前言
pandas为DataFrame格式数据添加新列的方法非常简单,只需要新建一个列索引,再为其赋值即可。
|
1 2 3 4 5 6 |
data ={‘a’: [‘a0’, ‘a1’, ‘a2’], |

一、insert()函数
语法:
DataFrame.insert(loc, column, value,allow_duplicates = False)
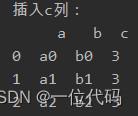
二、直接赋值法
注:该方法不可以选择插入新列的位置,默认为最后一列。如果新增的一列值相同,直接为其赋值一个常量即可;如果插入值不同,为列表格式,需与已有列的行数长度一致,如举例中原来列为3行,新增列也必须有3个值。
三、reindex()函数
语法:df.reindex(columns=[原来所有的列名,新增列名],fill_value=值)
df = df.reindex(columns=df.columns.tolist() + [‘新增列名‘]+[‘新增列名‘])
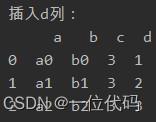
实例:插入e列
|
1 2 3 4 |
df1 =df.reindex(columns=[‘a’, ‘b‘, ‘c‘, ‘d’, ‘e’]) # 不加fill_value参数,默认值为Nan df2 =df.reindex(columns=[‘a’, ‘b‘, ‘c‘, ‘d’, ‘e’], fill_value=1) # 加入fill_value参数,填充值为1 |

注:该方法需要把原有的列名和新列名都加上,如果列名过多,就比较麻烦。
四、concat()函数
原理:利用拼接的方式,添加新的一列。好处是可以同时新增多个列名。
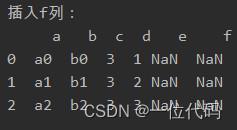
实例:插入f列
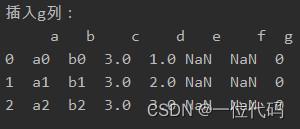
五、loc()函数
附:pandas根据现有列新添加一列
pandas中一个Dataframe,经常需要根据其中一列再新建一列,比如一个常见的例子:需要根据分数来确定等级范围,下面我们就来看一下怎么实现。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
else:
data ={‘name‘: [‘lili‘, ‘lucy‘, ‘tracy’, ‘tony‘, ‘mike’], ‘score‘: [85, 61, 75, 49, 90] } # df[‘level‘] = df.apply(lambda x: getlevel(x[‘score’]), axis=1) df[‘level‘] =df.apply(lambdax: getlevel(x.score), axis=1)
|
name score level
0 lili 85 good
1 lucy 61 mid
2 tracy 75 mid
3 tony 49 bad
4 mike 90 good
要实现上面的功能,主要是使用到dataframe中的apply方法。
上面的代码,对dataframe新增加一列名为level,level由分数一列而来,如果小于60分为bad,60-80之间为mid,80以上为good。
其中axis=1表示原有dataframe的行不变,列的维数发生改变。
总结
原文地址:https://blog.csdn.net/lzjhyhf/article/details/129205949
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_44950.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!