前端和后端之间的数据传递至关重要。然而,当涉及到Long类型数据时,可能会出现精度丢失问题,这会影响数据的准确性。本文将为你介绍两种解决方案,帮助你确保Long类型数据在前端和后端之间的精确传递。
精度丢失测试
访问:http://localhost:8099/pages/students.html,查询所有数据,发现后台返回数据如下

复制id=1692936528247996400在sql控制台进行数据查询
select * from tb_student where id=1692936528247996400;
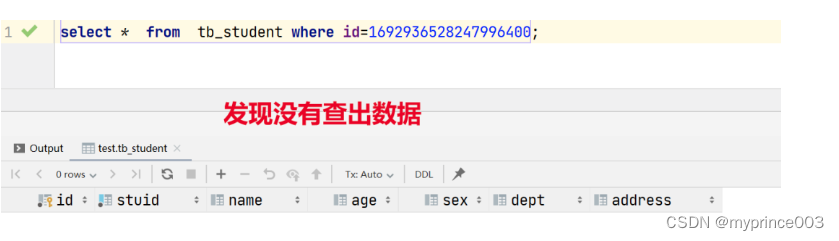
这和我们在数据库查询到的id不一致:
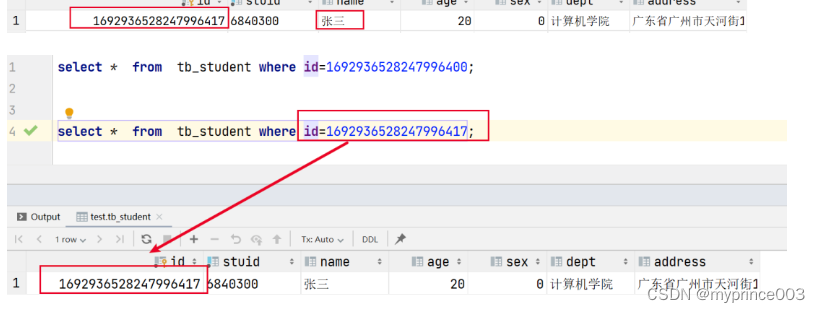
没有查出数据原因
目前学生id为long类型,在转换json传递到前端以后精度丢失,所以查询详情的学生id也是丢失精度的id,不能查询数据。
1692936528247996417 19位 1692936528247996400
因为js数字类型最大长度为16位,而java的long类型的最大长度为19位。所以如果数据长度大于16位的话传输到前端就会丢失精度。
- Long类型转换精度丢失问题解决
2.1. 使用字符串传递
一种简单而有效的方法是将Long类型数据在后端和前端之间使用字符串进行传递。这样可以避免JSON中的数值表示形式限制。
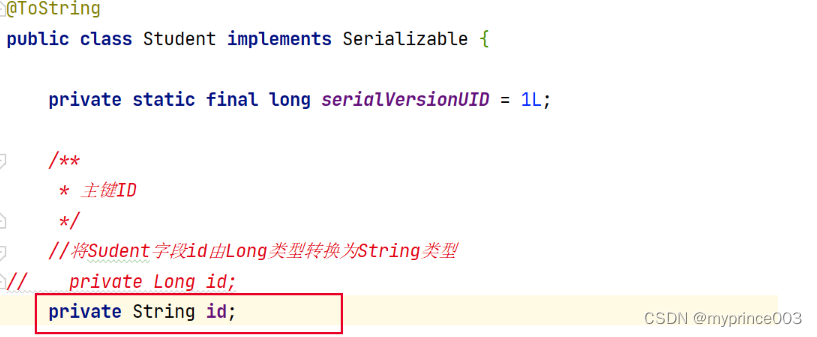
重新启动,获取所有数据

发现前端数据id带上双引号,也就是id由Long类型转换为了String类型
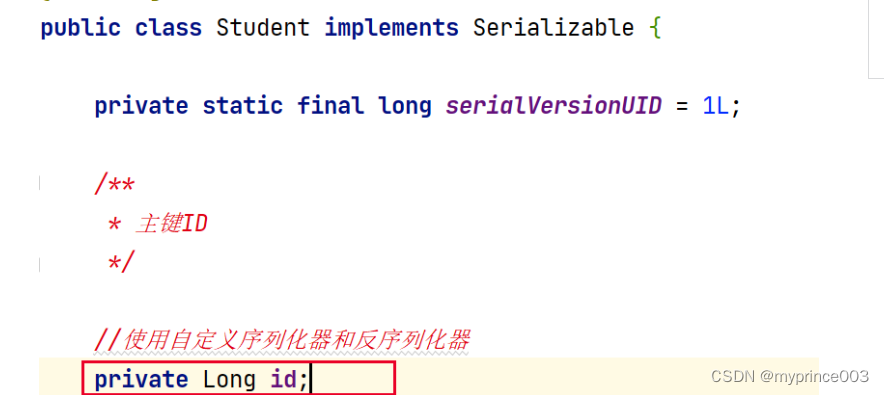
2.2 使用自定义序列化器和反序列化器
使用自定义JSON序列化器和反序列化器,以处理Long类型数据。这可以通过配置Jackson ObjectMapper来实现。
代码实现
在com.test.config包下添加JacksonConfig配置类
package com.test.config;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.DeserializationContext;
import com.fasterxml.jackson.databind.JsonDeserializer;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.module.SimpleModule;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.IOException;
@Configuration
public class JacksonConfig {
@Bean
public ObjectMapper objectMapper() {
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.registerModule(new SimpleModule() {
{
addSerializer(Long.class, new ToStringSerializer());
addDeserializer(Long.class, new JsonDeserializer<Long>() {
@Override
public Long deserialize(JsonParser p, DeserializationContext ctxt) throws IOException {
return Long.parseLong(p.getText());
}
});
}
});
return objectMapper;
}
}
将Student类的id重新转换为Long类型
重新启动,获取所有数据

JacksonConfig配置将Long类型数据序列化为字符串,并在反序列化时将其解析为Long类型。
3.两种方案对比
方法 1:使用字符串传递
优点:
简单易用:这种方法非常简单,只需将Long类型数据转换为字符串,并在前后端之间传递。
避免精度问题:通过将Long数据表示为字符串,可以完全避免在JSON中出现的浮点数精度问题。通用性:这种方法在所有前端框架和编程语言中都适用,因为它只涉及字符串数据。
缺点:
转换开销:将Long类型数据转换为字符串可能会产生一些额外的转换开销,尤其是在大规模数据传递时。
方法 2:使用自定义序列化器和反序列化器
优点:
精确控制:自定义序列化器和反序列化器允许你精确控制Long类型数据的JSON表示,确保数据不会丢失精度。
性能优化:这种方法可以更高效,因为它避免了将Long转换为字符串和再次解析的开销。
适用性广泛:如果你使用不同的数据类型(如BigDecimal),这种方法同样适用。
缺点:
复杂性:自定义序列化器和反序列化器的配置可能需要额外的工作,可能对初学者不太友好。
对特定技术栈:这种方法通常需要更深入的了解和适用于特定的技术栈,如Spring Boot和Jackson。
结论
精度丢失问题在前端和后端数据传递中是一个常见的挑战,尤其是涉及大整数(Long)时。然而,通过使用字符串传递或自定义JSON序列化器和反序列化器,你可以轻松解决这个问题,确保数据的完整性和准确性。选择适合你项目需求的方法,并确保前端和后端之间的数据交流顺畅。
原文地址:https://blog.csdn.net/weixin_45817985/article/details/134681428
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_44978.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!