 输出日志
self.logger.log(logging.INFO, f"{klines_file_name}文件创建完成!")
print(f"{datetime.now()},{klines_file_name}文件创建完成!")
else:
# 输出日志
self.logger.log(logging.WARNING, f"{klines_file_name}文件为空!")
print(f"{datetime.now()}{symbol}.{klines_file_name}文件为空!")
def download_today_klines(task_num, ins_class) -> None:
"""
task_num: 进程数
ins_class:FUTURE
"""
symbols_filepath = SETTING.get(ins_class)
if not os.path.exists(symbols_filepath):
tq = TraceData.remote(SETTING.get("user"), SETTING.get("password"))
symbols = ray.get(tq.get_all_symbols.remote(ins_class=ins_class))
ray.shutdown()
else:
symbols = pd.read_csv(symbols_filepath)
symbols = list(symbols.iloc[:, 1].values)
start_time = datetime.now()
tqs = [TraceData.remote(SETTING.get("user"), SETTING.get("password")) for _
in range(task_num)]
length = len(symbols) // task_num
task_id = []
for i in range(task_num):
if i == task_num - 1:
symbols_part = symbols[i * length:]
else:
symbols_part = symbols[i * length:(i + 1) * length]
id_ = tqs[i].save_klines.remote(symbols_part)
task_id.append(id_)
ray.get(task_id)
end_time = datetime.now()
print(end_time - start_time)
def download_history_klines(task_num, ins_class, start, end) -> None:
"""
task_num: 进程数
ins_class = FUTURE
start: 开始时间
end: 结束时间
注意: 只能下载2018年1月2日以后的数据
"""
symbols_filepath = SETTING.get(ins_class)
if not os.path.exists(symbols_filepath):
tq = TraceData.remote(SETTING.get("user"), SETTING.get("password"))
symbols = ray.get(tq.get_all_symbols.remote(
ins_class=ins_class,
expired=False))
ray.shutdown()
else:
symbols = pd.read_csv(symbols_filepath)
symbols = list(symbols.iloc[:, 1].values)
start_time = datetime.now()
tqs = [TraceData.remote(SETTING.get("user"), SETTING.get("password")) for _
in range(task_num)]
length = len(symbols) // task_num
task_id = []
for i in range(task_num):
if i == task_num - 1:
symbols_part = symbols[i * length:]
else:
symbols_part = symbols[i * length:(i + 1) * length]
duration_seconds = 60 if ins_class == "FUTURE" else 86400
id_ = tqs[i].save_bars.remote(symbols_part,
duration_seconds=duration_seconds,
start=start, end=end)
task_id.append(id_)
ray.get(task_id)
end_time = datetime.now()
print(end_time - start_time)
if __name__ == '__main__':
# 先使用download_history_klines()函数下载历史数据,如果试用期限过了,
# 可以每天3点半后运行download_today_klines()函数会自动拼接历史数据
# download_history_klines(8, ins_class="FUTURE", start=datetime(2018, 1, 2),
# end=datetime.now().date())
download_today_klines(8, "FUTURE")
4.常见问题
4.1 ray包无法安装
ray官方文档:https://docs.ray.io/en/latest/ray-overview/installation.html
进入官方文档
下载对应的wheel包
将包放到工程文件下,进入pycharm的terminal界面,运行如下命令
# Clean removal of previous install
pip uninstall -y ray
# Install Ray with support for the dashboard + cluster launcher
pip install -U "ray[default] @ LINK_TO_WHEEL.whl"
# Install Ray with minimal dependencies
# pip install -U LINK_TO_WHEEL.whl

4.2 免费账户能否获得当天股票行情?
不行,如果要获取免费的股票行情,可以尝试用tushare或者rqdata,借用veighna框架可以非常轻松地将数据保存到本地数据库,笔者后续会出一篇博文。
4.3 下载数据超时,卡顿严重怎么办?
下载超时等待时间长,修改tqsdk源代码
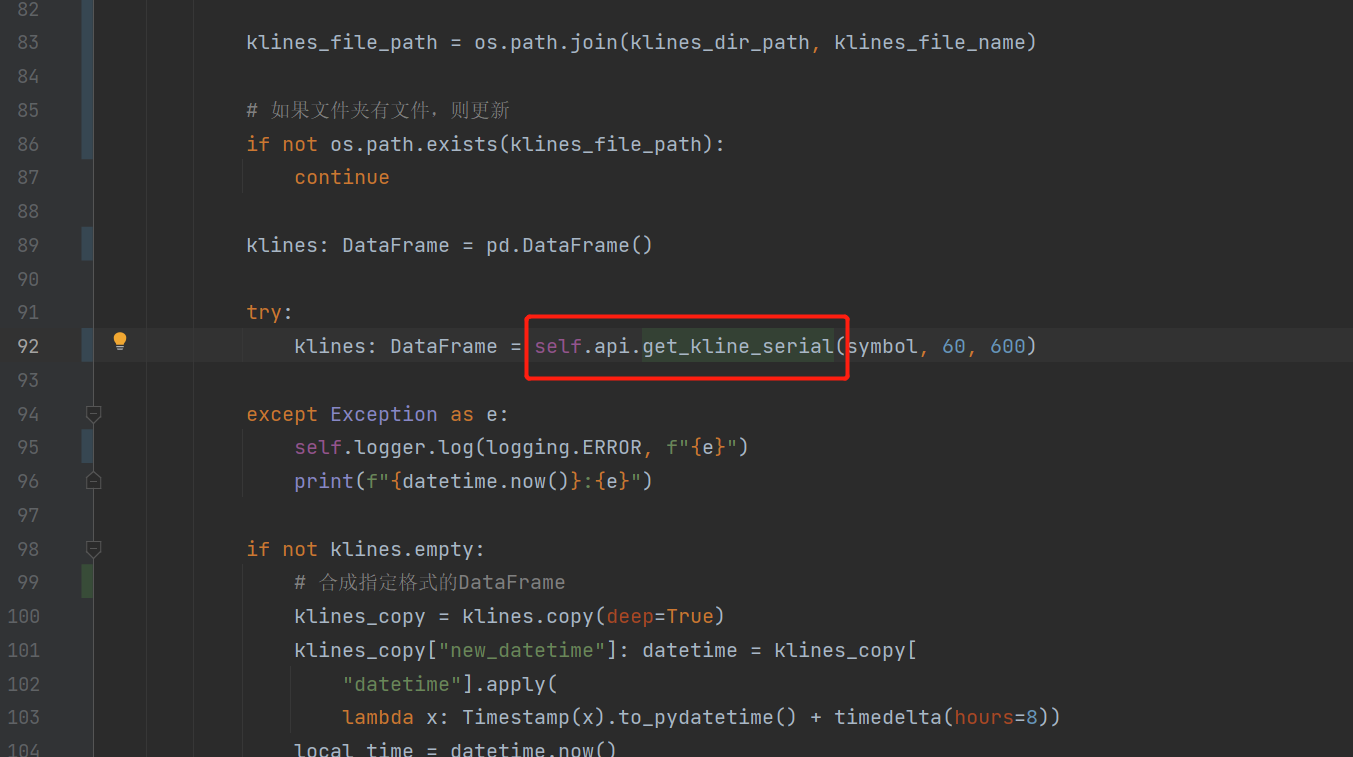
pycharm使用curl+鼠标左键进入源码
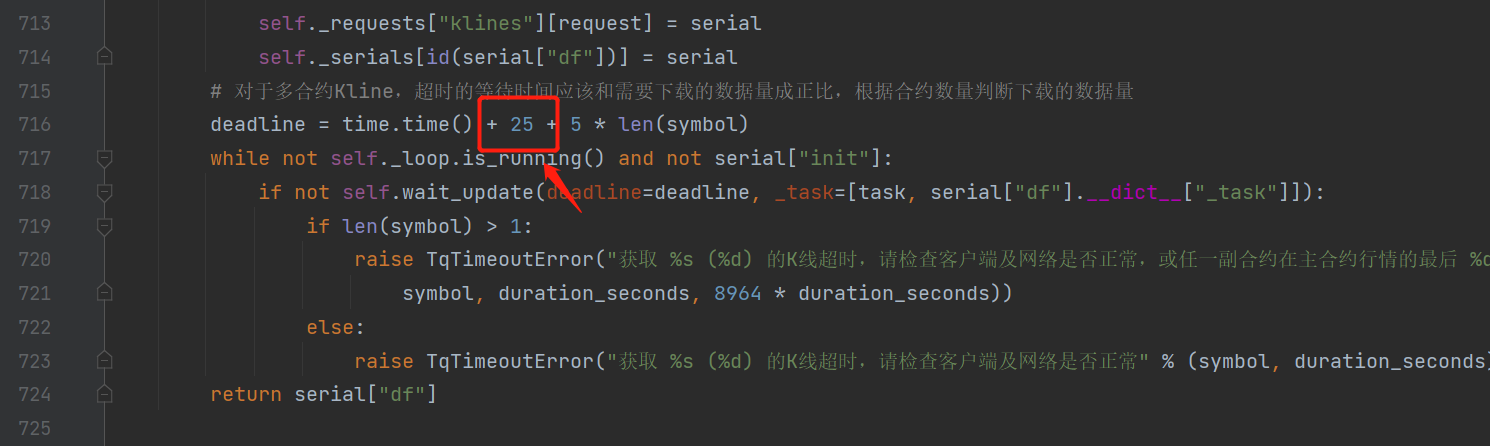
第716行,将25改成8,缩短等待时间。
原文地址:https://blog.csdn.net/m0_58598240/article/details/127475115
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_44402.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







