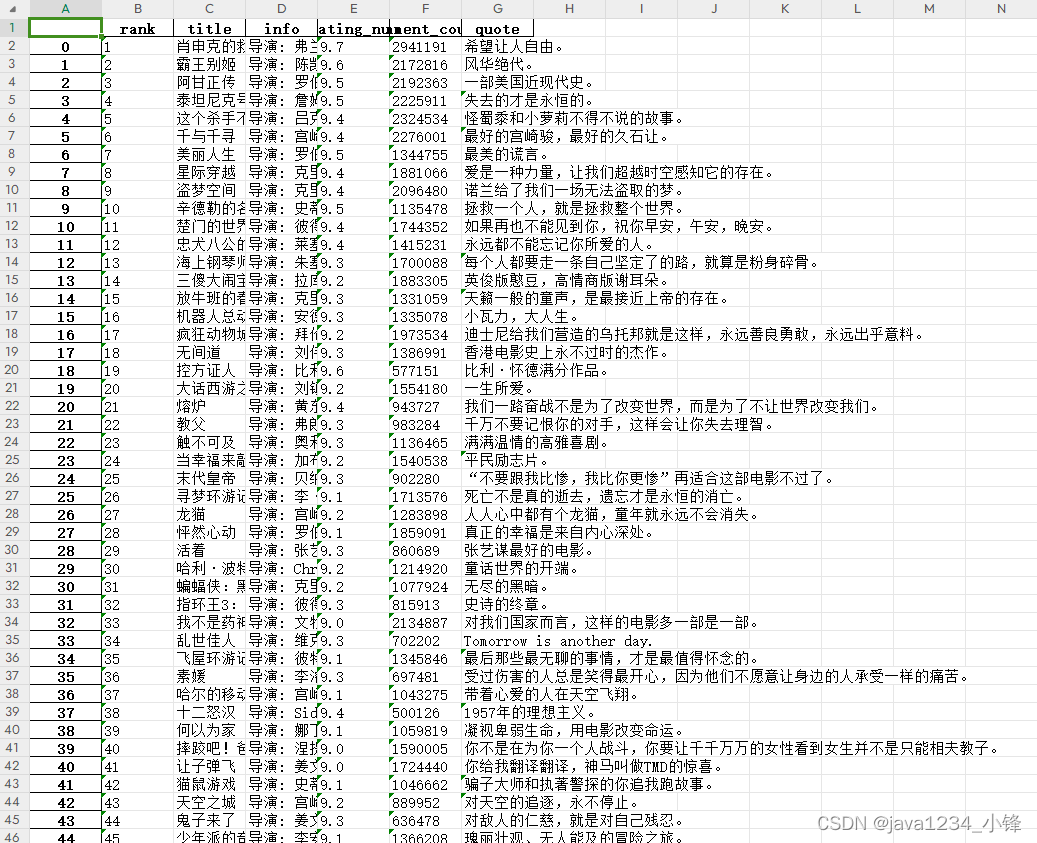
近日锋哥又卷了一波Python实战课程–批量爬取豆瓣电影排行信息,主要是巩固下Python爬虫基础
Python爬虫实战–批量爬取豆瓣电影排行信息 视频教程_哔哩哔哩_bilibiliPython爬虫实战–批量爬取豆瓣电影排行信息 视频教程作者:小锋老师官网:www.python222.com, 视频播放量 344、弹幕量 0、点赞数 13、投硬币枚数 7、收藏人数 18、转发人数 0, 视频作者 java1234官方, 作者简介 公众号:java1234 微信:java9266,相关视频:Python爬虫实战–批量爬取下载网易云音乐,Python爬虫实战–批量爬取美女图片网下载图片 视频教程,这个视频可能会得罪很多人..终极爬虫JS逆向教程!突破反爬虫防御的终极指南,从入门到实战,就没有爬不了的网站!,【Python爬虫教程】你敢学我就敢发!300集从入门到入狱(完整版)胆小勿学!全程干货无废话,学完即可兼职接单!,2024 一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium 【无废话版】,【Python爬虫】三分钟教你免费下载全网VIP音乐,音乐一键下载免费听,告别付费时代,小白也能学得会,附源码!,【Python爬虫】手把手教你爬取百度文库PPT文档,破解百度文库收费限制,下载PPT再也没花过钱!,【B站第一】清华大佬196小时讲完的Python入门学习教程!从小白到大神!整整300集,全干货无废话,学完即可就业!允许白嫖!!,【2023百度文库VIP文档PPT免费下载】Python白嫖百度文库付费VIP文档,破解百度文库收费限制,零基础白嫖教程!!!,【Python教程】一分钟轻松实现观影自由,教你用Python免费看电影,代码可分享 | Python爬虫教程![]() https://www.bilibili.com/video/BV1aN411u7o5/
https://www.bilibili.com/video/BV1aN411u7o5/

爬虫目标网站: