一、minist数据集
深度学习编程特有的hello world程序:采用minist数据集完成意向特定深度学习项目
1、minist数据集介绍
MNIST数据集是一个广泛使用的手写数字识别数据集,它包含了许多不同人手写的数字图片。这个数据集被广泛用于研究手写数字识别,是深度学习领域的一个典型应用。
一共包含四个文件夹:
train–images–idx3-ubyte.gz:训练集图像(9912422 字节)55000张训练集 + 5000张验证集;
train–labels–idx1-ubyte.gz:训练集标签(28881 字节)训练集对应的标签;
t10k–images–idx3-ubyte.gz:测试集图像(1648877 字节)10000张测试集;
t10k–labels-idx1-ubyte.gz:测试集标签(4542 字节)测试集对应的标签;
2、下载
如果你手头有《从零开始大模型开发与微调》这本书,随书附赠的代码中就有这个数据集,如果你有但也想尝试自行处理数据,就可以跟着看下去。
进入官网、四个链接分别下载进一个文件夹里、解压(我用的是7z解压)
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
3、读取文件
鉴于idx-udyte文件的特殊性,我们需要一些特殊的方法读取文件中的数据:
以数据集的idx3-udyte为例,idx3-udyte文件的数据都是二进制数、由四个32位数组成的表头和具体数据组成。其中表头的四个32位数分别是魔数和第三维、行、列的数目。同理idx1-udyte由两个32位数组成表头,魔数和第三维的数目。
读取方法参考(照搬)了该文章: 数据集解析 001:MNIST数据集与IDX文件(附带IDX文件提取代码Python版)_fmt_header = ‘>iiii-CSDN博客
然后通过struct模块的unpack_from()方法提取表头:
fmt_header = '>iiii'
offset = 0
# 从偏移量位0的位置开始读取四个整型(4字节32位)
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, content, offset)
print ('幻数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
struct.unpack_from() 这个方法用一句话概括其功能就是:从某个文件中以特定的格式读取出相应的数据。至于fmt_header、offset这些都是提取时使用的参数,具体含义想理解的可以自行学习理解。
之后读取除了表头以外的其他数据:
剩下的数据,就是n多个x行y列的图片数据、图片数据本质上就是一个三维数组、我们的工作就是将这些实质上是三维数组的数据存储成真正的三维数组
#定义一张图片需要的数据个数(每个像素一个字节,共需要行*列个字节的数据)
img_size = num_rows*num_cols
#struct.calcsize(fmt)用来计算fmt格式所描述的结构的大小
offset += struct.calcsize(fmt_header)
# '>784B'是指用大端法读取784个unsigned byte
fmt_image = '>' + str(img_size) + 'B'
#定义了一个三维数组,这个数组共有num_images个 num_rows*num_cols尺寸的矩阵。
images = np.empty((num_images, num_rows, num_cols))
for i in range(num_images):
images[i] = np.array(struct.unpack_from(fmt_image, content, offset)).reshape((num_rows,num_cols))
offset += struct.calcsize(fmt_image)
# print(images[0]) # 输出一个样例备注:struct.calcsize()>
备注:<np.empty()>详解
备注:<np.array()>详解
备注:<np.reshape()>详解
4、举一反三:
已知如何读取idx3-udyte类型的数据,那么我们就可以举一反三相对应的写出idx1-udyte类型的数据,并把这两个方法放入同一个类中
import struct
import numpy as np
"""
ReadData类,其中有两个方法read_data()
read_data1() 输入一个路径参数roadurl,返回该idx1-udata
read_data3() 输入一个路径参数roadurl,返回该idx3-udata
"""
class ReadData():
def read_data1(self, roadurl):
with open(roadurl, 'rb') as f:
content = f.read()
# print(content)
fmt_header = '>ii' # 网络字节序
offset = 0
magic_number, num_images= struct.unpack_from(fmt_header, content, offset)
print('幻数:%d, 图片数量: %d张' % (magic_number, num_images))
# 图片的标签是一个int类型变量。
img_size = 1
# struct.calcsize(fmt)用来计算fmt格式所描述的结构的大小
offset += struct.calcsize(fmt_header)
# '>1B'是指用大端法读取1个unsigned byte
fmt_image = '>' + str(img_size) + 'B'
# 定义了一个数组,这个数组共有num_images个图片标签。
images = np.empty(num_images)
for i in range(num_images):
images[i] = np.array(struct.unpack_from(fmt_image, content, offset))
offset += struct.calcsize(fmt_image)
return images
"""
ReadData类,其中只有一个方法read_data()
"""
def read_data3(self, roadurl):
with open(roadurl, 'rb') as f:
content = f.read()
# print(content)
fmt_header = '>iiii' # 网络字节序
offset = 0
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, content, offset)
print('幻数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
# 定义一张图片需要的数据个数(每个像素一个字节,共需要行*列个字节的数据)
img_size = num_rows * num_cols
# struct.calcsize(fmt)用来计算fmt格式所描述的结构的大小
offset += struct.calcsize(fmt_header)
# '>784B'是指用大端法读取784个unsigned byte
fmt_image = '>' + str(img_size) + 'B'
# 定义了一个三维数组,这个数组共有num_images个 num_rows*num_cols尺寸的矩阵。
images = np.empty((num_images, num_rows, num_cols))
for i in range(num_images):
images[i] = np.array(struct.unpack_from(fmt_image, content, offset)).reshape((num_rows, num_cols))
offset += struct.calcsize(fmt_image)
return images
# 试运行一下看一看
if __name__ == '__main__':
a = ReadData()
print(a.read_data1("train-labels.idx1-ubyte"))至此我们已经完成了数据的前期处理,接下来就需要请出大模型了。
二、大模型
1、选择模型
作为helloworld级别的程序,我们不需要去了解具体怎么选择模型,你只需要知道我们这里使用的是Unet模型即可。这是一种输入和输出的大小维度都相同的模型。
2、Unet模型的整体结构
import torch
class Unet(torch.nn.Module):
def __init__(self):
super(Unet, self).__init__()
# 模块化结构,这也是后面常用到的模型结构
self.first_block_down = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1), torch.nn.GELU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
self.second_block_down = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1), torch.nn.GELU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2)
)
self.latent_space_block = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1), torch.nn.GELU(),
)
self.second_block_up = torch.nn.Sequential(
torch.nn.Upsample(scale_factor=2),
torch.nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, padding=1), torch.nn.GELU(),
)
self.first_block_up = torch.nn.Sequential(
torch.nn.Upsample(scale_factor=2),
torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, padding=1), torch.nn.GELU(),
)
self.convUP_end = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=32, out_channels=1, kernel_size=3, padding=1),
torch.nn.Tanh()
)
def forward(self, img_tensor):
image = img_tensor
image = self.first_block_down(image) # ;print(image.shape) # torch.Size([5, 32, 14, 14])
image = self.second_block_down(image) # ;print(image.shape) # torch.Size([5, 16, 7, 7])
image = self.latent_space_block(image) # ;print(image.shape) # torch.Size([5, 8, 7, 7])
image = self.second_block_up(image) # ;print(image.shape) # torch.Size([5, 16, 14, 14])
image = self.first_block_up(image) # ;print(image.shape) # torch.Size([5, 32, 28, 28])
image = self.convUP_end(image) # ;print(image.shape) # torch.Size([5, 32, 28, 28])
return image
if __name__ == '__main__':
image = torch.randn(size=(5, 1, 28, 28))
unet_model = Unet()
torch.save(unet_model, './unet_model.pth')3、模型的损失函数与优化函数
损失函数的主要目的是评估模型的预测结果与实际结果之间的不一致程度,优化函数是用来指导模型如何通过调整参数来最小化损失函数的函数。
损失函数就是在样本集中选一批数据,然后只给输入让模型给输出,然后根据输出与样本集的标签作对比得出一个数值,这个数值越小越好。我们这里使用的是均方损失函数MSEless
# 模型的损失函数
pred = model(x_imgs_batch) # 对模型进行正向计算
loss = torch.nn.MSELoss(reduction="sum")(pred, y_batch) * 100. # 使用损失函数进行计算优化函数同理不在讲解,这里选择的是adam优化器。我们只需要知道这些都是很重要的内容即可
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) # 设定优化函数,学习率为lr4、模型训练参数
# 载入数据 如果你使用这里给的数据集可以用这个方法
x_train = np.load("../dataset/mnist/x_train.npy")
y_train_label = np.load("../dataset/mnist/y_train_label.npy")
# 如果用的是自己找的数据集则要用
x_train = rdOne.read_data3("G:/机械学习/数据集/minist/MNIST/train-images.idx3-ubyte")
y_train_label = rdOne.read_data1("G:/机械学习/数据集/minist/MNIST/train-labels.idx1-ubyte")报错:“ AttributeError: module ‘backend_interagg‘ has no attribute ‘FigureCanvas‘ “:
# import matplotlib.puplot as plt
import matplotlib
# 切换为图形界面显示的终端TkAgg
matplotlib.use('TkAgg')
# 导入matplotlib的pyplot
import matplotlib.pyplot as plt5、基于深度学习的模型训练
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 指定GPU编
import torch
import numpy as np
import unet
from tqdm import tqdm
from read_data import ReadData as rdOne
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
# 切换为图形界面显示的终端TkAgg
# 导入matplotlib的pyplot
batch_size = 320 # 设定每次训练的批次数
epochs = 1024 # 设定训练次数
# device = "cpu" #Pytorch的特性,需要指定计算的硬件,如果没有GPU的存在,就使用CPU进行计算
device = "cuda" # 在这里读者默认使用GPU,如果读者出现运行问题可以将其改成cpu模式
model = unet.Unet() # 导入Unet模型
model = model.to(device) # 将计算模型传入GPU硬件等待计算
# model = torch.compile(model) #Pytorch2.0的特性,加速计算速度 选择使用内容
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) # 设定优化函数,学习率为lr
# 载入数据 如果你使用这里给的数据集可以用这个方法
# x_train = np.load("../dataset/mnist/x_train.npy")
# y_train_label = np.load("../dataset/mnist/y_train_label.npy")
# 如果用的是自己找的数据集则要用
x_train = rdOne.read_data3("G:/机械学习/数据集/minist/MNIST/train-images.idx3-ubyte")
y_train_label = rdOne.read_data1("G:/机械学习/数据集/minist/MNIST/train-labels.idx1-ubyte")
x_train_batch = []
for i in range(len(y_train_label)):
if y_train_label[i] <= 10: # 为了加速演示作者只对数据集中的小于2的数字,也就是0和1进行运行,读者可以自行增加训练个数
x_train_batch.append(x_train[i])
x_train = np.reshape(x_train_batch, [-1, 1, 28, 28]) # 修正数据输入维度:([30596, 28, 28])
x_train /= 512.
train_length = len(x_train) * 20 # 增加数据的单词循环次数
# state_dict = torch.load("./saver/unet.pth")
# model.load_state_dict(state_dict)
for epoch in range(30): # 循环30次
train_num = train_length // batch_size # 计算有多少批次数
train_loss = 0 # 用于损失函数的统计
for i in tqdm(range(train_num)): # 开始循环训练
x_imgs_batch = [] # 创建数据的临时存储位置
x_step_batch = []
y_batch = []
# 对每个批次内的数据进行处理
for b in range(batch_size):
img = x_train[np.random.randint(x_train.shape[0])] # 提取单个图片内容
x = img
y = img
x_imgs_batch.append(x)
y_batch.append(y)
# 将批次数据转化为Pytorch对应的tensor格式并将其传入GPU中
x_imgs_batch = torch.tensor(x_imgs_batch).float().to(device)
y_batch = torch.tensor(y_batch).float().to(device)
# 模型的损失函数
pred = model(x_imgs_batch) # 对模型进行正向计算
loss = torch.nn.MSELoss(reduction="sum")(pred, y_batch) * 100. # 使用损失函数进行计算
# 这里读者记住下面就是固定格式,一般而言这样使用即可
optimizer.zero_grad() # 对结果进行优化计算
loss.backward() # 损失值的反向传播
optimizer.step() # 对参数进行更新
train_loss += loss.item() # 记录每个批次的损失值
# 计算并打印损失值
train_loss /= train_num
print("train_loss:", train_loss)
if epoch % 6 == 0:
torch.save(model.state_dict(), "./saver/unet.pth")
# 下面是对数据进行打印
image = x_train[np.random.randint(x_train.shape[0])] # 随机挑选一条数据进行计算
image = np.reshape(image, [1, 1, 28, 28]) # 修正数据维度
image = torch.tensor(image).float().to(device) # 挑选的数据传入硬件中等待计算
image = model(image) # 使用模型对数据进行计算
image = torch.reshape(image, shape=[28, 28]) # 修正模型输出结果
image = image.detach().cpu().numpy() # 将计算结果导入CPU中进行后续计算或者展示
# 展示或计算数据结果
plt.imshow(image)
plt.savefig(f"./img/img_{epoch}.jpg")三、总结
1、文件总览
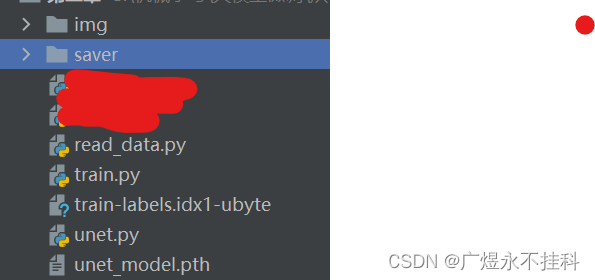
共有:
1个img文件夹用以存储图片文件
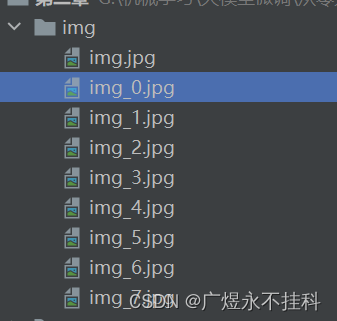
2、训练结果
完整的训练时间可能需要很久,这里只训练了很短的时间,所以只出了部分结果。

原文地址:https://blog.csdn.net/qq_48843954/article/details/134768020
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_45242.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!



![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)