本文介绍: scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API(也即是web api)来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们scrapyd的安装scrapyd服务端: pip install scrapydscrapyd客户端: pip install scrapyd–client启动scrapyd服务在scrapy项目路径下 启动scrapyd的命令:sudo scrapyd 或 scrapyd。
一、scrapyd的介绍
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API(也即是web api)来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
在scrapy项目路径下 启动scrapyd的命令:sudo scrapyd 或 scrapyd。启动之后就可以打开本地运行的scrapyd,浏览器中访问本地6800端口可以查看scrapyd的监控界面




同样在scrapy项目路径下执行:
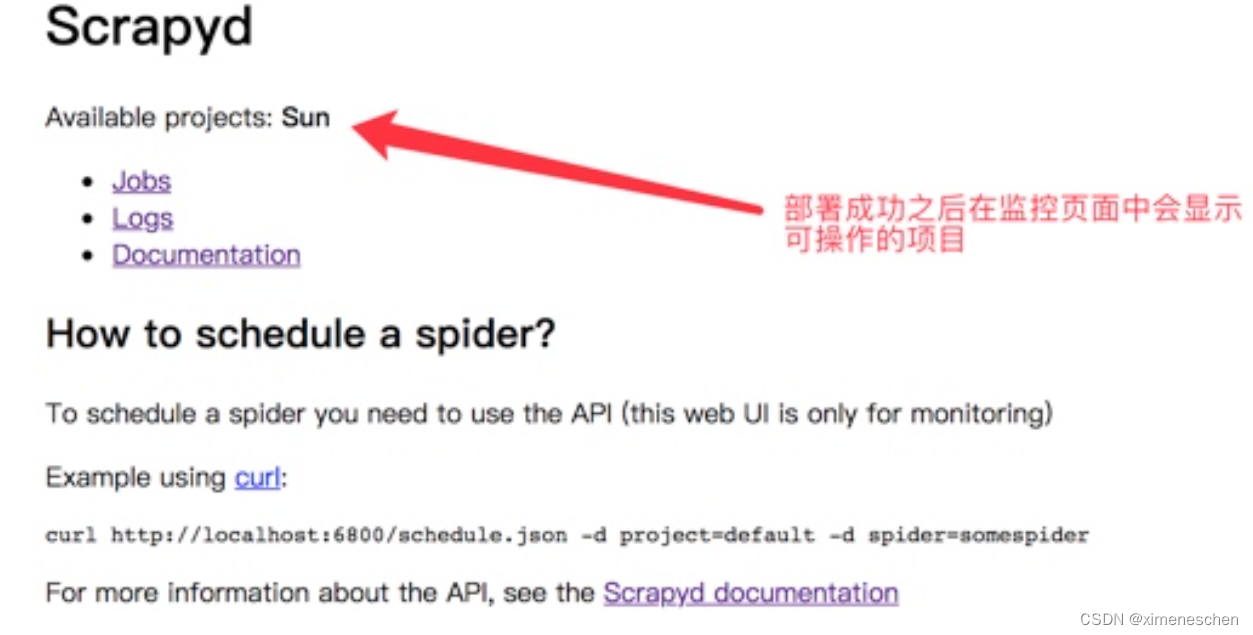
启动项目:
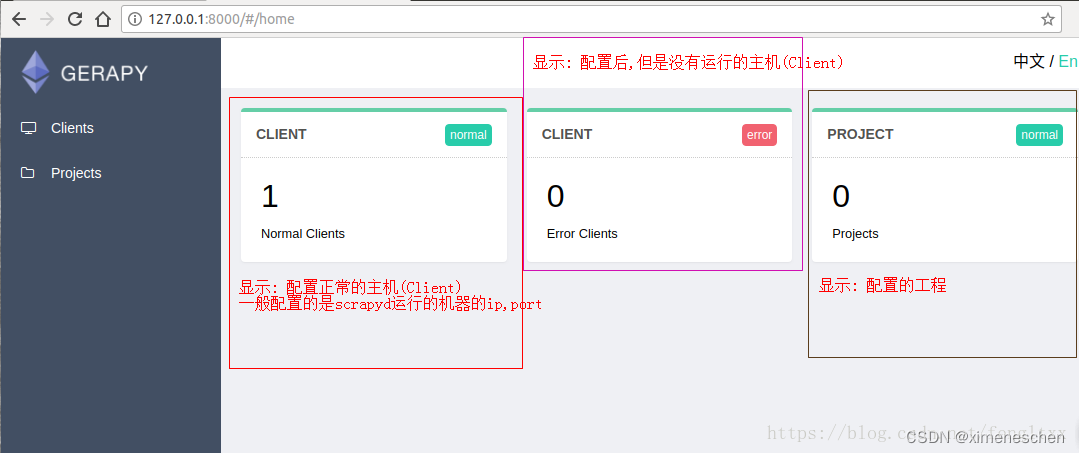
二、gerapy
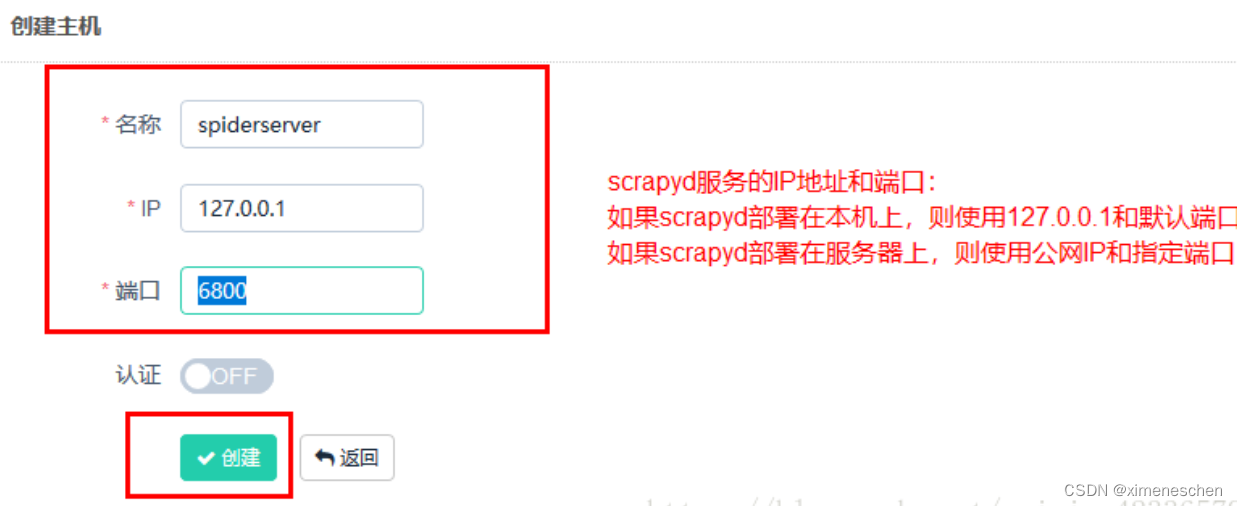
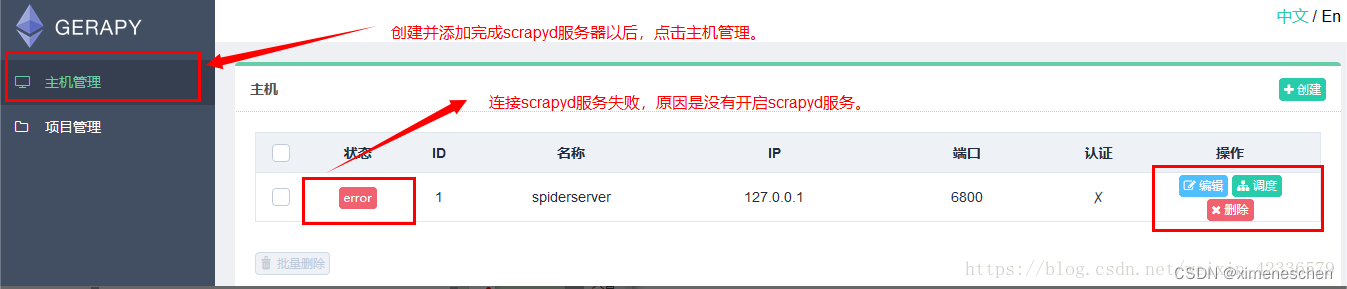
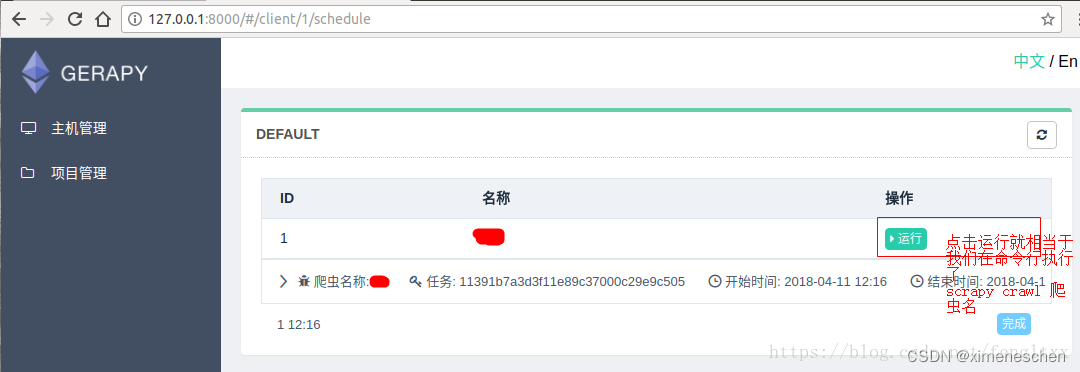

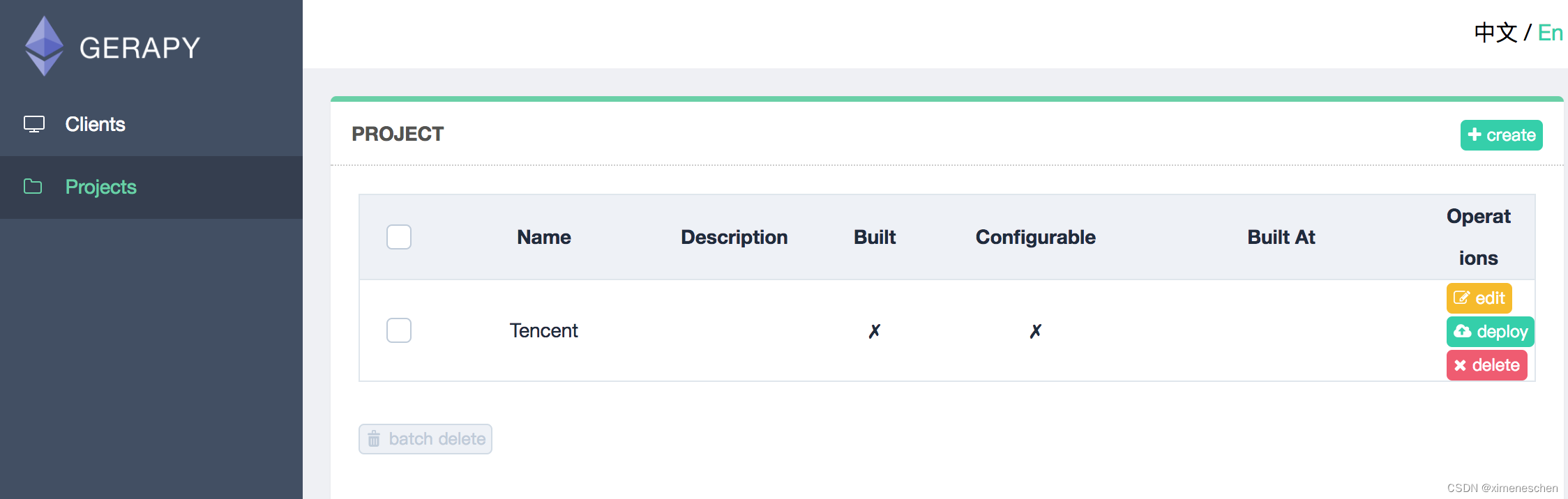
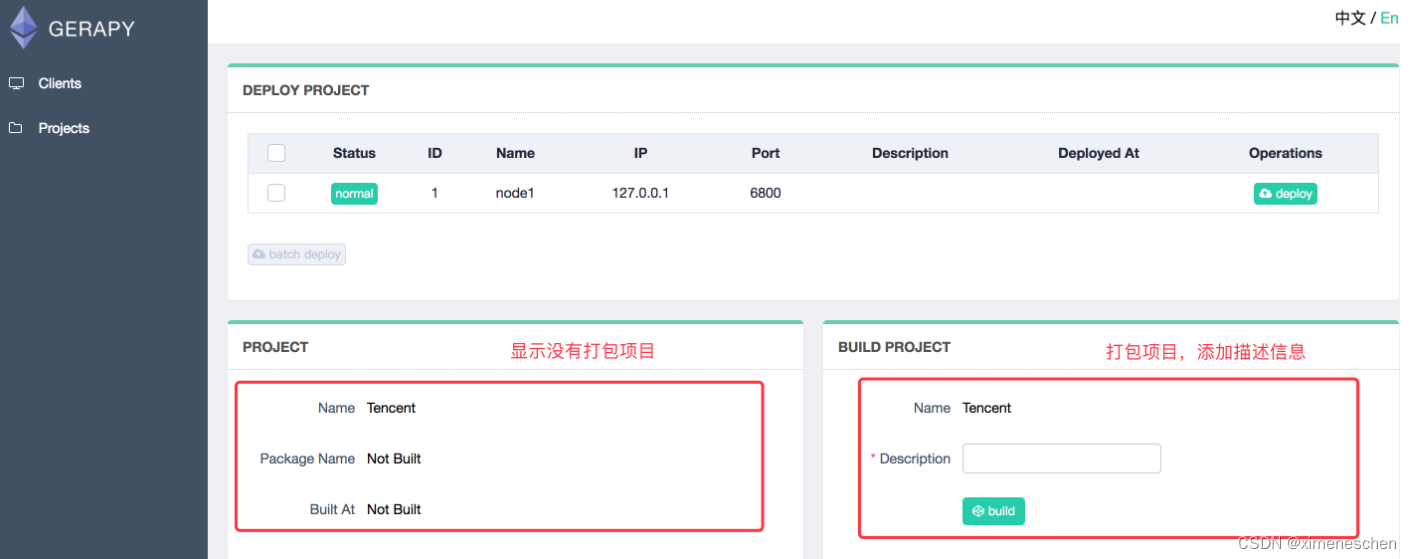
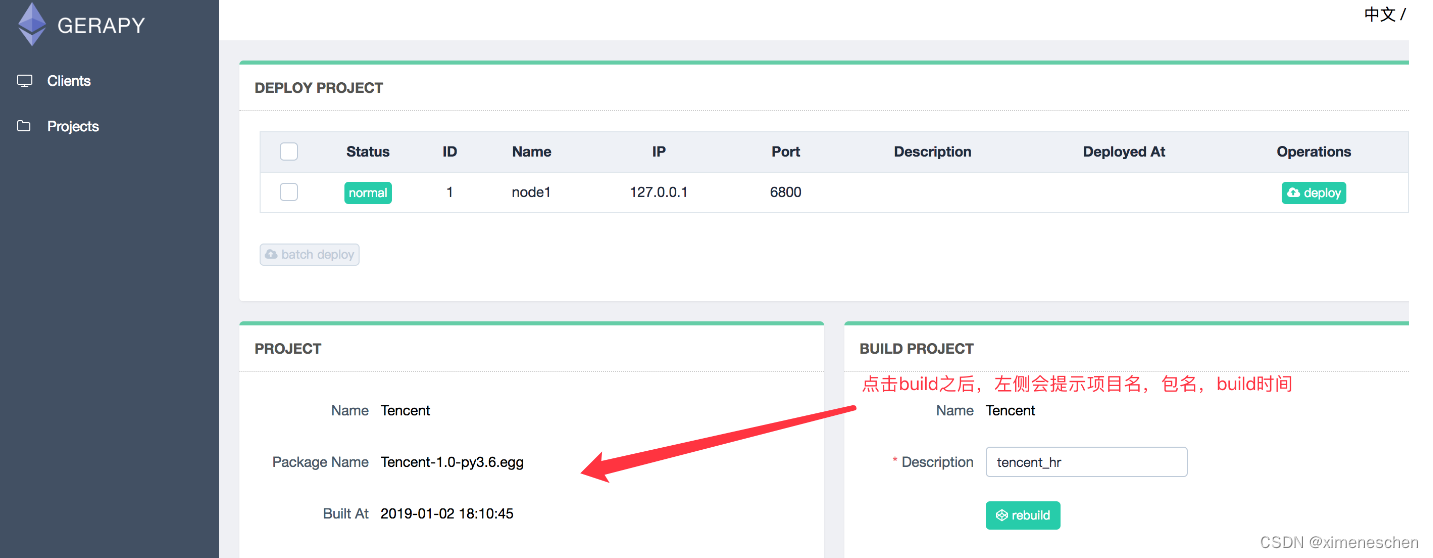

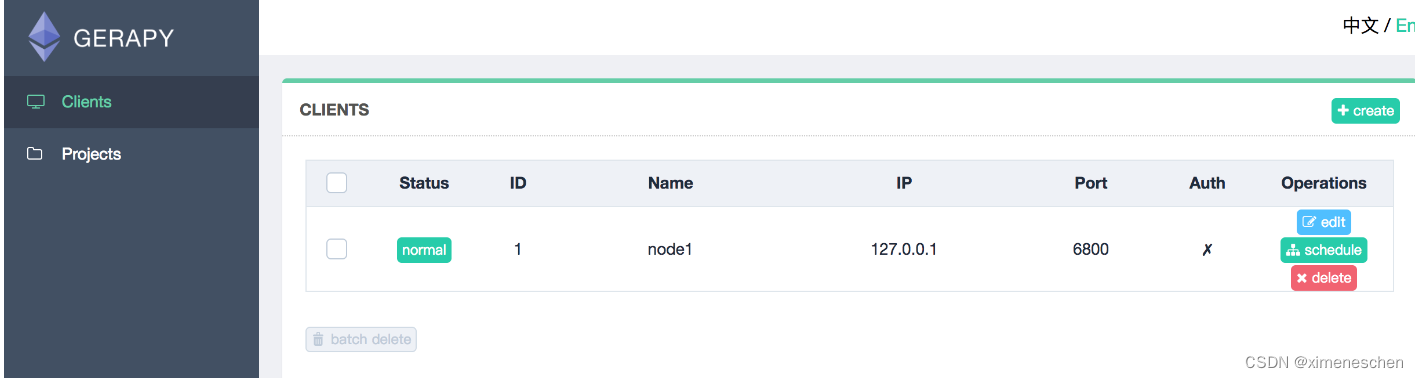

三、基于docker–compose的方式
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




